 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Homography Estimation with Coplanarity-Aware GAN
May 08, 2022

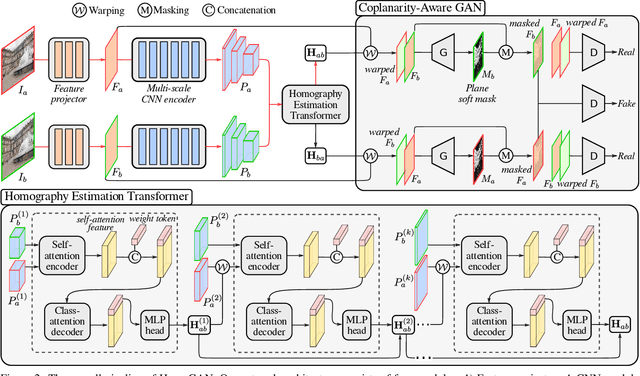

Estimating homography from an image pair is a fundamental problem in image alignment. Unsupervised learning methods have received increasing attention in this field due to their promising performance and label-free training. However, existing methods do not explicitly consider the problem of plane-induced parallax, which will make the predicted homography compromised on multiple planes. In this work, we propose a novel method HomoGAN to guide unsupervised homography estimation to focus on the dominant plane. First, a multi-scale transformer network is designed to predict homography from the feature pyramids of input images in a coarse-to-fine fashion. Moreover, we propose an unsupervised GAN to impose coplanarity constraint on the predicted homography, which is realized by using a generator to predict a mask of aligned regions, and then a discriminator to check if two masked feature maps are induced by a single homography. To validate the effectiveness of HomoGAN and its components, we conduct extensive experiments on a large-scale dataset, and the results show that our matching error is 22% lower than the previous SOTA method. Code is available at https://github.com/megvii-research/HomoGAN.
FINet: Dual Branches Feature Interaction for Partial-to-Partial Point Cloud Registration
Jun 07, 2021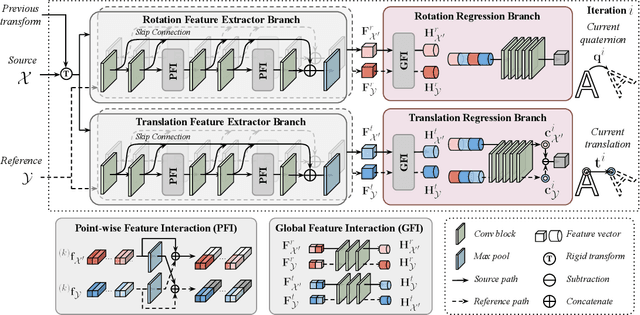
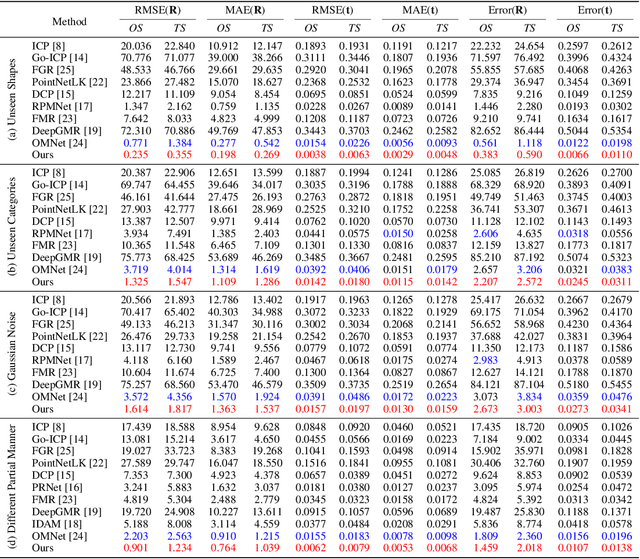
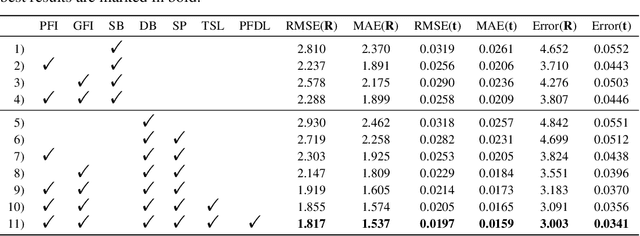
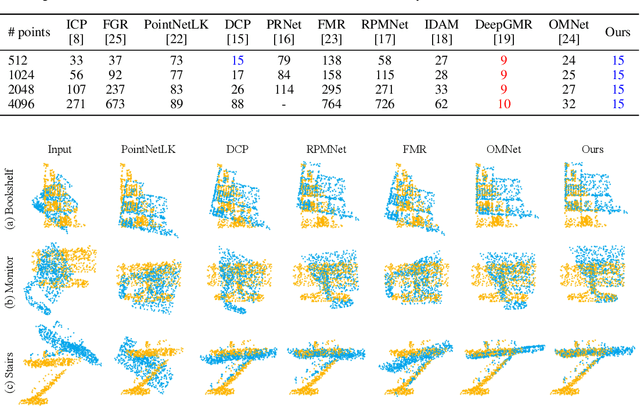
Data association is important in the point cloud registration. In this work, we propose to solve the partial-to-partial registration from a new perspective, by introducing feature interactions between the source and the reference clouds at the feature extraction stage, such that the registration can be realized without the explicit mask estimation or attentions for the overlapping detection as adopted previously. Specifically, we present FINet, a feature interaction-based structure with the capability to enable and strengthen the information associating between the inputs at multiple stages. To achieve this, we first split the features into two components, one for the rotation and one for the translation, based on the fact that they belong to different solution spaces, yielding a dual branches structure. Second, we insert several interaction modules at the feature extractor for the data association. Third, we propose a transformation sensitivity loss to obtain rotation-attentive and translation-attentive features. Experiments demonstrate that our method performs higher precision and robustness compared to the state-of-the-art traditional and learning-based methods.
Motion Basis Learning for Unsupervised Deep Homography Estimation with Subspace Projection
Mar 29, 2021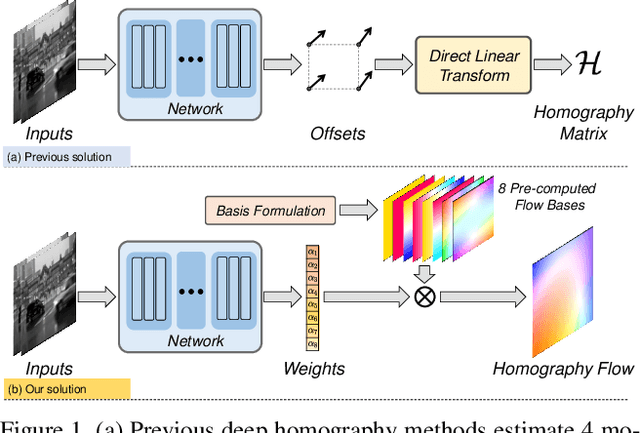
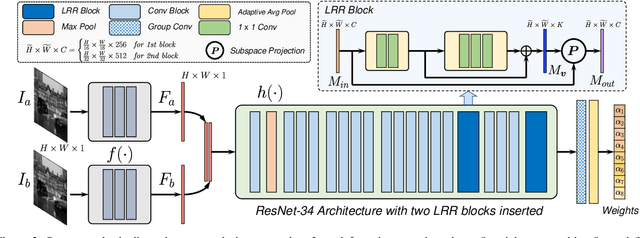

In this paper, we introduce a new framework for unsupervised deep homography estimation. Our contributions are 3 folds. First, unlike previous methods that regress 4 offsets for a homography, we propose a homography flow representation, which can be estimated by a weighted sum of 8 pre-defined homography flow bases. Second, considering a homography contains 8 Degree-of-Freedoms (DOFs) that is much less than the rank of the network features, we propose a Low Rank Representation (LRR) block that reduces the feature rank, so that features corresponding to the dominant motions are retained while others are rejected. Last, we propose a Feature Identity Loss (FIL) to enforce the learned image feature warp-equivariant, meaning that the result should be identical if the order of warp operation and feature extraction is swapped. With this constraint, the unsupervised optimization is achieved more effectively and more stable features are learned. Extensive experiments are conducted to demonstrate the effectiveness of all the newly proposed components, and results show our approach outperforms the state-of-the-art on the homography benchmark datasets both qualitatively and quantitatively.
OccInpFlow: Occlusion-Inpainting Optical Flow Estimation by Unsupervised Learning
Jun 30, 2020



Occlusion is an inevitable and critical problem in unsupervised optical flow learning. Existing methods either treat occlusions equally as non-occluded regions or simply remove them to avoid incorrectness. However, the occlusion regions can provide effective information for optical flow learning. In this paper, we present OccInpFlow, an occlusion-inpainting framework to make full use of occlusion regions. Specifically, a new appearance-flow network is proposed to inpaint occluded flows based on the image content. Moreover, a boundary warp is proposed to deal with occlusions caused by displacement beyond image border. We conduct experiments on multiple leading flow benchmark data sets such as Flying Chairs, KITTI and MPI-Sintel, which demonstrate that the performance is significantly improved by our proposed occlusion handling framework.
DeepMeshFlow: Content Adaptive Mesh Deformation for Robust Image Registration
Dec 11, 2019



Image alignment by mesh warps, such as meshflow, is a fundamental task which has been widely applied in various vision applications(e.g., multi-frame HDR/denoising, video stabilization). Traditional mesh warp methods detect and match image features, where the quality of alignment highly depends on the quality of image features. However, the image features are not robust in occurrence of low-texture and low-light scenes. Deep homography methods, on the other hand, are free from such problem by learning deep features for robust performance. However, a homography is limited to plane motions. In this work, we present a deep meshflow motion model, which takes two images as input and output a sparse motion field with motions located at mesh vertexes. The deep meshflow enjoys the merics of meshflow that can describe nonlinear motions while also shares advantage of deep homography that is robust against challenging textureless scenarios. In particular, a new unsupervised network structure is presented with content-adaptive capability. On one hand, the image content that cannot be aligned under mesh representation are rejected by our learned mask, similar to the RANSAC procedure. On the other hand, we learn multiple mesh resolutions, combining to a non-uniform mesh division. Moreover, a comprehensive dataset is presented, covering various scenes for training and testing. The comparison between both traditional mesh warp methods and deep based methods show the effectiveness of our deep meshflow motion model.