 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2021 Challenge on Burst Super-Resolution: Methods and Results
Jun 07, 2021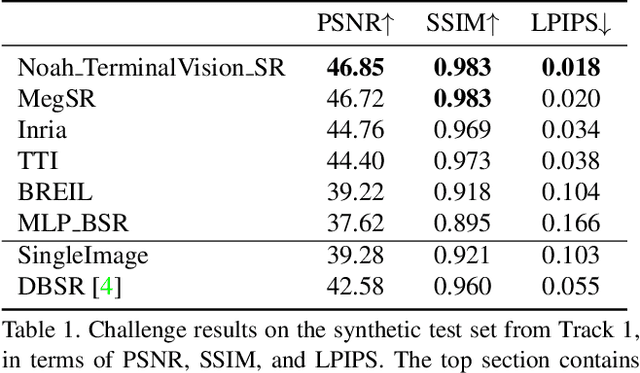

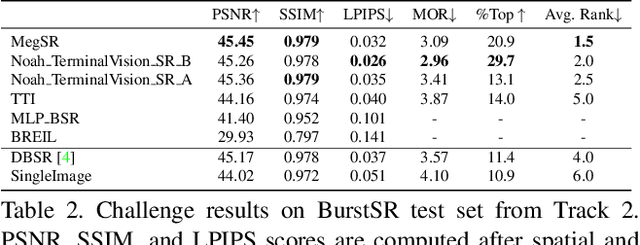

This paper reviews the NTIRE2021 challenge on burst super-resolution. Given a RAW noisy burst as input, the task in the challenge was to generate a clean RGB image with 4 times higher resolution. The challenge contained two tracks; Track 1 evaluating on synthetically generated data, and Track 2 using real-world bursts from mobile camera. In the final testing phase, 6 teams submitted results using a diverse set of solutions. The top-performing methods set a new state-of-the-art for the burst super-resolution task.
D2C-SR: A Divergence to Convergence Approach for Image Super-Resolution
Mar 26, 2021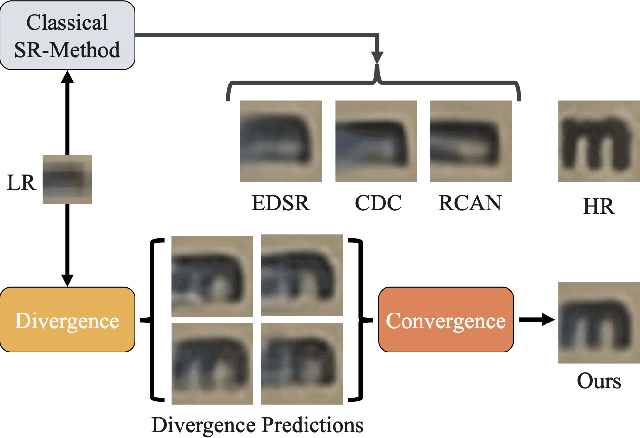
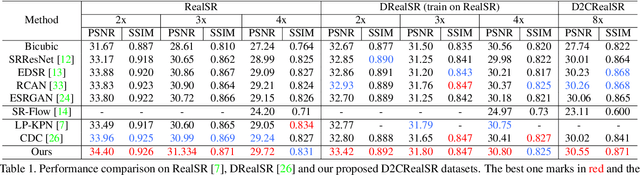
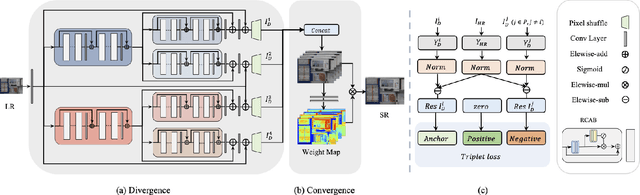
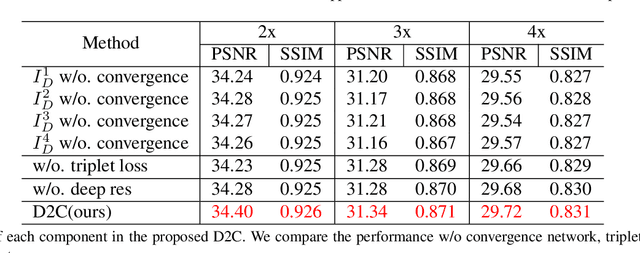
In this paper, we present D2C-SR, a novel framework for the task of image super-resolution(SR). As an ill-posed problem, the key challenge for super-resolution related tasks is there can be multiple predictions for a given low-resolution input. Most classical methods and early deep learning based approaches ignored this fundamental fact and modeled this problem as a deterministic processing which often lead to unsatisfactory results. Inspired by recent works like SRFlow, we tackle this problem in a semi-probabilistic manner and propose a two-stage pipeline: a divergence stage is used to learn the distribution of underlying high-resolution outputs in a discrete form, and a convergence stage is followed to fuse the learned predictions into a final output. More specifically, we propose a tree-based structure deep network, where each branch is designed to learn a possible high-resolution prediction. At the divergence stage, each branch is trained separately to fit ground truth, and a triple loss is used to enforce the outputs from different branches divergent. Subsequently, we add a fuse module to combine the multiple predictions as the outputs from the first stage can be sub-optimal. The fuse module can be trained to converge w.r.t the final high-resolution image in an end-to-end manner. We conduct evaluations on several benchmarks, including a new proposed dataset with 8x upscaling factor. Our experiments demonstrate that D2C-SR can achieve state-of-the-art performance on PSNR and SSIM, with a significantly less computational cost.
DeepMeshFlow: Content Adaptive Mesh Deformation for Robust Image Registration
Dec 11, 2019



Image alignment by mesh warps, such as meshflow, is a fundamental task which has been widely applied in various vision applications(e.g., multi-frame HDR/denoising, video stabilization). Traditional mesh warp methods detect and match image features, where the quality of alignment highly depends on the quality of image features. However, the image features are not robust in occurrence of low-texture and low-light scenes. Deep homography methods, on the other hand, are free from such problem by learning deep features for robust performance. However, a homography is limited to plane motions. In this work, we present a deep meshflow motion model, which takes two images as input and output a sparse motion field with motions located at mesh vertexes. The deep meshflow enjoys the merics of meshflow that can describe nonlinear motions while also shares advantage of deep homography that is robust against challenging textureless scenarios. In particular, a new unsupervised network structure is presented with content-adaptive capability. On one hand, the image content that cannot be aligned under mesh representation are rejected by our learned mask, similar to the RANSAC procedure. On the other hand, we learn multiple mesh resolutions, combining to a non-uniform mesh division. Moreover, a comprehensive dataset is presented, covering various scenes for training and testing. The comparison between both traditional mesh warp methods and deep based methods show the effectiveness of our deep meshflow motion model.
Content-Aware Unsupervised Deep Homography Estimation
Sep 12, 2019

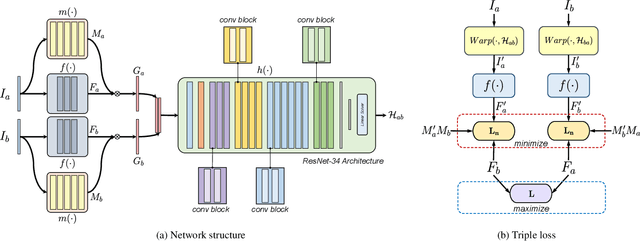
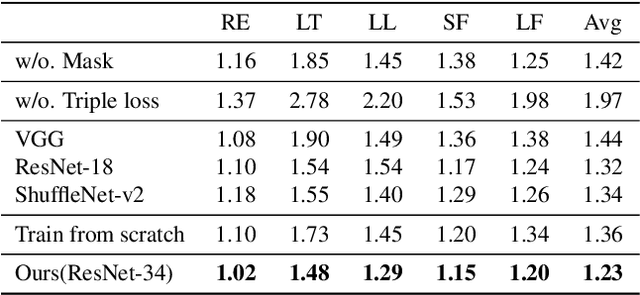
Robust homography estimation between two images is a fundamental task which has been widely applied to various vision applications. Traditional feature based methods often detect image features and fit a homography according to matched features with RANSAC outlier removal. However, the quality of homography heavily relies on the quality of image features, which are prone to errors with respect to low light and low texture images. On the other hand, previous deep homography approaches either synthesize images for supervised learning or adopt aerial images for unsupervised learning, both ignoring the importance of depth disparities in homography estimation. Moreover, they treat the image content equally, including regions of dynamic objects and near-range foregrounds, which further decreases the quality of estimation. In this work, to overcome such problems, we propose an unsupervised deep homography method with a new architecture design. We learn a mask during the estimation to reject outlier regions. In addition, we calculate loss with respect to our learned deep features instead of directly comparing the image contents as did previously. Moreover, a comprehensive dataset is presented, covering both regular and challenging cases, such as poor textures and non-planar interferences. The effectiveness of our method is validated through comparisons with both feature-based and previous deep-based methods. Code will be soon available at Github.