 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep histological synthesis from mass spectrometry imaging for multimodal registration
Jun 05, 2025
Registration of histological and mass spectrometry imaging (MSI) allows for more precise identification of structural changes and chemical interactions in tissue. With histology and MSI having entirely different image formation processes and dimensionalities, registration of the two modalities remains an ongoing challenge. This work proposes a solution that synthesises histological images from MSI, using a pix2pix model, to effectively enable unimodal registration. Preliminary results show promising synthetic histology images with limited artifacts, achieving increases in mutual information (MI) and structural similarity index measures (SSIM) of +0.924 and +0.419, respectively, compared to a baseline U-Net model. Our source code is available on GitHub: https://github.com/kimberley/MIUA2025.
Pushing the limits of cell segmentation models for imaging mass cytometry
Feb 06, 2024



Imaging mass cytometry (IMC) is a relatively new technique for imaging biological tissue at subcellular resolution. In recent years, learning-based segmentation methods have enabled precise quantification of cell type and morphology, but typically rely on large datasets with fully annotated ground truth (GT) labels. This paper explores the effects of imperfect labels on learning-based segmentation models and evaluates the generalisability of these models to different tissue types. Our results show that removing 50% of cell annotations from GT masks only reduces the dice similarity coefficient (DSC) score to 0.874 (from 0.889 achieved by a model trained on fully annotated GT masks). This implies that annotation time can in fact be reduced by at least half without detrimentally affecting performance. Furthermore, training our single-tissue model on imperfect labels only decreases DSC by 0.031 on an unseen tissue type compared to its multi-tissue counterpart, with negligible qualitative differences in segmentation. Additionally, bootstrapping the worst-performing model (with 5% of cell annotations) a total of ten times improves its original DSC score of 0.720 to 0.829. These findings imply that less time and work can be put into the process of producing comparable segmentation models; this includes eliminating the need for multiple IMC tissue types during training, whilst also providing the potential for models with very few labels to improve on themselves. Source code is available on GitHub: https://github.com/kimberley/ISBI2024.
DeepVerge: Classification of Roadside Verge Biodiversity and Conservation Potential
Jun 09, 2022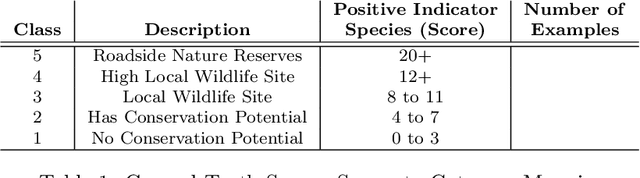
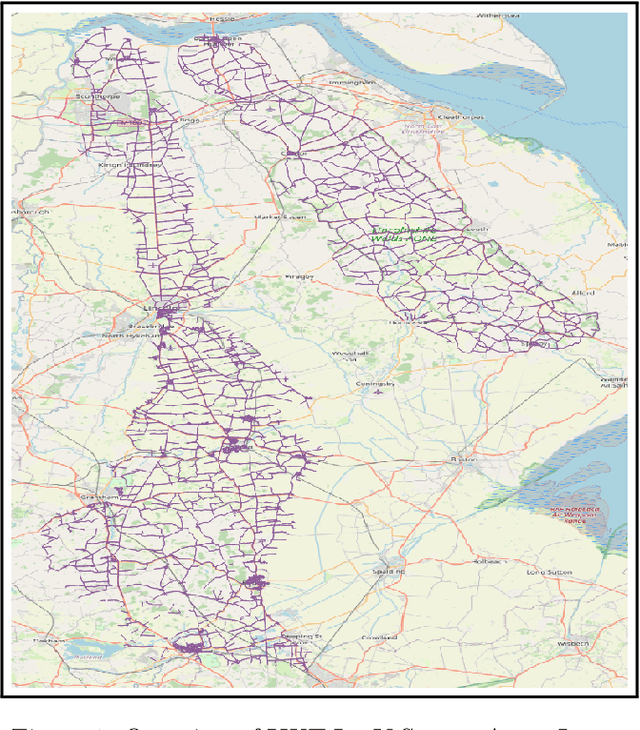

Open space grassland is being increasingly farmed or built upon, leading to a ramping up of conservation efforts targeting roadside verges. Approximately half of all UK grassland species can be found along the country's 500,000 km of roads, with some 91 species either threatened or near threatened. Careful management of these "wildlife corridors" is therefore essential to preventing species extinction and maintaining biodiversity in grassland habitats. Wildlife trusts have often enlisted the support of volunteers to survey roadside verges and identify new "Local Wildlife Sites" as areas of high conservation potential. Using volunteer survey data from 3,900 km of roadside verges alongside publicly available street-view imagery, we present DeepVerge; a deep learning-based method that can automatically survey sections of roadside verges by detecting the presence of positive indicator species. Using images and ground truth survey data from the rural county of Lincolnshire, DeepVerge achieved a mean accuracy of 88%. Such a method may be used by local authorities to identify new local wildlife sites, and aid management and environmental planning in line with legal and government policy obligations, saving thousands of hours of manual labour.
Dual-stream spatiotemporal networks with feature sharing for monitoring animals in the home cage
Jun 01, 2022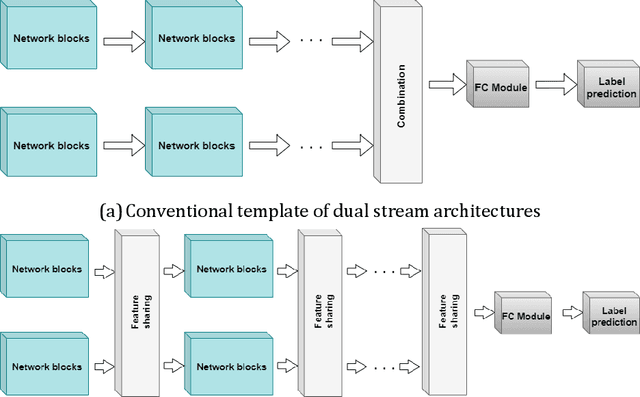
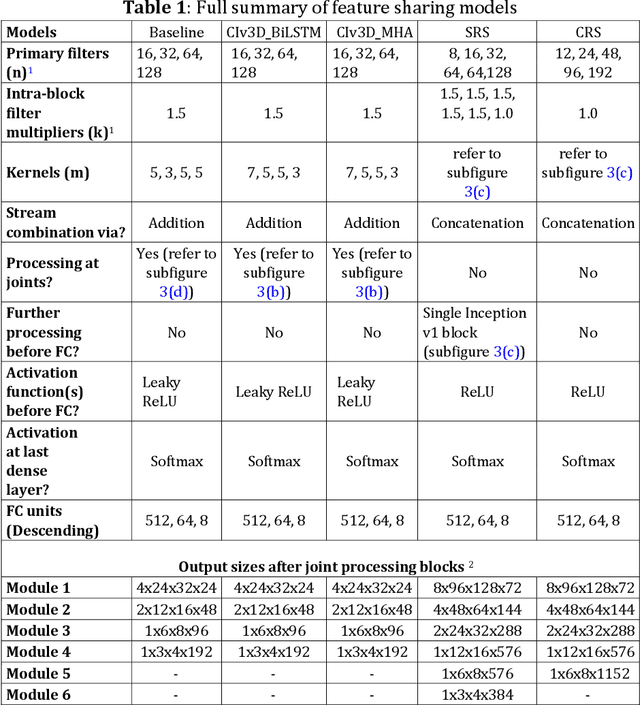

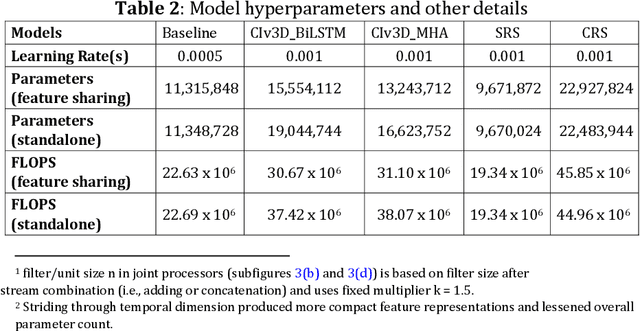
This paper presents a spatiotemporal deep learning approach for mouse behavioural classification in the home cage. Using a series of dual-stream architectures with assorted modifications to increase performance, we introduce a novel feature-sharing approach that jointly processes the streams at regular intervals throughout the network. Using a publicly available labelled dataset of singly-housed mice, we achieve a prediction accuracy of 86.47% using an ensemble of Inception-based networks that utilize feature sharing. We also demonstrate through ablation studies that for all models, the feature-sharing architectures consistently perform better than conventional ones having separate streams. The best performing models were further evaluated on other activity datasets, both mouse and human, and achieved state-of-the-art results. Future work will investigate the effectiveness of feature sharing in behavioural classification in the unsupervised anomaly detection domain.
Not Color Blind: AI Predicts Racial Identity from Black and White Retinal Vessel Segmentations
Sep 28, 2021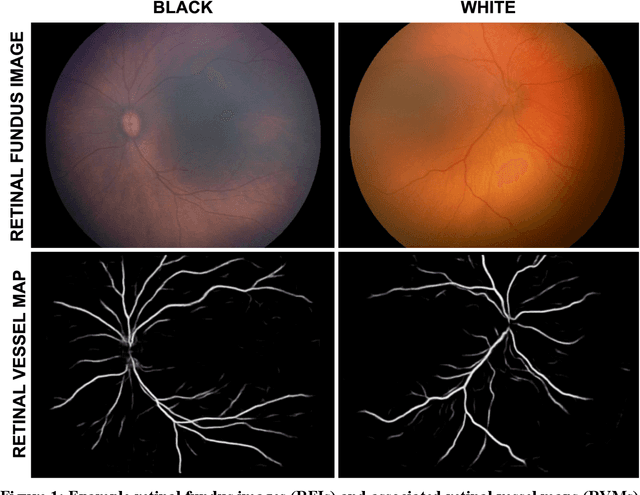
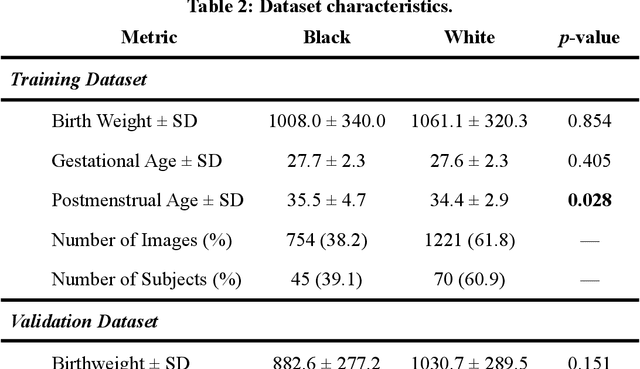
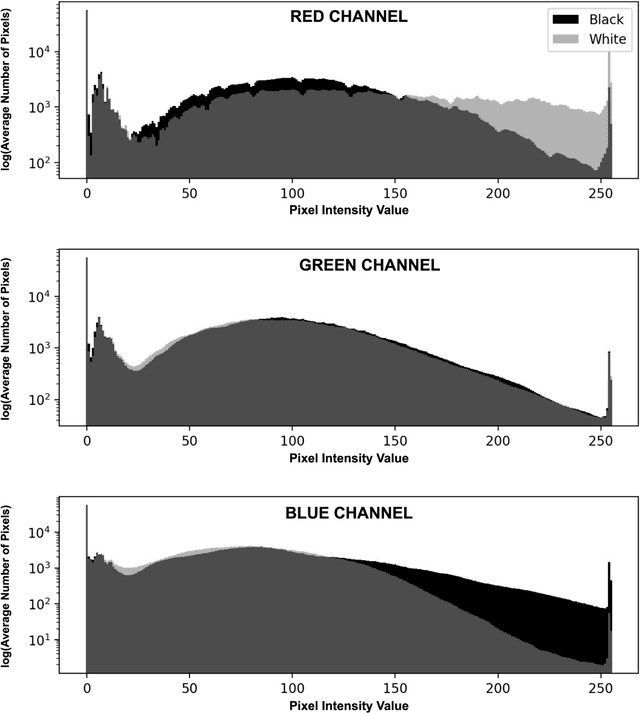
Background: Artificial intelligence (AI) may demonstrate racial bias when skin or choroidal pigmentation is present in medical images. Recent studies have shown that convolutional neural networks (CNNs) can predict race from images that were not previously thought to contain race-specific features. We evaluate whether grayscale retinal vessel maps (RVMs) of patients screened for retinopathy of prematurity (ROP) contain race-specific features. Methods: 4095 retinal fundus images (RFIs) were collected from 245 Black and White infants. A U-Net generated RVMs from RFIs, which were subsequently thresholded, binarized, or skeletonized. To determine whether RVM differences between Black and White eyes were physiological, CNNs were trained to predict race from color RFIs, raw RVMs, and thresholded, binarized, or skeletonized RVMs. Area under the precision-recall curve (AUC-PR) was evaluated. Findings: CNNs predicted race from RFIs near perfectly (image-level AUC-PR: 0.999, subject-level AUC-PR: 1.000). Raw RVMs were almost as informative as color RFIs (image-level AUC-PR: 0.938, subject-level AUC-PR: 0.995). Ultimately, CNNs were able to detect whether RFIs or RVMs were from Black or White babies, regardless of whether images contained color, vessel segmentation brightness differences were nullified, or vessel segmentation widths were normalized. Interpretation: AI can detect race from grayscale RVMs that were not thought to contain racial information. Two potential explanations for these findings are that: retinal vessels physiologically differ between Black and White babies or the U-Net segments the retinal vasculature differently for various fundus pigmentations. Either way, the implications remain the same: AI algorithms have potential to demonstrate racial bias in practice, even when preliminary attempts to remove such information from the underlying images appear to be successful.
Semi-Supervised Deep Learning for Abnormality Classification in Retinal Images
Dec 19, 2018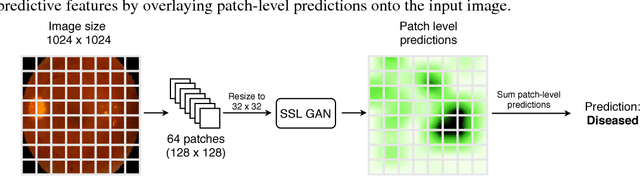


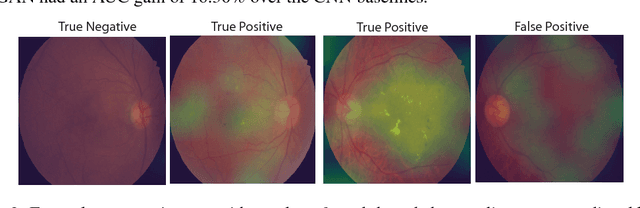
Supervised deep learning algorithms have enabled significant performance gains in medical image classification tasks. But these methods rely on large labeled datasets that require resource-intensive expert annotation. Semi-supervised generative adversarial network (GAN) approaches offer a means to learn from limited labeled data alongside larger unlabeled datasets, but have not been applied to discern fine-scale, sparse or localized features that define medical abnormalities. To overcome these limitations, we propose a patch-based semi-supervised learning approach and evaluate performance on classification of diabetic retinopathy from funduscopic images. Our semi-supervised approach achieves high AUC with just 10-20 labeled training images, and outperforms the supervised baselines by upto 15% when less than 30% of the training dataset is labeled. Further, our method implicitly enables interpretation of the SSL predictions. As this approach enables good accuracy, resolution and interpretability with lower annotation burden, it sets the pathway for scalable applications of deep learning in clinical imaging.
Deep feature transfer between localization and segmentation tasks
Nov 10, 2018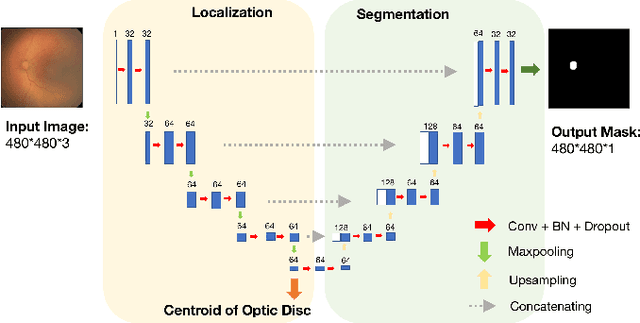
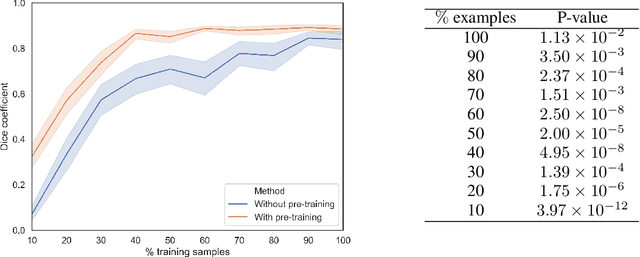
In this paper, we propose a new pre-training scheme for U-net based image segmentation. We first train the encoding arm as a localization network to predict the center of the target, before extending it into a U-net architecture for segmentation. We apply our proposed method to the problem of segmenting the optic disc from fundus photographs. Our work shows that the features learned by encoding arm can be transferred to the segmentation network to reduce the annotation burden. We propose that an approach could have broad utility for medical image segmentation, and alleviate the burden of delineating complex structures by pre-training on annotations that are much easier to acquire.