 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Monocular View Synthesis in Less Than a Second
Dec 11, 2025We present SHARP, an approach to photorealistic view synthesis from a single image. Given a single photograph, SHARP regresses the parameters of a 3D Gaussian representation of the depicted scene. This is done in less than a second on a standard GPU via a single feedforward pass through a neural network. The 3D Gaussian representation produced by SHARP can then be rendered in real time, yielding high-resolution photorealistic images for nearby views. The representation is metric, with absolute scale, supporting metric camera movements. Experimental results demonstrate that SHARP delivers robust zero-shot generalization across datasets. It sets a new state of the art on multiple datasets, reducing LPIPS by 25-34% and DISTS by 21-43% versus the best prior model, while lowering the synthesis time by three orders of magnitude. Code and weights are provided at https://github.com/apple/ml-sharp
Fine Dense Alignment of Image Bursts through Camera Pose and Depth Estimation
Dec 08, 2023This paper introduces a novel approach to the fine alignment of images in a burst captured by a handheld camera. In contrast to traditional techniques that estimate two-dimensional transformations between frame pairs or rely on discrete correspondences, the proposed algorithm establishes dense correspondences by optimizing both the camera motion and surface depth and orientation at every pixel. This approach improves alignment, particularly in scenarios with parallax challenges. Extensive experiments with synthetic bursts featuring small and even tiny baselines demonstrate that it outperforms the best optical flow methods available today in this setting, without requiring any training. Beyond enhanced alignment, our method opens avenues for tasks beyond simple image restoration, such as depth estimation and 3D reconstruction, as supported by promising preliminary results. This positions our approach as a versatile tool for various burst image processing applications.
High Dynamic Range and Super-Resolution from Raw Image Bursts
Jul 29, 2022
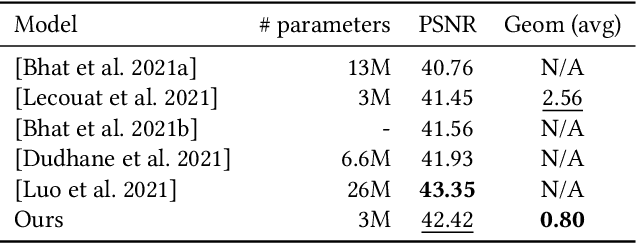
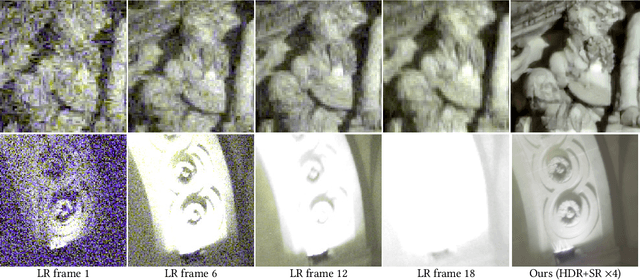
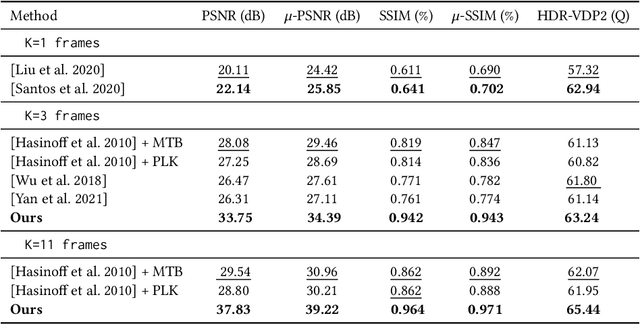
Photographs captured by smartphones and mid-range cameras have limited spatial resolution and dynamic range, with noisy response in underexposed regions and color artefacts in saturated areas. This paper introduces the first approach (to the best of our knowledge) to the reconstruction of high-resolution, high-dynamic range color images from raw photographic bursts captured by a handheld camera with exposure bracketing. This method uses a physically-accurate model of image formation to combine an iterative optimization algorithm for solving the corresponding inverse problem with a learned image representation for robust alignment and a learned natural image prior. The proposed algorithm is fast, with low memory requirements compared to state-of-the-art learning-based approaches to image restoration, and features that are learned end to end from synthetic yet realistic data. Extensive experiments demonstrate its excellent performance with super-resolution factors of up to $\times 4$ on real photographs taken in the wild with hand-held cameras, and high robustness to low-light conditions, noise, camera shake, and moderate object motion.
NTIRE 2021 Challenge on Burst Super-Resolution: Methods and Results
Jun 07, 2021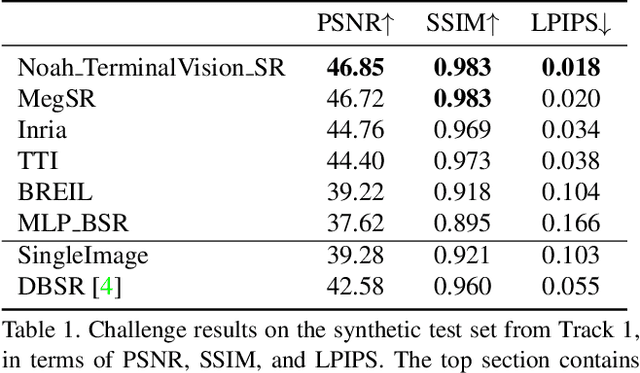

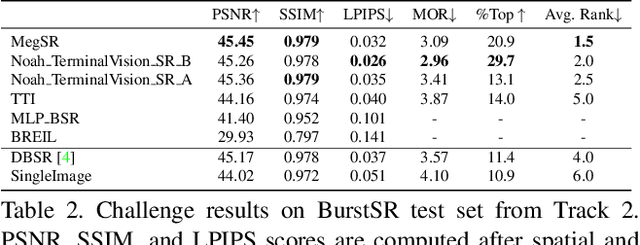

This paper reviews the NTIRE2021 challenge on burst super-resolution. Given a RAW noisy burst as input, the task in the challenge was to generate a clean RGB image with 4 times higher resolution. The challenge contained two tracks; Track 1 evaluating on synthetically generated data, and Track 2 using real-world bursts from mobile camera. In the final testing phase, 6 teams submitted results using a diverse set of solutions. The top-performing methods set a new state-of-the-art for the burst super-resolution task.
Aliasing is your Ally: End-to-End Super-Resolution from Raw Image Bursts
Apr 13, 2021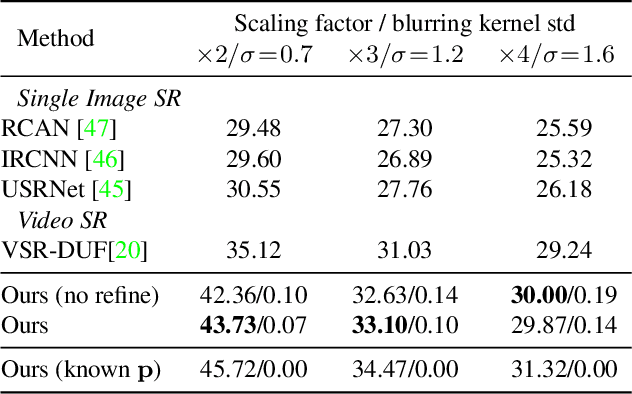

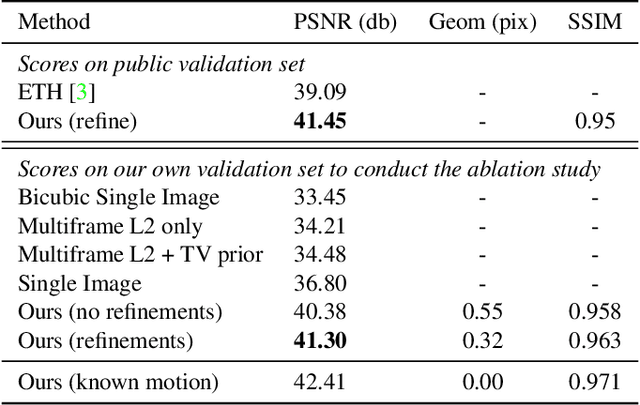

This presentation addresses the problem of reconstructing a high-resolution image from multiple lower-resolution snapshots captured from slightly different viewpoints in space and time. Key challenges for solving this problem include (i) aligning the input pictures with sub-pixel accuracy, (ii) handling raw (noisy) images for maximal faithfulness to native camera data, and (iii) designing/learning an image prior (regularizer) well suited to the task. We address these three challenges with a hybrid algorithm building on the insight from Wronski et al. that aliasing is an ally in this setting, with parameters that can be learned end to end, while retaining the interpretability of classical approaches to inverse problems. The effectiveness of our approach is demonstrated on synthetic and real image bursts, setting a new state of the art on several benchmarks and delivering excellent qualitative results on real raw bursts captured by smartphones and prosumer cameras.
Designing and Learning Trainable Priors with Non-Cooperative Games
Jun 26, 2020
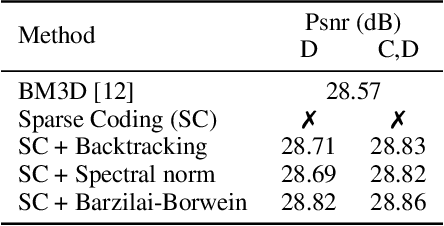
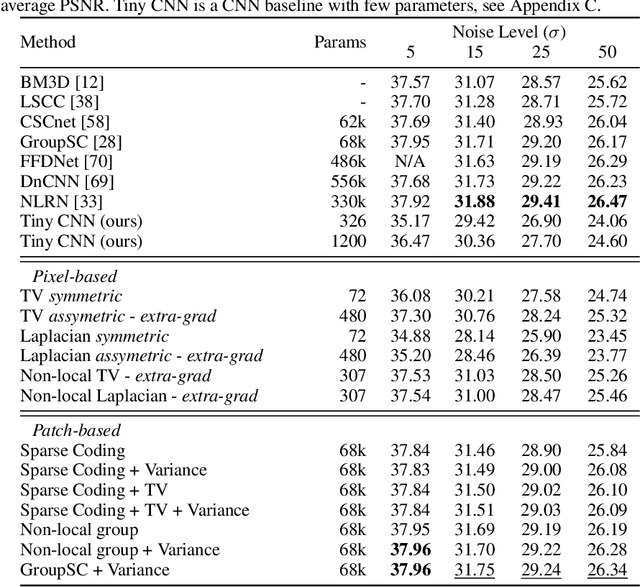
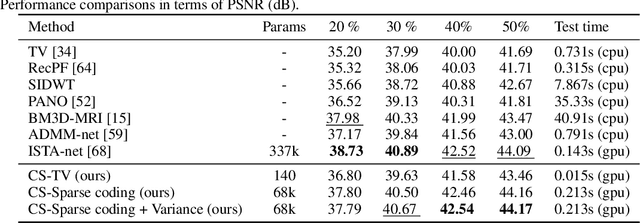
We introduce a general framework for designing and learning neural networks whose forward passes can be interpreted as solving convex optimization problems, and whose architectures are derived from an optimization algorithm. We focus on non-cooperative convex games, solved by local agents represented by the nodes of a graph and interacting through regularization functions. This approach is appealing for solving imaging problems, as it allows the use of classical image priors within deep models that are trainable end to end. The priors used in this presentation include variants of total variation, Laplacian regularization, sparse coding on learned dictionaries, and non-local self similarities. Our models are parameter efficient and fully interpretable, and our experiments demonstrate their effectiveness on a large diversity of tasks ranging from image denoising and compressed sensing for fMRI to dense stereo matching.
Revisiting Non Local Sparse Models for Image Restoration
Jan 28, 2020


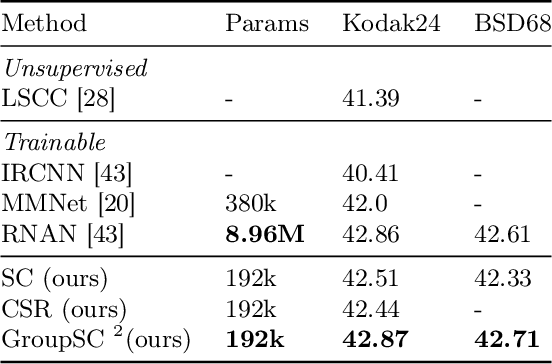
We propose a differentiable algorithm for image restoration inspired by the success of sparse models and self-similarity priors for natural images. Our approach builds upon the concept of joint sparsity between groups of similar image patches, and we show how this simple idea can be implemented in a differentiable architecture, allowing end-to-end training. The algorithm has the advantage of being interpretable, performing sparse decompositions of image patches, while being more parameter efficient than recent deep learning methods. We evaluate our algorithm on grayscale and color denoising, where we achieve competitive results, and on demoisaicking, where we outperform the most recent state-of-the-art deep learning model with 47 times less parameters and a much shallower architecture.
Venn GAN: Discovering Commonalities and Particularities of Multiple Distributions
Feb 09, 2019We propose a GAN design which models multiple distributions effectively and discovers their commonalities and particularities. Each data distribution is modeled with a mixture of $K$ generator distributions. As the generators are partially shared between the modeling of different true data distributions, shared ones captures the commonality of the distributions, while non-shared ones capture unique aspects of them. We show the effectiveness of our method on various datasets (MNIST, Fashion MNIST, CIFAR-10, Omniglot, CelebA) with compelling results.
Semi-Supervised Deep Learning for Abnormality Classification in Retinal Images
Dec 19, 2018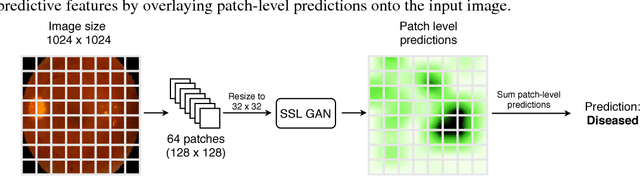


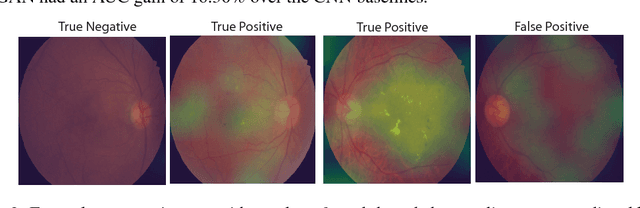
Supervised deep learning algorithms have enabled significant performance gains in medical image classification tasks. But these methods rely on large labeled datasets that require resource-intensive expert annotation. Semi-supervised generative adversarial network (GAN) approaches offer a means to learn from limited labeled data alongside larger unlabeled datasets, but have not been applied to discern fine-scale, sparse or localized features that define medical abnormalities. To overcome these limitations, we propose a patch-based semi-supervised learning approach and evaluate performance on classification of diabetic retinopathy from funduscopic images. Our semi-supervised approach achieves high AUC with just 10-20 labeled training images, and outperforms the supervised baselines by upto 15% when less than 30% of the training dataset is labeled. Further, our method implicitly enables interpretation of the SSL predictions. As this approach enables good accuracy, resolution and interpretability with lower annotation burden, it sets the pathway for scalable applications of deep learning in clinical imaging.
Adversarially Learned Anomaly Detection
Dec 06, 2018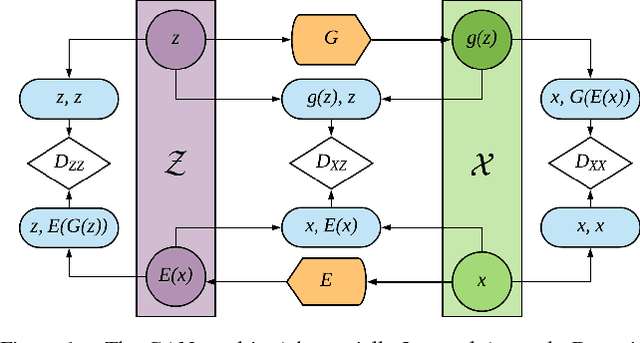
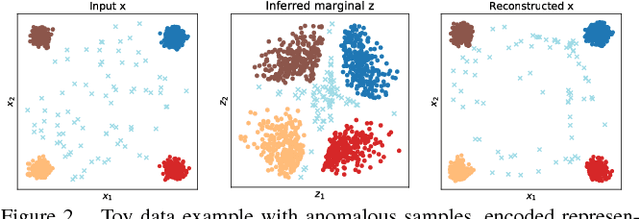
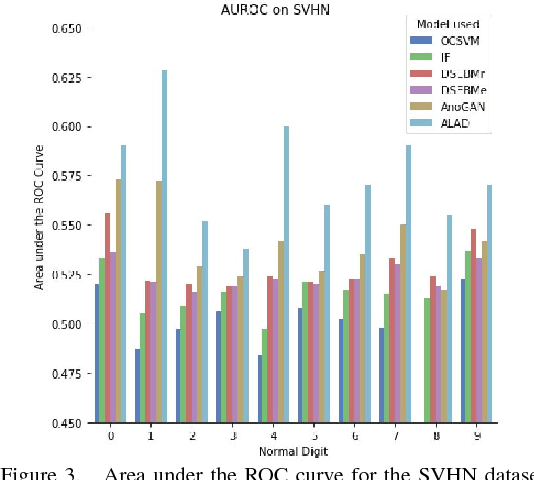
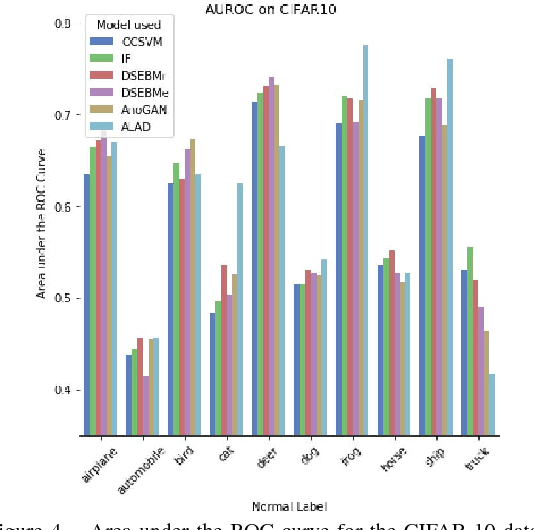
Anomaly detection is a significant and hence well-studied problem. However, developing effective anomaly detection methods for complex and high-dimensional data remains a challenge. As Generative Adversarial Networks (GANs) are able to model the complex high-dimensional distributions of real-world data, they offer a promising approach to address this challenge. In this work, we propose an anomaly detection method, Adversarially Learned Anomaly Detection (ALAD) based on bi-directional GANs, that derives adversarially learned features for the anomaly detection task. ALAD then uses reconstruction errors based on these adversarially learned features to determine if a data sample is anomalous. ALAD builds on recent advances to ensure data-space and latent-space cycle-consistencies and stabilize GAN training, which results in significantly improved anomaly detection performance. ALAD achieves state-of-the-art performance on a range of image and tabular datasets while being several hundred-fold faster at test time than the only published GAN-based method.