 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIPNet: Efficiency Distillation and Iterative Pruning for Image Super-Resolution
Apr 14, 2023


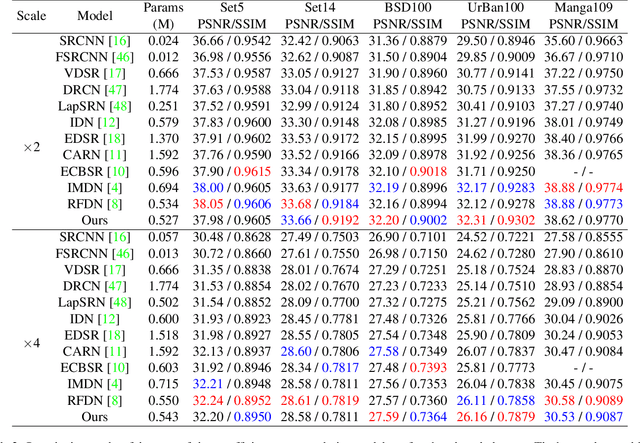
Efficient deep learning-based approaches have achieved remarkable performance in single image super-resolution. However, recent studies on efficient super-resolution have mainly focused on reducing the number of parameters and floating-point operations through various network designs. Although these methods can decrease the number of parameters and floating-point operations, they may not necessarily reduce actual running time. To address this issue, we propose a novel multi-stage lightweight network boosting method, which can enable lightweight networks to achieve outstanding performance. Specifically, we leverage enhanced high-resolution output as additional supervision to improve the learning ability of lightweight student networks. Upon convergence of the student network, we further simplify our network structure to a more lightweight level using reparameterization techniques and iterative network pruning. Meanwhile, we adopt an effective lightweight network training strategy that combines multi-anchor distillation and progressive learning, enabling the lightweight network to achieve outstanding performance. Ultimately, our proposed method achieves the fastest inference time among all participants in the NTIRE 2023 efficient super-resolution challenge while maintaining competitive super-resolution performance. Additionally, extensive experiments are conducted to demonstrate the effectiveness of the proposed components. The results show that our approach achieves comparable performance in representative dataset DIV2K, both qualitatively and quantitatively, with faster inference and fewer number of network parameters.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
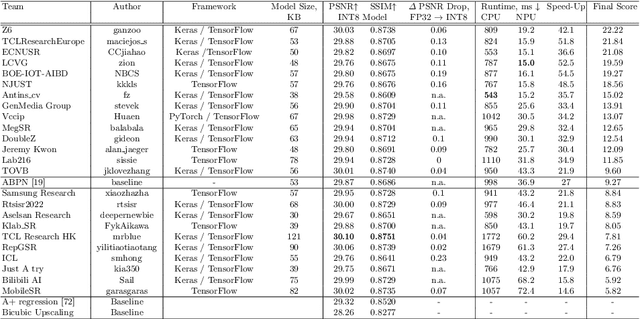
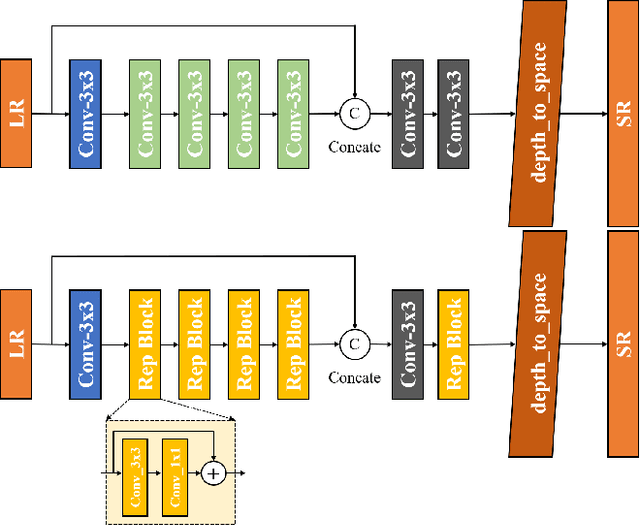
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
Fast Nearest Convolution for Real-Time Efficient Image Super-Resolution
Aug 24, 2022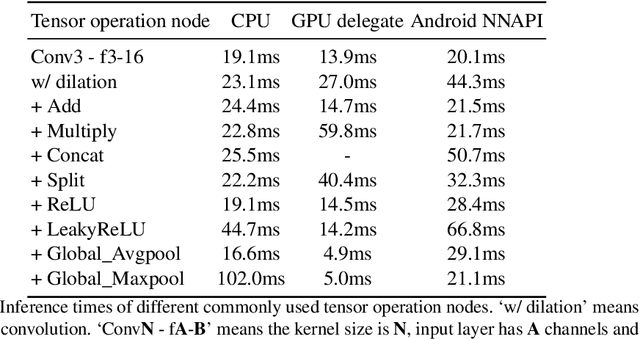
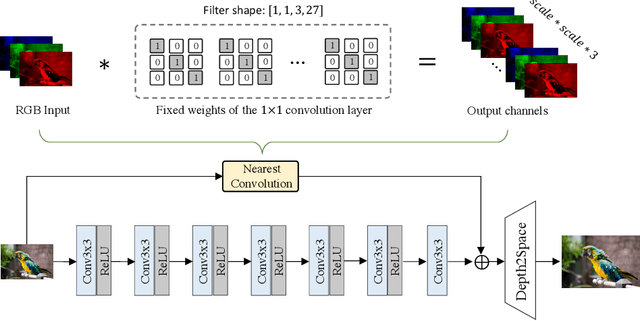
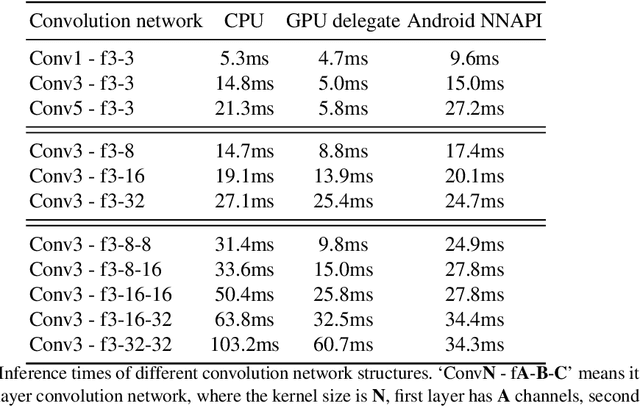

Deep learning-based single image super-resolution (SISR) approaches have drawn much attention and achieved remarkable success on modern advanced GPUs. However, most state-of-the-art methods require a huge number of parameters, memories, and computational resources, which usually show inferior inference times when applying them to current mobile device CPUs/NPUs. In this paper, we propose a simple plain convolution network with a fast nearest convolution module (NCNet), which is NPU-friendly and can perform a reliable super-resolution in real-time. The proposed nearest convolution has the same performance as the nearest upsampling but is much faster and more suitable for Android NNAPI. Our model can be easily deployed on mobile devices with 8-bit quantization and is fully compatible with all major mobile AI accelerators. Moreover, we conduct comprehensive experiments on different tensor operations on a mobile device to illustrate the efficiency of our network architecture. Our NCNet is trained and validated on the DIV2K 3x dataset, and the comparison with other efficient SR methods demonstrated that the NCNet can achieve high fidelity SR results while using fewer inference times. Our codes and pretrained models are publicly available at \url{https://github.com/Algolzw/NCNet}.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022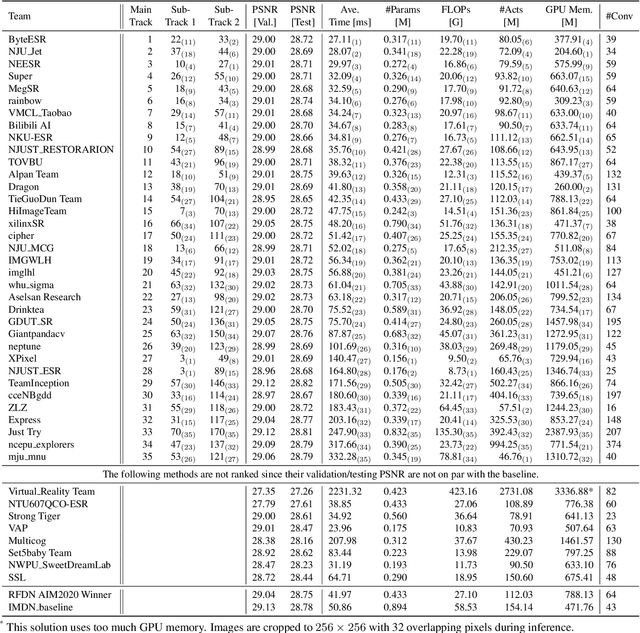
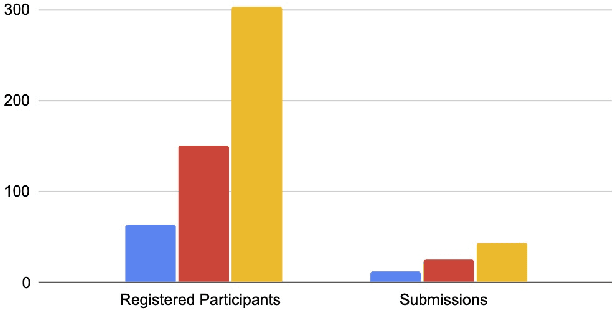
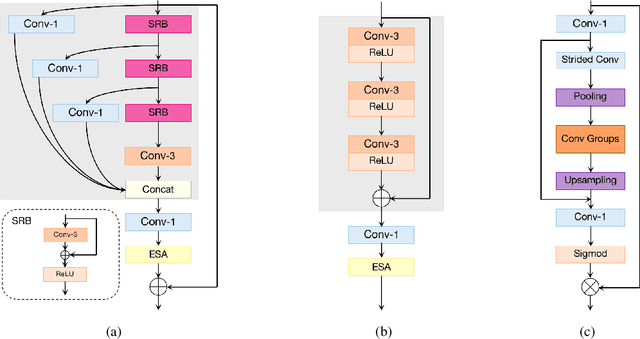
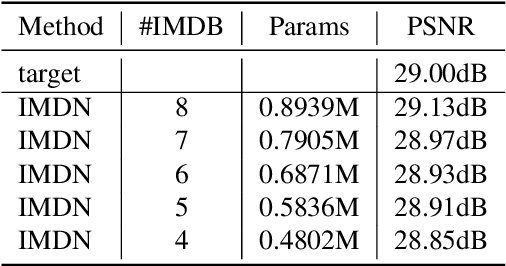
This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
BSRT: Improving Burst Super-Resolution with Swin Transformer and Flow-Guided Deformable Alignment
Apr 22, 2022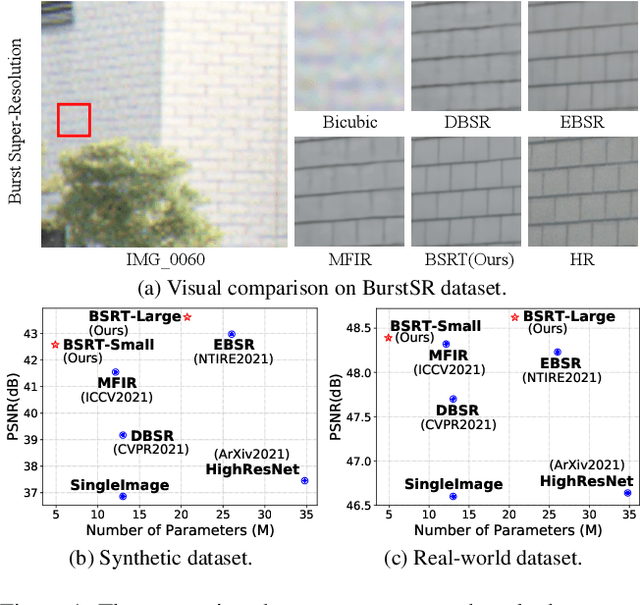
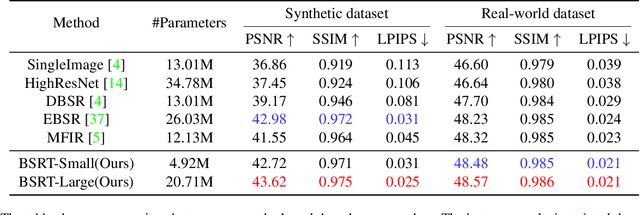
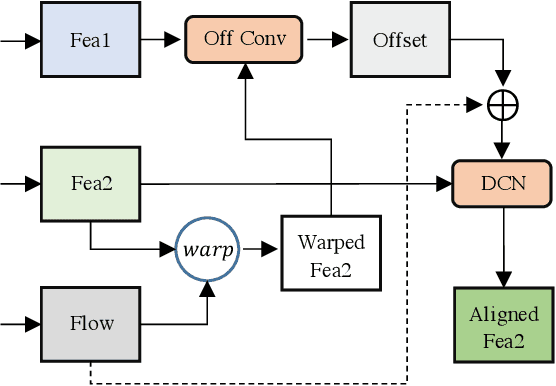
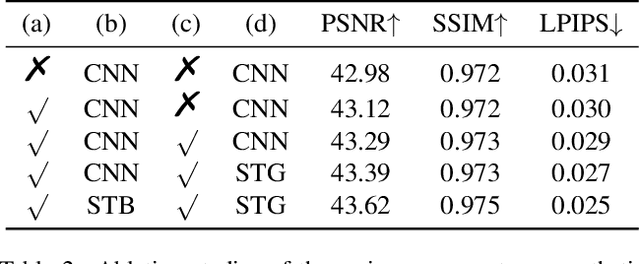
This work addresses the Burst Super-Resolution (BurstSR) task using a new architecture, which requires restoring a high-quality image from a sequence of noisy, misaligned, and low-resolution RAW bursts. To overcome the challenges in BurstSR, we propose a Burst Super-Resolution Transformer (BSRT), which can significantly improve the capability of extracting inter-frame information and reconstruction. To achieve this goal, we propose a Pyramid Flow-Guided Deformable Convolution Network (Pyramid FG-DCN) and incorporate Swin Transformer Blocks and Groups as our main backbone. More specifically, we combine optical flows and deformable convolutions, hence our BSRT can handle misalignment and aggregate the potential texture information in multi-frames more efficiently. In addition, our Transformer-based structure can capture long-range dependency to further improve the performance. The evaluation on both synthetic and real-world tracks demonstrates that our approach achieves a new state-of-the-art in BurstSR task. Further, our BSRT wins the championship in the NTIRE2022 Burst Super-Resolution Challenge.
Deep Constrained Least Squares for Blind Image Super-Resolution
Feb 15, 2022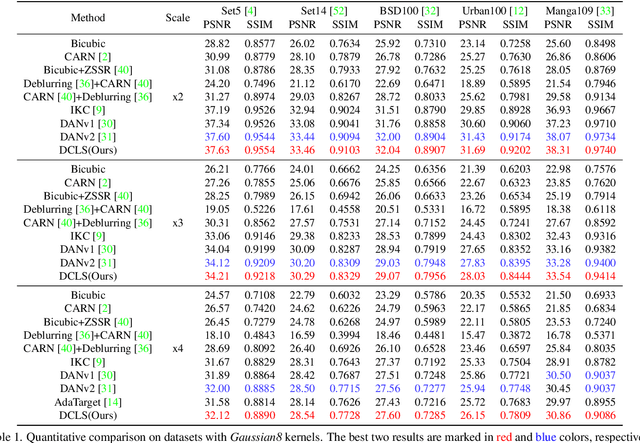

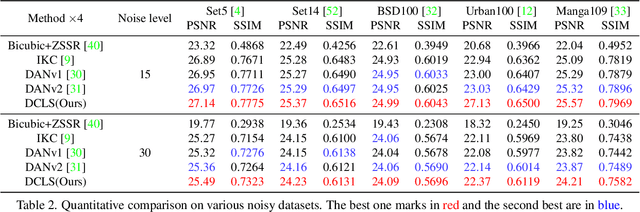
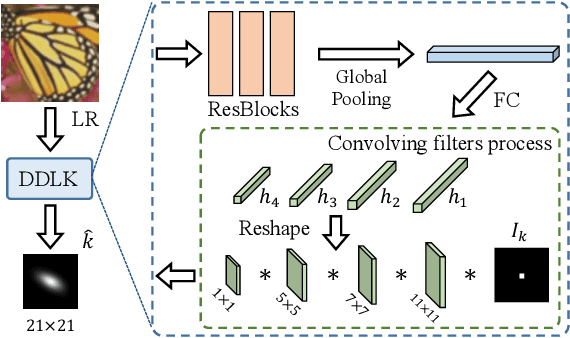
In this paper, we tackle the problem of blind image super-resolution(SR) with a reformulated degradation model and two novel modules. Following the common practices of blind SR, our method proposes to improve both the kernel estimation as well as the kernel based high resolution image restoration. To be more specific, we first reformulate the degradation model such that the deblurring kernel estimation can be transferred into the low resolution space. On top of this, we introduce a dynamic deep linear filter module. Instead of learning a fixed kernel for all images, it can adaptively generate deblurring kernel weights conditional on the input and yields more robust kernel estimation. Subsequently, a deep constrained least square filtering module is applied to generate clean features based on the reformulation and estimated kernel. The deblurred feature and the low input image feature are then fed into a dual-path structured SR network and restore the final high resolution result. To evaluate our method, we further conduct evaluations on several benchmarks, including Gaussian8 and DIV2KRK. Our experiments demonstrate that the proposed method achieves better accuracy and visual improvements against state-of-the-art methods.
NTIRE 2021 Challenge on Burst Super-Resolution: Methods and Results
Jun 07, 2021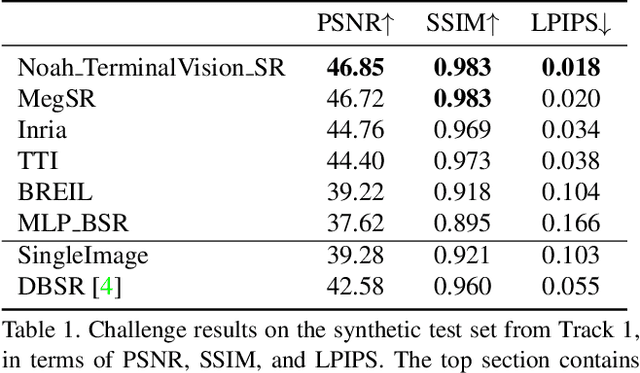

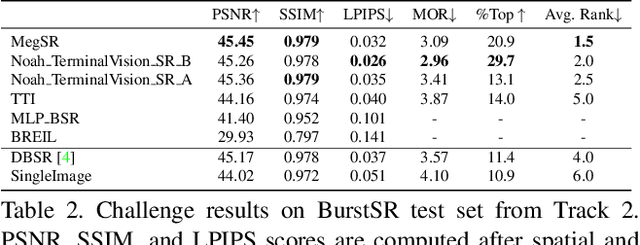

This paper reviews the NTIRE2021 challenge on burst super-resolution. Given a RAW noisy burst as input, the task in the challenge was to generate a clean RGB image with 4 times higher resolution. The challenge contained two tracks; Track 1 evaluating on synthetically generated data, and Track 2 using real-world bursts from mobile camera. In the final testing phase, 6 teams submitted results using a diverse set of solutions. The top-performing methods set a new state-of-the-art for the burst super-resolution task.
D2C-SR: A Divergence to Convergence Approach for Image Super-Resolution
Mar 26, 2021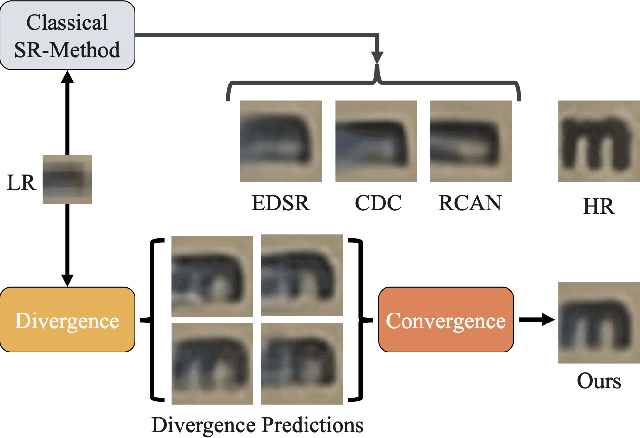
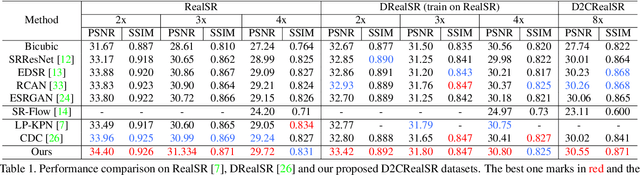
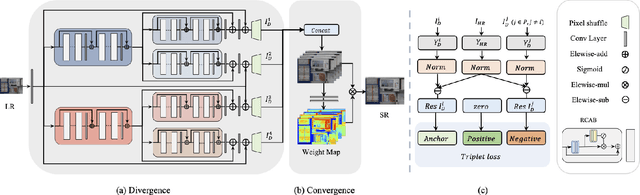
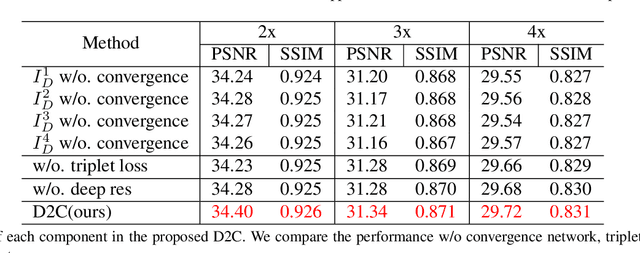
In this paper, we present D2C-SR, a novel framework for the task of image super-resolution(SR). As an ill-posed problem, the key challenge for super-resolution related tasks is there can be multiple predictions for a given low-resolution input. Most classical methods and early deep learning based approaches ignored this fundamental fact and modeled this problem as a deterministic processing which often lead to unsatisfactory results. Inspired by recent works like SRFlow, we tackle this problem in a semi-probabilistic manner and propose a two-stage pipeline: a divergence stage is used to learn the distribution of underlying high-resolution outputs in a discrete form, and a convergence stage is followed to fuse the learned predictions into a final output. More specifically, we propose a tree-based structure deep network, where each branch is designed to learn a possible high-resolution prediction. At the divergence stage, each branch is trained separately to fit ground truth, and a triple loss is used to enforce the outputs from different branches divergent. Subsequently, we add a fuse module to combine the multiple predictions as the outputs from the first stage can be sub-optimal. The fuse module can be trained to converge w.r.t the final high-resolution image in an end-to-end manner. We conduct evaluations on several benchmarks, including a new proposed dataset with 8x upscaling factor. Our experiments demonstrate that D2C-SR can achieve state-of-the-art performance on PSNR and SSIM, with a significantly less computational cost.