 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2C-SR: A Divergence to Convergence Approach for Image Super-Resolution
Paper and Code
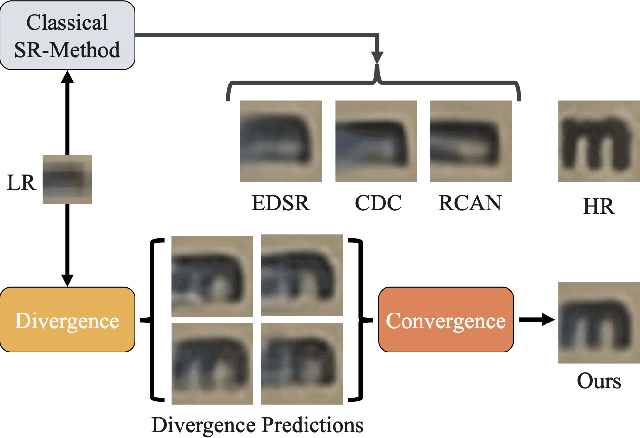
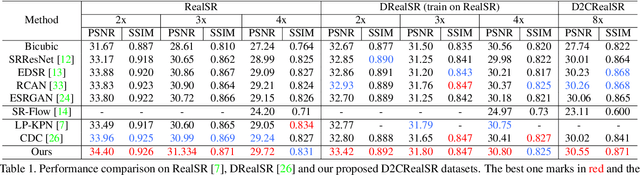
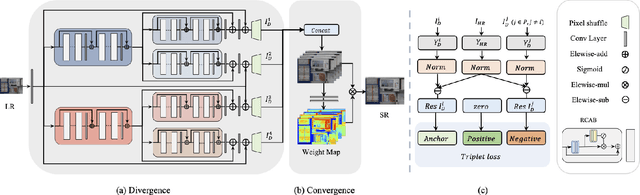
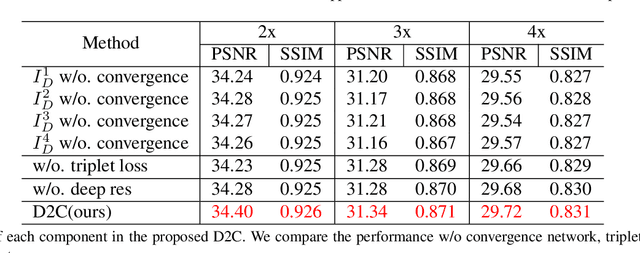
In this paper, we present D2C-SR, a novel framework for the task of image super-resolution(SR). As an ill-posed problem, the key challenge for super-resolution related tasks is there can be multiple predictions for a given low-resolution input. Most classical methods and early deep learning based approaches ignored this fundamental fact and modeled this problem as a deterministic processing which often lead to unsatisfactory results. Inspired by recent works like SRFlow, we tackle this problem in a semi-probabilistic manner and propose a two-stage pipeline: a divergence stage is used to learn the distribution of underlying high-resolution outputs in a discrete form, and a convergence stage is followed to fuse the learned predictions into a final output. More specifically, we propose a tree-based structure deep network, where each branch is designed to learn a possible high-resolution prediction. At the divergence stage, each branch is trained separately to fit ground truth, and a triple loss is used to enforce the outputs from different branches divergent. Subsequently, we add a fuse module to combine the multiple predictions as the outputs from the first stage can be sub-optimal. The fuse module can be trained to converge w.r.t the final high-resolution image in an end-to-end manner. We conduct evaluations on several benchmarks, including a new proposed dataset with 8x upscaling factor. Our experiments demonstrate that D2C-SR can achieve state-of-the-art performance on PSNR and SSIM, with a significantly less computational cost.