 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Offline Reinforcement Learning for Real-World Treatment Optimization Applications
Feb 15, 2023

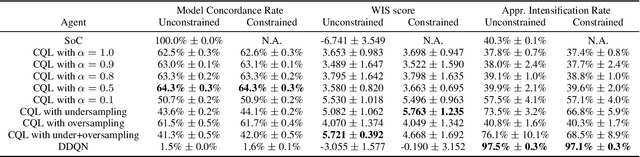
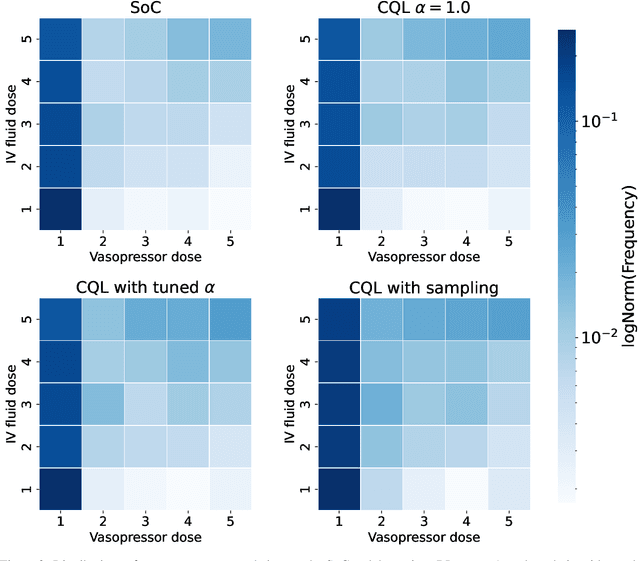
There is increasing interest in data-driven approaches for dynamically choosing optimal treatment strategies in many chronic disease management and critical care applications. Reinforcement learning methods are well-suited to this sequential decision-making problem, but must be trained and evaluated exclusively on retrospective medical record datasets as direct online exploration is unsafe and infeasible. Despite this requirement, the vast majority of dynamic treatment optimization studies use off-policy RL methods (e.g., Double Deep Q Networks (DDQN) or its variants) that are known to perform poorly in purely offline settings. Recent advances in offline RL, such as Conservative Q-Learning (CQL), offer a suitable alternative. But there remain challenges in adapting these approaches to real-world applications where suboptimal examples dominate the retrospective dataset and strict safety constraints need to be satisfied. In this work, we introduce a practical transition sampling approach to address action imbalance during offline RL training, and an intuitive heuristic to enforce hard constraints during policy execution. We provide theoretical analyses to show that our proposed approach would improve over CQL. We perform extensive experiments on two real-world tasks for diabetes and sepsis treatment optimization to compare performance of the proposed approach against prominent off-policy and offline RL baselines (DDQN and CQL). Across a range of principled and clinically relevant metrics, we show that our proposed approach enables substantial improvements in expected health outcomes and in consistency with relevant practice and safety guidelines.
Towards More Efficient Data Valuation in Healthcare Federated Learning using Ensembling
Sep 12, 2022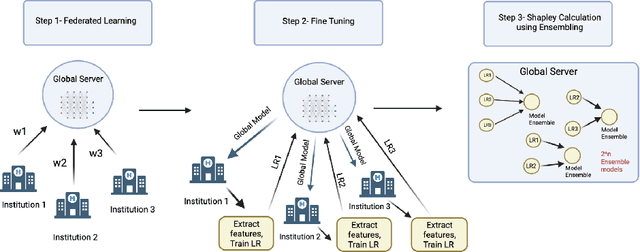
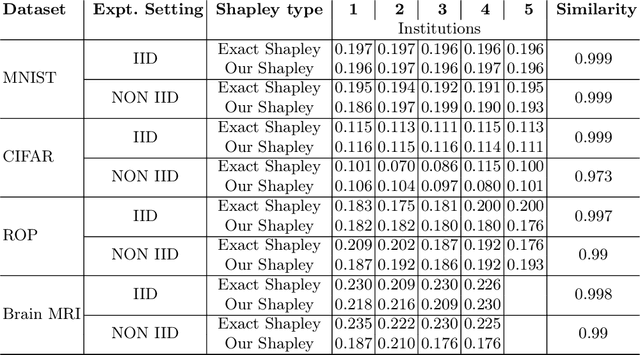
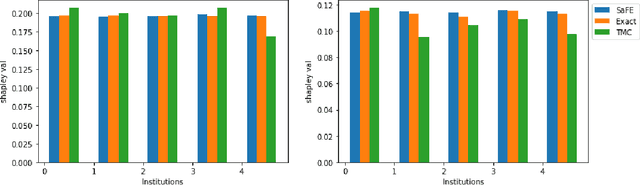
Federated Learning (FL) wherein multiple institutions collaboratively train a machine learning model without sharing data is becoming popular. Participating institutions might not contribute equally, some contribute more data, some better quality data or some more diverse data. To fairly rank the contribution of different institutions, Shapley value (SV) has emerged as the method of choice. Exact SV computation is impossibly expensive, especially when there are hundreds of contributors. Existing SV computation techniques use approximations. However, in healthcare where the number of contributing institutions are likely not of a colossal scale, computing exact SVs is still exorbitantly expensive, but not impossible. For such settings, we propose an efficient SV computation technique called SaFE (Shapley Value for Federated Learning using Ensembling). We empirically show that SaFE computes values that are close to exact SVs, and that it performs better than current SV approximations. This is particularly relevant in medical imaging setting where widespread heterogeneity across institutions is rampant and fast accurate data valuation is required to determine the contribution of each participant in multi-institutional collaborative learning.
Consistency-Based Semi-supervised Evidential Active Learning for Diagnostic Radiograph Classification
Sep 05, 2022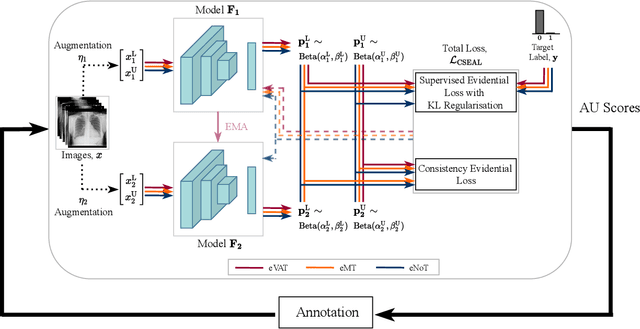
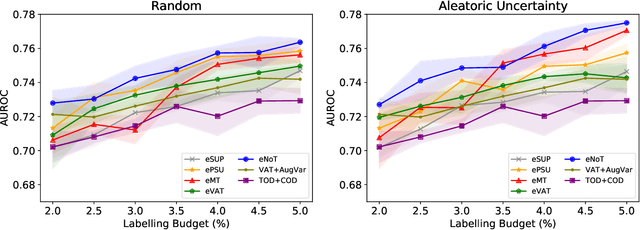
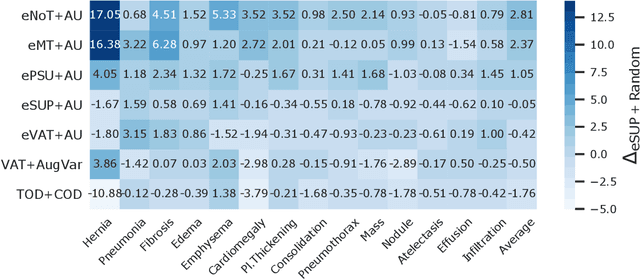
Deep learning approaches achieve state-of-the-art performance for classifying radiology images, but rely on large labelled datasets that require resource-intensive annotation by specialists. Both semi-supervised learning and active learning can be utilised to mitigate this annotation burden. However, there is limited work on combining the advantages of semi-supervised and active learning approaches for multi-label medical image classification. Here, we introduce a novel Consistency-based Semi-supervised Evidential Active Learning framework (CSEAL). Specifically, we leverage predictive uncertainty based on theories of evidence and subjective logic to develop an end-to-end integrated approach that combines consistency-based semi-supervised learning with uncertainty-based active learning. We apply our approach to enhance four leading consistency-based semi-supervised learning methods: Pseudo-labelling, Virtual Adversarial Training, Mean Teacher and NoTeacher. Extensive evaluations on multi-label Chest X-Ray classification tasks demonstrate that CSEAL achieves substantive performance improvements over two leading semi-supervised active learning baselines. Further, a class-wise breakdown of results shows that our approach can substantially improve accuracy on rarer abnormalities with fewer labelled samples.
Domain-specific Language Pre-training for Dialogue Comprehension on Clinical Inquiry-Answering Conversations
Jun 06, 2022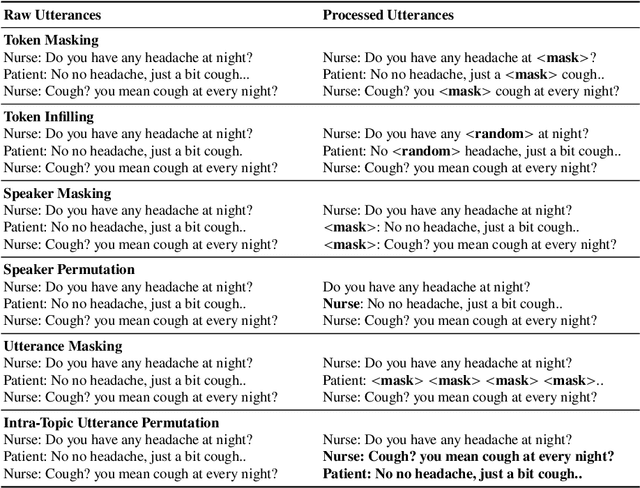
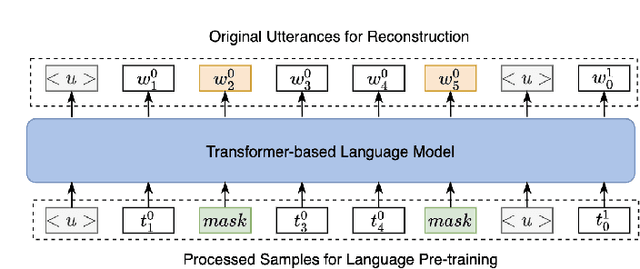

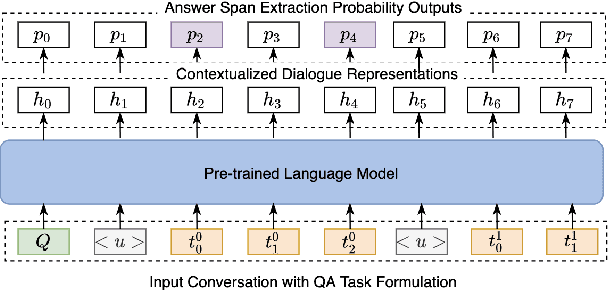
There is growing interest in the automated extraction of relevant information from clinical dialogues. However, it is difficult to collect and construct large annotated resources for clinical dialogue tasks. Recent developments in natural language processing suggest that large-scale pre-trained language backbones could be leveraged for such machine comprehension and information extraction tasks. Yet, due to the gap between pre-training and downstream clinical domains, it remains challenging to exploit the generic backbones for domain-specific applications. Therefore, in this work, we propose a domain-specific language pre-training, to improve performance on downstream tasks like dialogue comprehension. Aside from the common token-level masking pre-training method, according to the nature of human conversations and interactive flow of multi-topic inquiry-answering dialogues, we further propose sample generation strategies with speaker and utterance manipulation. The conversational pre-training guides the language backbone to reconstruct the utterances coherently based on the remaining context, thus bridging the gap between general and specific domains. Experiments are conducted on a clinical conversation dataset for symptom checking, where nurses inquire and discuss symptom information with patients. We empirically show that the neural model with our proposed approach brings improvement in the dialogue comprehension task, and can achieve favorable results in the low resource training scenario.
Semi-supervised classification of radiology images with NoTeacher: A Teacher that is not Mean
Aug 10, 2021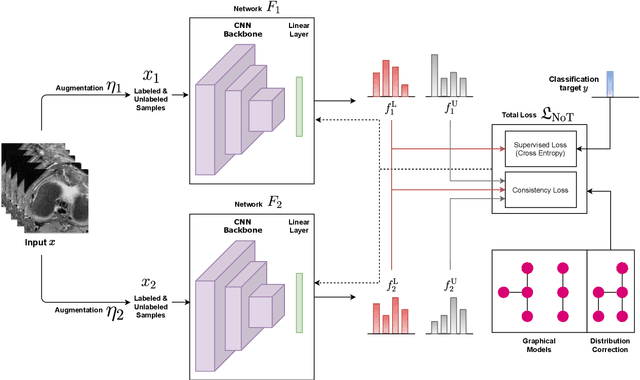
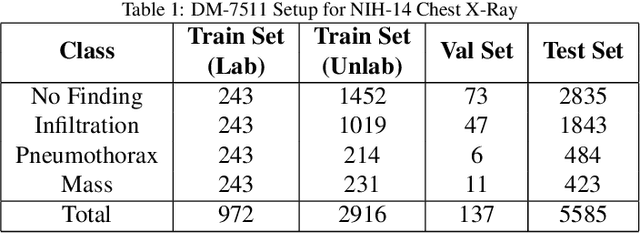
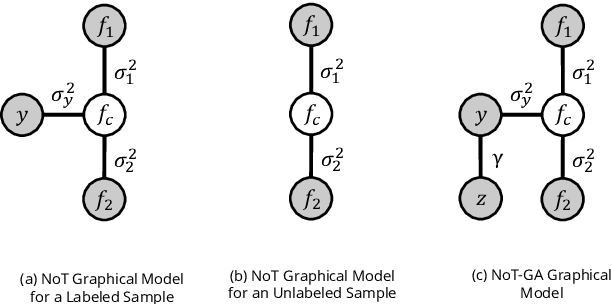
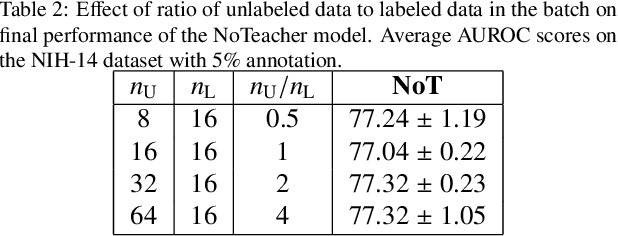
Deep learning models achieve strong performance for radiology image classification, but their practical application is bottlenecked by the need for large labeled training datasets. Semi-supervised learning (SSL) approaches leverage small labeled datasets alongside larger unlabeled datasets and offer potential for reducing labeling cost. In this work, we introduce NoTeacher, a novel consistency-based SSL framework which incorporates probabilistic graphical models. Unlike Mean Teacher which maintains a teacher network updated via a temporal ensemble, NoTeacher employs two independent networks, thereby eliminating the need for a teacher network. We demonstrate how NoTeacher can be customized to handle a range of challenges in radiology image classification. Specifically, we describe adaptations for scenarios with 2D and 3D inputs, uni and multi-label classification, and class distribution mismatch between labeled and unlabeled portions of the training data. In realistic empirical evaluations on three public benchmark datasets spanning the workhorse modalities of radiology (X-Ray, CT, MRI), we show that NoTeacher achieves over 90-95% of the fully supervised AUROC with less than 5-15% labeling budget. Further, NoTeacher outperforms established SSL methods with minimal hyperparameter tuning, and has implications as a principled and practical option for semisupervised learning in radiology applications.
Self-Path: Self-supervision for Classification of Pathology Images with Limited Annotations
Aug 12, 2020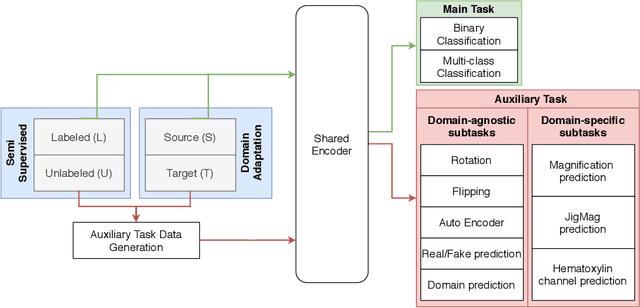
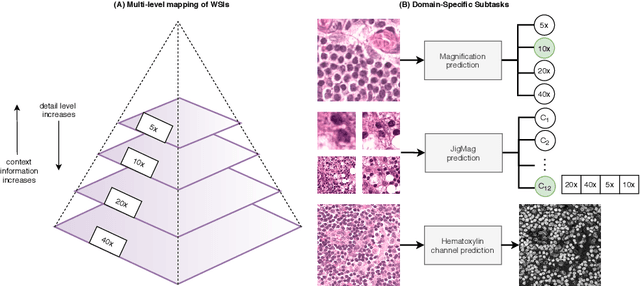
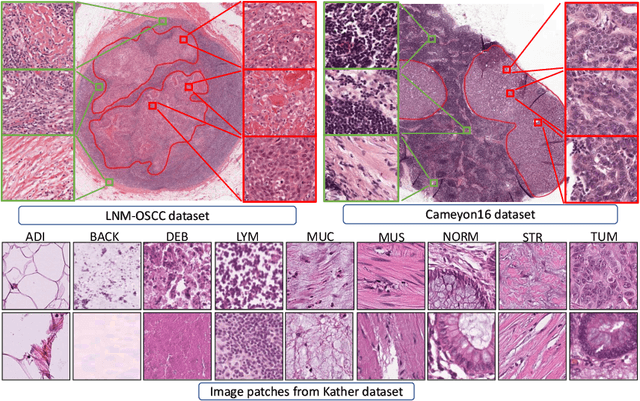
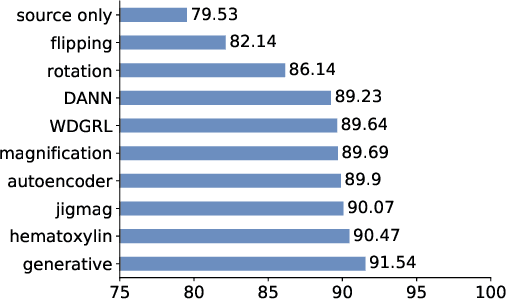
While high-resolution pathology images lend themselves well to `data hungry' deep learning algorithms, obtaining exhaustive annotations on these images is a major challenge. In this paper, we propose a self-supervised CNN approach to leverage unlabeled data for learning generalizable and domain invariant representations in pathology images. The proposed approach, which we term as Self-Path, is a multi-task learning approach where the main task is tissue classification and pretext tasks are a variety of self-supervised tasks with labels inherent to the input data. We introduce novel domain specific self-supervision tasks that leverage contextual, multi-resolution and semantic features in pathology images for semi-supervised learning and domain adaptation. We investigate the effectiveness of Self-Path on 3 different pathology datasets. Our results show that Self-Path with the domain-specific pretext tasks achieves state-of-the-art performance for semi-supervised learning when small amounts of labeled data are available. Further, we show that Self-Path improves domain adaptation for classification of histology image patches when there is no labeled data available for the target domain. This approach can potentially be employed for other applications in computational pathology, where annotation budget is often limited or large amount of unlabeled image data is available.
Joint Learning of Word and Label Embeddings for Sequence Labelling in Spoken Language Understanding
Oct 16, 2019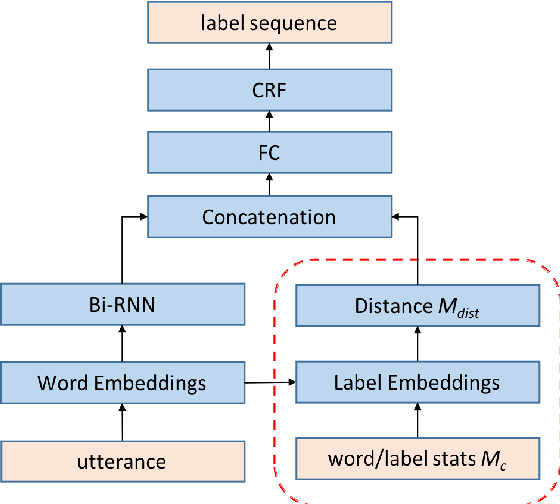
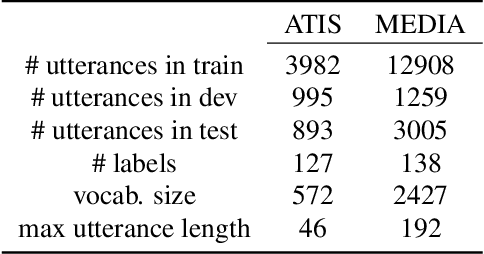
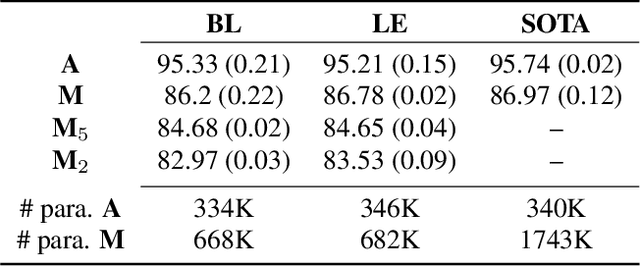

We propose an architecture to jointly learn word and label embeddings for slot filling in spoken language understanding. The proposed approach encodes labels using a combination of word embeddings and straightforward word-label association from the training data. Compared to the state-of-the-art methods, our approach does not require label embeddings as part of the input and therefore lends itself nicely to a wide range of model architectures. In addition, our architecture computes contextual distances between words and labels to avoid adding contextual windows, thus reducing memory footprint. We validate the approach on established spoken dialogue datasets and show that it can achieve state-of-the-art performance with much fewer trainable parameters.
Fast Prototyping a Dialogue Comprehension System for Nurse-Patient Conversations on Symptom Monitoring
Apr 05, 2019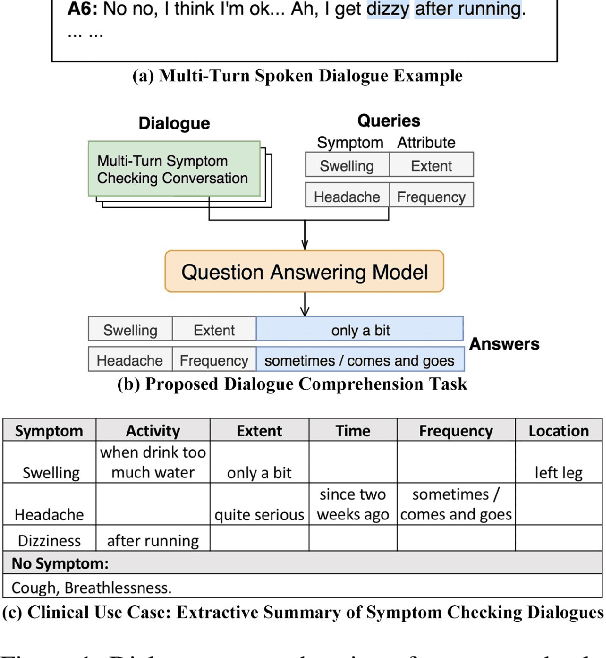

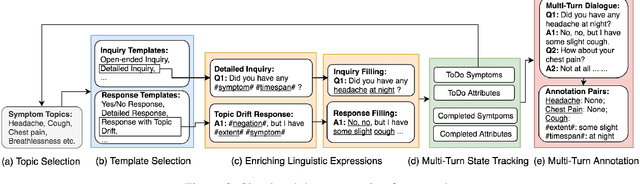
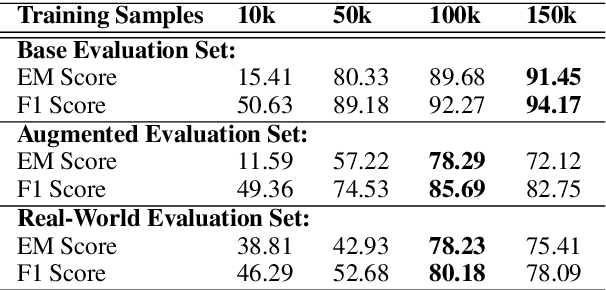
Data for human-human spoken dialogues for research and development are currently very limited in quantity, variety, and sources; such data are even scarcer in healthcare. In this work, we investigate fast prototyping of a dialogue comprehension system by leveraging on minimal nurse-to-patient conversations. We propose a framework inspired by nurse-initiated clinical symptom monitoring conversations to construct a simulated human-human dialogue dataset, embodying linguistic characteristics of spoken interactions like thinking aloud, self-contradiction, and topic drift. We then adopt an established bidirectional attention pointer network on this simulated dataset, achieving more than 80% F1 score on a held-out test set from real-world nurse-to-patient conversations. The ability to automatically comprehend conversations in the healthcare domain by exploiting only limited data has implications for improving clinical workflows through red flag symptom detection and triaging capabilities. We demonstrate the feasibility for efficient and effective extraction, retrieval and comprehension of symptom checking information discussed in multi-turn human-human spoken conversations.
Semi-Supervised Deep Learning for Abnormality Classification in Retinal Images
Dec 19, 2018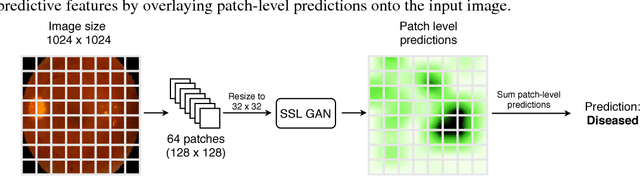


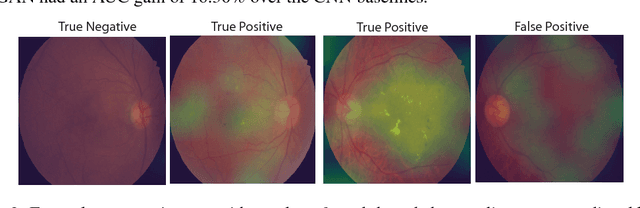
Supervised deep learning algorithms have enabled significant performance gains in medical image classification tasks. But these methods rely on large labeled datasets that require resource-intensive expert annotation. Semi-supervised generative adversarial network (GAN) approaches offer a means to learn from limited labeled data alongside larger unlabeled datasets, but have not been applied to discern fine-scale, sparse or localized features that define medical abnormalities. To overcome these limitations, we propose a patch-based semi-supervised learning approach and evaluate performance on classification of diabetic retinopathy from funduscopic images. Our semi-supervised approach achieves high AUC with just 10-20 labeled training images, and outperforms the supervised baselines by upto 15% when less than 30% of the training dataset is labeled. Further, our method implicitly enables interpretation of the SSL predictions. As this approach enables good accuracy, resolution and interpretability with lower annotation burden, it sets the pathway for scalable applications of deep learning in clinical imaging.
Online Deep Learning: Growing RBM on the fly
Mar 06, 2018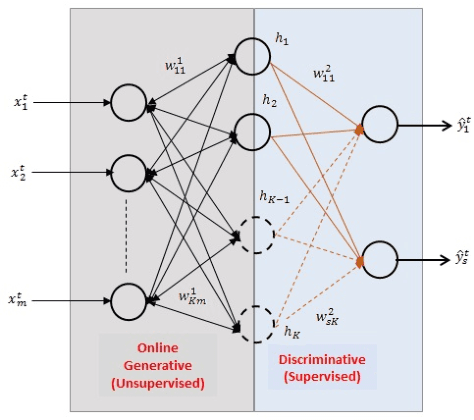

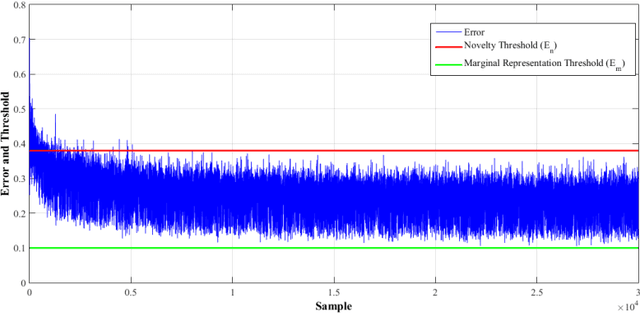
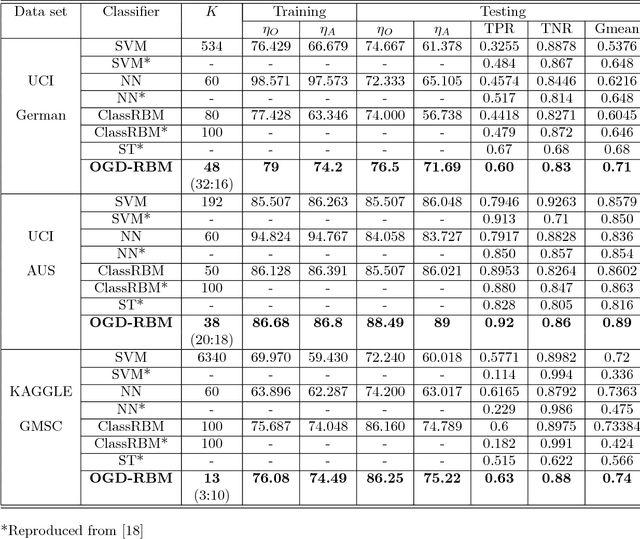
We propose a novel online learning algorithm for Restricted Boltzmann Machines (RBM), namely, the Online Generative Discriminative Restricted Boltzmann Machine (OGD-RBM), that provides the ability to build and adapt the network architecture of RBM according to the statistics of streaming data. The OGD-RBM is trained in two phases: (1) an online generative phase for unsupervised feature representation at the hidden layer and (2) a discriminative phase for classification. The online generative training begins with zero neurons in the hidden layer, adds and updates the neurons to adapt to statistics of streaming data in a single pass unsupervised manner, resulting in a feature representation best suited to the data. The discriminative phase is based on stochastic gradient descent and associates the represented features to the class labels. We demonstrate the OGD-RBM on a set of multi-category and binary classification problems for data sets having varying degrees of class-imbalance. We first apply the OGD-RBM algorithm on the multi-class MNIST dataset to characterize the network evolution. We demonstrate that the online generative phase converges to a stable, concise network architecture, wherein individual neurons are inherently discriminative to the class labels despite unsupervised training. We then benchmark OGD-RBM performance to other machine learning, neural network and ClassRBM techniques for credit scoring applications using 3 public non-stationary two-class credit datasets with varying degrees of class-imbalance. We report that OGD-RBM improves accuracy by 2.5-3% over batch learning techniques while requiring at least 24%-70% fewer neurons and fewer training samples. This online generative training approach can be extended greedily to multiple layers for training Deep Belief Networks in non-stationary data mining applications without the need for a priori fixed architectures.