 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreetwise Agents: Empowering Offline RL Policies to Outsmart Exogenous Stochastic Disturbances in RTC
Nov 11, 2024



The difficulty of exploring and training online on real production systems limits the scope of real-time online data/feedback-driven decision making. The most feasible approach is to adopt offline reinforcement learning from limited trajectory samples. However, after deployment, such policies fail due to exogenous factors that temporarily or permanently disturb/alter the transition distribution of the assumed decision process structure induced by offline samples. This results in critical policy failures and generalization errors in sensitive domains like Real-Time Communication (RTC). We solve this crucial problem of identifying robust actions in presence of domain shifts due to unseen exogenous stochastic factors in the wild. As it is impossible to learn generalized offline policies within the support of offline data that are robust to these unseen exogenous disturbances, we propose a novel post-deployment shaping of policies (Streetwise), conditioned on real-time characterization of out-of-distribution sub-spaces. This leads to robust actions in bandwidth estimation (BWE) of network bottlenecks in RTC and in standard benchmarks. Our extensive experimental results on BWE and other standard offline RL benchmark environments demonstrate a significant improvement ($\approx$ 18% on some scenarios) in final returns wrt. end-user metrics over state-of-the-art baselines.
Unveiling Context-Aware Criteria in Self-Assessing LLMs
Oct 28, 2024



The use of large language models (LLMs) as evaluators has garnered significant attention due to their potential to rival human-level evaluations in long-form response assessments. However, current LLM evaluators rely heavily on static, human-defined criteria, limiting their ability to generalize across diverse generative tasks and incorporate context-specific knowledge. In this paper, we propose a novel Self-Assessing LLM framework that integrates Context-Aware Criteria (SALC) with dynamic knowledge tailored to each evaluation instance. This instance-level knowledge enhances the LLM evaluator's performance by providing relevant and context-aware insights that pinpoint the important criteria specific to the current instance. Additionally, the proposed framework adapts seamlessly to various tasks without relying on predefined human criteria, offering a more flexible evaluation approach. Empirical evaluations demonstrate that our approach significantly outperforms existing baseline evaluation frameworks, yielding improvements on average 4.8% across a wide variety of datasets. Furthermore, by leveraging knowledge distillation techniques, we fine-tuned smaller language models for criteria generation and evaluation, achieving comparable or superior performance to larger models with much lower cost. Our method also exhibits a improvement in LC Win-Rate in AlpacaEval2 leaderboard up to a 12% when employed for preference data generation in Direct Preference Optimization (DPO), underscoring its efficacy as a robust and scalable evaluation framework.
Kinetics of orbital ordering in cooperative Jahn-Teller models: Machine-learning enabled large-scale simulations
May 23, 2024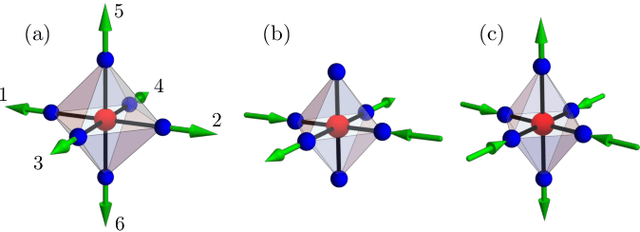

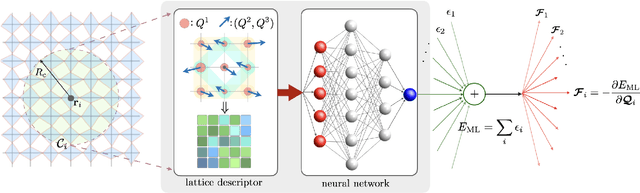
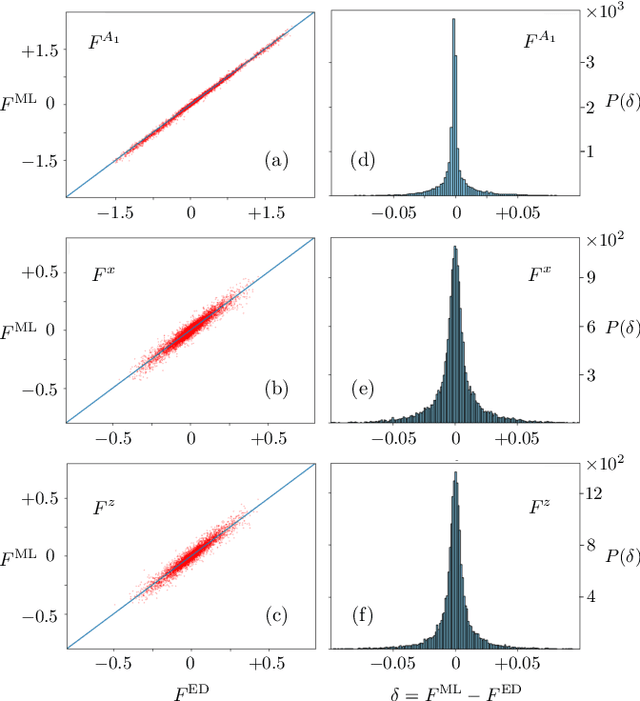
We present a scalable machine learning (ML) force-field model for the adiabatic dynamics of cooperative Jahn-Teller (JT) systems. Large scale dynamical simulations of the JT model also shed light on the orbital ordering dynamics in colossal magnetoresistance manganites. The JT effect in these materials describes the distortion of local oxygen octahedra driven by a coupling to the orbital degrees of freedom of $e_g$ electrons. An effective electron-mediated interaction between the local JT modes leads to a structural transition and the emergence of long-range orbital order at low temperatures. Assuming the principle of locality, a deep-learning neural-network model is developed to accurately and efficiently predict the electron-induced forces that drive the dynamical evolution of JT phonons. A group-theoretical method is utilized to develop a descriptor that incorporates the combined orbital and lattice symmetry into the ML model. Large-scale Langevin dynamics simulations, enabled by the ML force-field models, are performed to investigate the coarsening dynamics of the composite JT distortion and orbital order after a thermal quench. The late-stage coarsening of orbital domains exhibits pronounced freezing behaviors which are likely related to the unusual morphology of the domain structures. Our work highlights a promising avenue for multi-scale dynamical modeling of correlated electron systems.
Automated Root Causing of Cloud Incidents using In-Context Learning with GPT-4
Jan 24, 2024



Root Cause Analysis (RCA) plays a pivotal role in the incident diagnosis process for cloud services, requiring on-call engineers to identify the primary issues and implement corrective actions to prevent future recurrences. Improving the incident RCA process is vital for minimizing service downtime, customer impact and manual toil. Recent advances in artificial intelligence have introduced state-of-the-art Large Language Models (LLMs) like GPT-4, which have proven effective in tackling various AIOps problems, ranging from code authoring to incident management. Nonetheless, the GPT-4 model's immense size presents challenges when trying to fine-tune it on user data because of the significant GPU resource demand and the necessity for continuous model fine-tuning with the emergence of new data. To address the high cost of fine-tuning LLM, we propose an in-context learning approach for automated root causing, which eliminates the need for fine-tuning. We conduct extensive study over 100,000 production incidents, comparing several large language models using multiple metrics. The results reveal that our in-context learning approach outperforms the previous fine-tuned large language models such as GPT-3 by an average of 24.8\% across all metrics, with an impressive 49.7\% improvement over the zero-shot model. Moreover, human evaluation involving actual incident owners demonstrates its superiority over the fine-tuned model, achieving a 43.5\% improvement in correctness and an 8.7\% enhancement in readability. The impressive results demonstrate the viability of utilizing a vanilla GPT model for the RCA task, thereby avoiding the high computational and maintenance costs associated with a fine-tuned model.
Deep Offline Reinforcement Learning for Real-World Treatment Optimization Applications
Feb 15, 2023

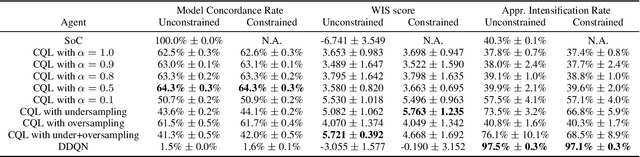
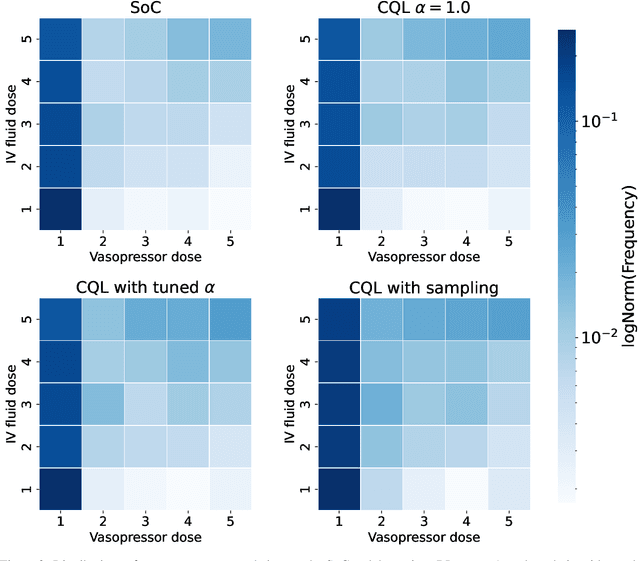
There is increasing interest in data-driven approaches for dynamically choosing optimal treatment strategies in many chronic disease management and critical care applications. Reinforcement learning methods are well-suited to this sequential decision-making problem, but must be trained and evaluated exclusively on retrospective medical record datasets as direct online exploration is unsafe and infeasible. Despite this requirement, the vast majority of dynamic treatment optimization studies use off-policy RL methods (e.g., Double Deep Q Networks (DDQN) or its variants) that are known to perform poorly in purely offline settings. Recent advances in offline RL, such as Conservative Q-Learning (CQL), offer a suitable alternative. But there remain challenges in adapting these approaches to real-world applications where suboptimal examples dominate the retrospective dataset and strict safety constraints need to be satisfied. In this work, we introduce a practical transition sampling approach to address action imbalance during offline RL training, and an intuitive heuristic to enforce hard constraints during policy execution. We provide theoretical analyses to show that our proposed approach would improve over CQL. We perform extensive experiments on two real-world tasks for diabetes and sepsis treatment optimization to compare performance of the proposed approach against prominent off-policy and offline RL baselines (DDQN and CQL). Across a range of principled and clinically relevant metrics, we show that our proposed approach enables substantial improvements in expected health outcomes and in consistency with relevant practice and safety guidelines.
Recommending Root-Cause and Mitigation Steps for Cloud Incidents using Large Language Models
Jan 10, 2023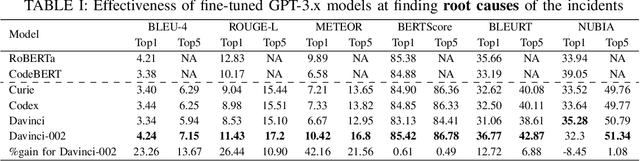
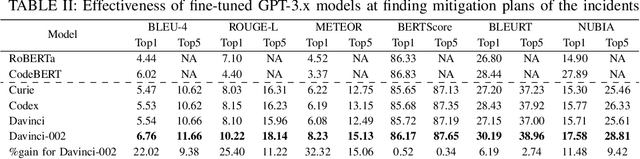

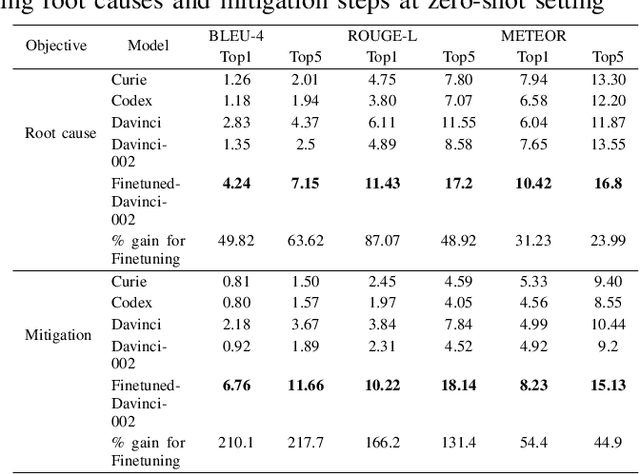
Incident management for cloud services is a complex process involving several steps and has a huge impact on both service health and developer productivity. On-call engineers require significant amount of domain knowledge and manual effort for root causing and mitigation of production incidents. Recent advances in artificial intelligence has resulted in state-of-the-art large language models like GPT-3.x (both GPT-3.0 and GPT-3.5), which have been used to solve a variety of problems ranging from question answering to text summarization. In this work, we do the first large-scale study to evaluate the effectiveness of these models for helping engineers root cause and mitigate production incidents. We do a rigorous study at Microsoft, on more than 40,000 incidents and compare several large language models in zero-shot, fine-tuned and multi-task setting using semantic and lexical metrics. Lastly, our human evaluation with actual incident owners show the efficacy and future potential of using artificial intelligence for resolving cloud incidents.
Neural-Progressive Hedging: Enforcing Constraints in Reinforcement Learning with Stochastic Programming
Feb 27, 2022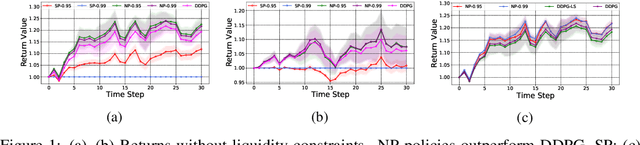
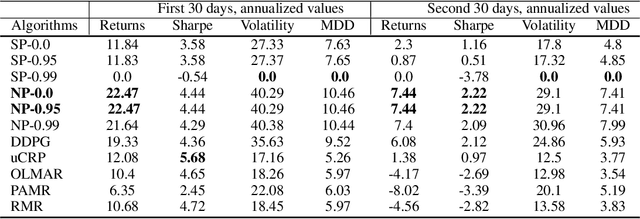
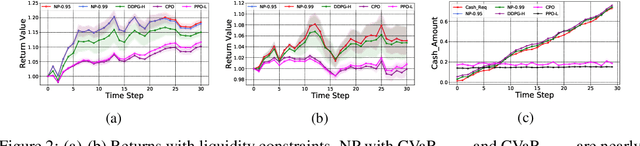
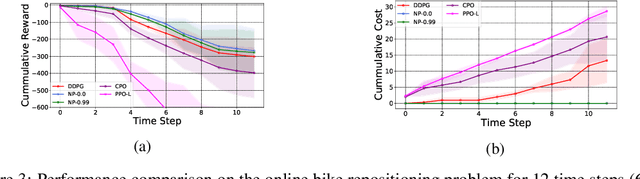
We propose a framework, called neural-progressive hedging (NP), that leverages stochastic programming during the online phase of executing a reinforcement learning (RL) policy. The goal is to ensure feasibility with respect to constraints and risk-based objectives such as conditional value-at-risk (CVaR) during the execution of the policy, using probabilistic models of the state transitions to guide policy adjustments. The framework is particularly amenable to the class of sequential resource allocation problems since feasibility with respect to typical resource constraints cannot be enforced in a scalable manner. The NP framework provides an alternative that adds modest overhead during the online phase. Experimental results demonstrate the efficacy of the NP framework on two continuous real-world tasks: (i) the portfolio optimization problem with liquidity constraints for financial planning, characterized by non-stationary state distributions; and (ii) the dynamic repositioning problem in bike sharing systems, that embodies the class of supply-demand matching problems. We show that the NP framework produces policies that are better than deep RL and other baseline approaches, adapting to non-stationarity, whilst satisfying structural constraints and accommodating risk measures in the resulting policies. Additional benefits of the NP framework are ease of implementation and better explainability of the policies.
Picking Pearl From Seabed: Extracting Artefacts from Noisy Issue Triaging Collaborative Conversations for Hybrid Cloud Services
May 31, 2021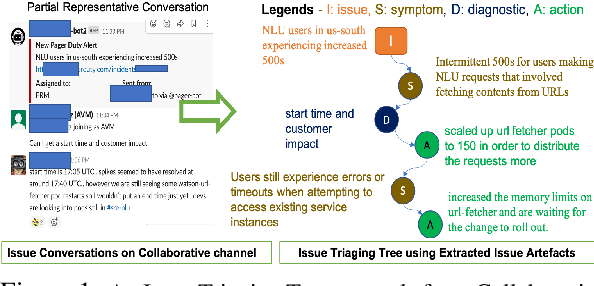
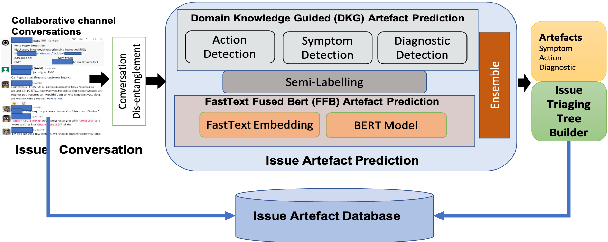
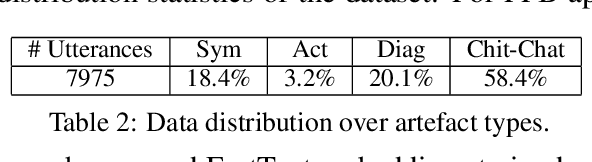

Site Reliability Engineers (SREs) play a key role in issue identification and resolution. After an issue is reported, SREs come together in a virtual room (collaboration platform) to triage the issue. While doing so, they leave behind a wealth of information which can be used later for triaging similar issues. However, usability of the conversations offer challenges due to them being i) noisy and ii) unlabelled. This paper presents a novel approach for issue artefact extraction from the noisy conversations with minimal labelled data. We propose a combination of unsupervised and supervised model with minimum human intervention that leverages domain knowledge to predict artefacts for a small amount of conversation data and use that for fine-tuning an already pretrained language model for artefact prediction on a large amount of conversation data. Experimental results on our dataset show that the proposed ensemble of unsupervised and supervised model is better than using either one of them individually.
A Deep Ensemble Multi-Agent Reinforcement Learning Approach for Air Traffic Control
Apr 03, 2020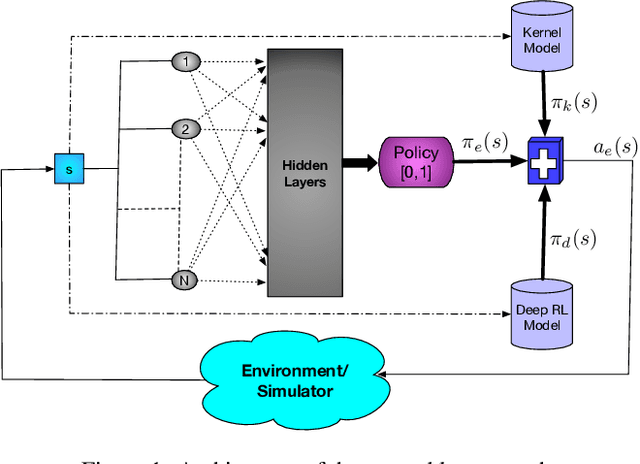
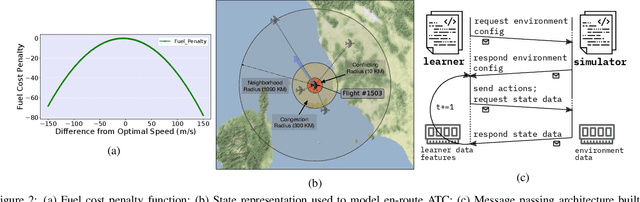
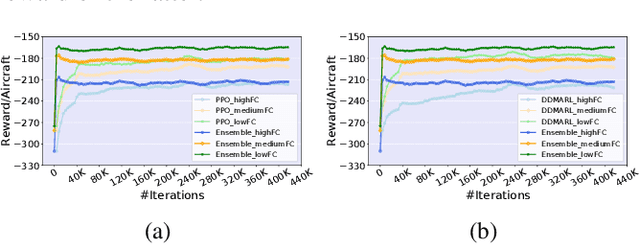
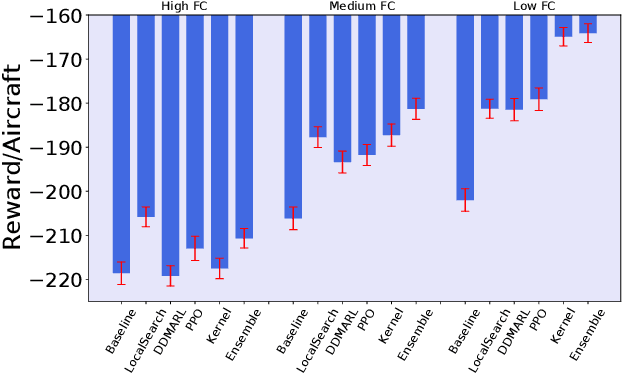
Air traffic control is an example of a highly challenging operational problem that is readily amenable to human expertise augmentation via decision support technologies. In this paper, we propose a new intelligent decision making framework that leverages multi-agent reinforcement learning (MARL) to dynamically suggest adjustments of aircraft speeds in real-time. The goal of the system is to enhance the ability of an air traffic controller to provide effective guidance to aircraft to avoid air traffic congestion, near-miss situations, and to improve arrival timeliness. We develop a novel deep ensemble MARL method that can concisely capture the complexity of the air traffic control problem by learning to efficiently arbitrate between the decisions of a local kernel-based RL model and a wider-reaching deep MARL model. The proposed method is trained and evaluated on an open-source air traffic management simulator developed by Eurocontrol. Extensive empirical results on a real-world dataset including thousands of aircraft demonstrate the feasibility of using multi-agent RL for the problem of en-route air traffic control and show that our proposed deep ensemble MARL method significantly outperforms three state-of-the-art benchmark approaches.