 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreetwise Agents: Empowering Offline RL Policies to Outsmart Exogenous Stochastic Disturbances in RTC
Nov 11, 2024



The difficulty of exploring and training online on real production systems limits the scope of real-time online data/feedback-driven decision making. The most feasible approach is to adopt offline reinforcement learning from limited trajectory samples. However, after deployment, such policies fail due to exogenous factors that temporarily or permanently disturb/alter the transition distribution of the assumed decision process structure induced by offline samples. This results in critical policy failures and generalization errors in sensitive domains like Real-Time Communication (RTC). We solve this crucial problem of identifying robust actions in presence of domain shifts due to unseen exogenous stochastic factors in the wild. As it is impossible to learn generalized offline policies within the support of offline data that are robust to these unseen exogenous disturbances, we propose a novel post-deployment shaping of policies (Streetwise), conditioned on real-time characterization of out-of-distribution sub-spaces. This leads to robust actions in bandwidth estimation (BWE) of network bottlenecks in RTC and in standard benchmarks. Our extensive experimental results on BWE and other standard offline RL benchmark environments demonstrate a significant improvement ($\approx$ 18% on some scenarios) in final returns wrt. end-user metrics over state-of-the-art baselines.
Real-time Bandwidth Estimation from Offline Expert Demonstrations
Sep 23, 2023



In this work, we tackle the problem of bandwidth estimation (BWE) for real-time communication systems; however, in contrast to previous works, we leverage the vast efforts of prior heuristic-based BWE methods and synergize these approaches with deep learning-based techniques. Our work addresses challenges in generalizing to unseen network dynamics and extracting rich representations from prior experience, two key challenges in integrating data-driven bandwidth estimators into real-time systems. To that end, we propose Merlin, the first purely offline, data-driven solution to BWE that harnesses prior heuristic-based methods to extract an expert BWE policy. Through a series of experiments, we demonstrate that Merlin surpasses state-of-the-art heuristic-based and deep learning-based bandwidth estimators in terms of objective quality of experience metrics while generalizing beyond the offline world to in-the-wild network deployments where Merlin achieves a 42.85% and 12.8% reduction in packet loss and delay, respectively, when compared against WebRTC in inter-continental videoconferencing calls. We hope that Merlin's offline-oriented design fosters new strategies for real-time network control.
LSTM-based Video Quality Prediction Accounting for Temporal Distortions in Videoconferencing Calls
Mar 22, 2023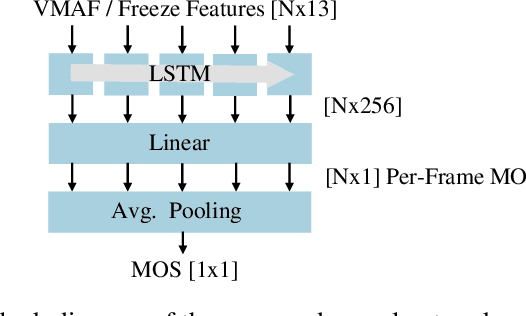
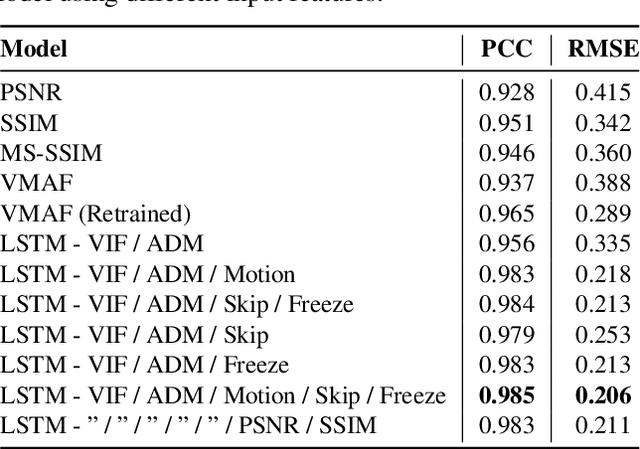
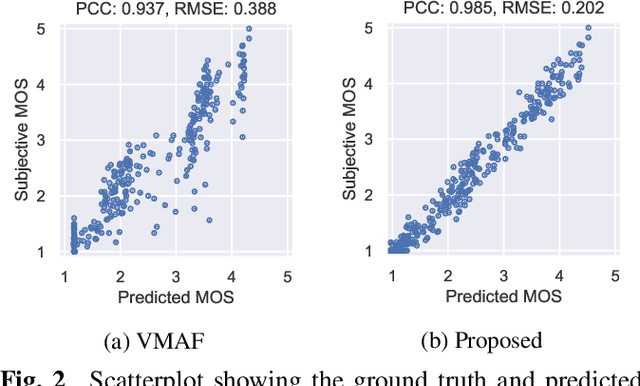
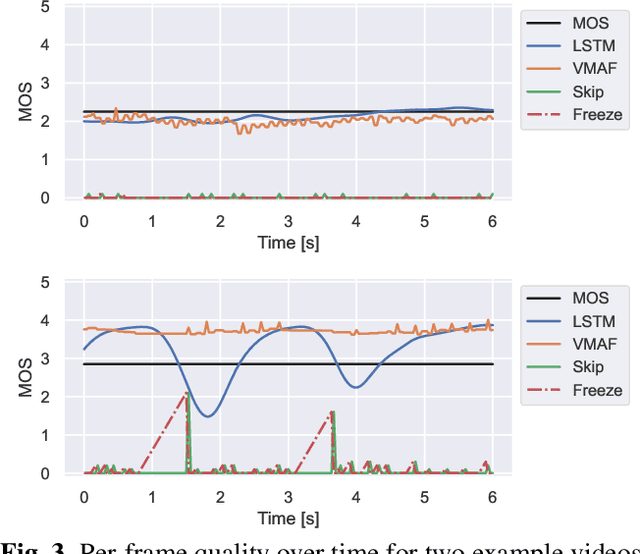
Current state-of-the-art video quality models, such as VMAF, give excellent prediction results by comparing the degraded video with its reference video. However, they do not consider temporal distortions (e.g., frame freezes or skips) that occur during videoconferencing calls. In this paper, we present a data-driven approach for modeling such distortions automatically by training an LSTM with subjective quality ratings labeled via crowdsourcing. The videos were collected from live videoconferencing calls in 83 different network conditions. We applied QR codes as markers on the source videos to create aligned references and compute temporal features based on the alignment vectors. Using these features together with VMAF core features, our proposed model achieves a PCC of 0.99 on the validation set. Furthermore, our model outputs per-frame quality that gives detailed insight into the cause of video quality impairments. The VCM model and dataset are open-sourced at https://github.com/microsoft/Video_Call_MOS.
ConferencingSpeech 2022 Challenge: Non-intrusive Objective Speech Quality Assessment (NISQA) Challenge for Online Conferencing Applications
Apr 01, 2022
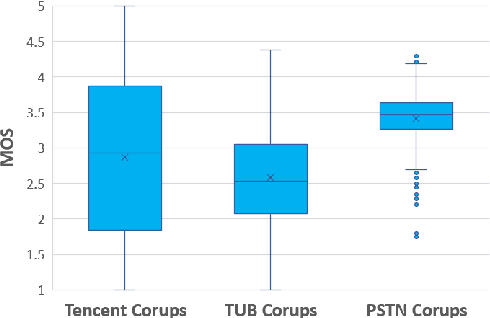

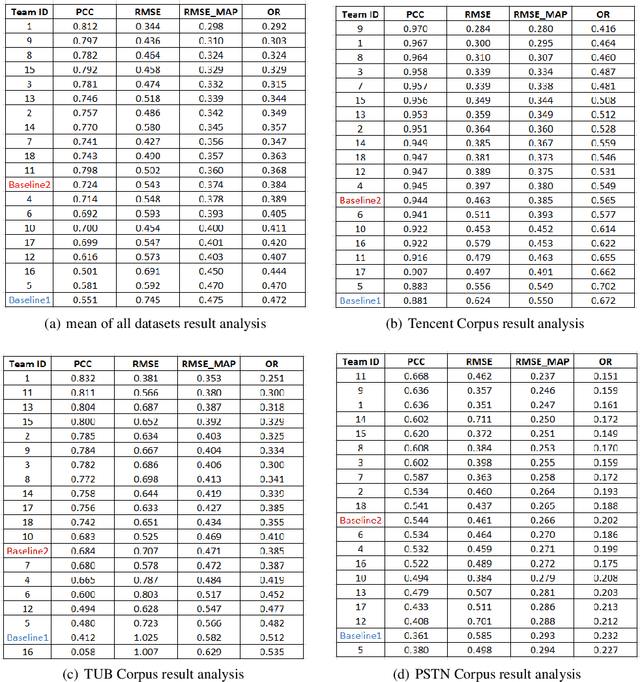
With the advances in speech communication systems such as online conferencing applications, we can seamlessly work with people regardless of where they are. However, during online meetings, speech quality can be significantly affected by background noise, reverberation, packet loss, network jitter, etc. Because of its nature, speech quality is traditionally assessed in subjective tests in laboratories and lately also in crowdsourcing following the international standards from ITU-T Rec. P.800 series. However, those approaches are costly and cannot be applied to customer data. Therefore, an effective objective assessment approach is needed to evaluate or monitor the speech quality of the ongoing conversation. The ConferencingSpeech 2022 challenge targets the non-intrusive deep neural network models for the speech quality assessment task. We open-sourced a training corpus with more than 86K speech clips in different languages, with a wide range of synthesized and live degradations and their corresponding subjective quality scores through crowdsourcing. 18 teams submitted their models for evaluation in this challenge. The blind test sets included about 4300 clips from wide ranges of degradations. This paper describes the challenge, the datasets, and the evaluation methods and reports the final results.
Deep Learning Based Assessment of Synthetic Speech Naturalness
Apr 23, 2021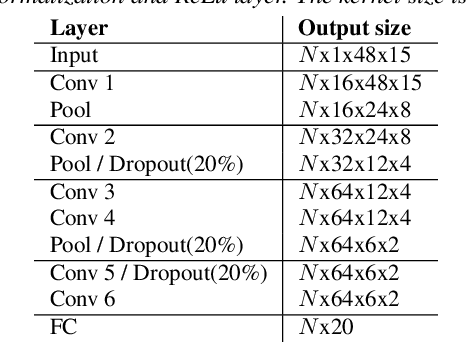
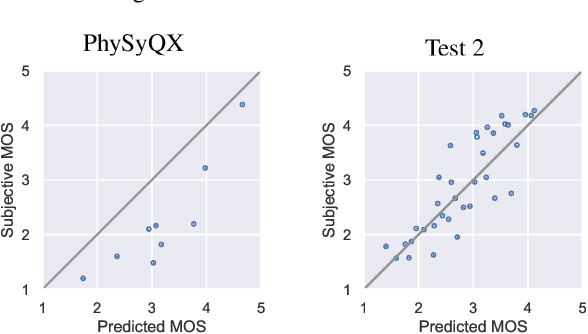
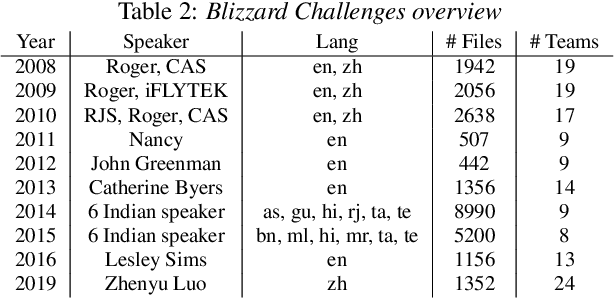

In this paper, we present a new objective prediction model for synthetic speech naturalness. It can be used to evaluate Text-To-Speech or Voice Conversion systems and works language independently. The model is trained end-to-end and based on a CNN-LSTM network that previously showed to give good results for speech quality estimation. We trained and tested the model on 16 different datasets, such as from the Blizzard Challenge and the Voice Conversion Challenge. Further, we show that the reliability of deep learning-based naturalness prediction can be improved by transfer learning from speech quality prediction models that are trained on objective POLQA scores. The proposed model is made publicly available and can, for example, be used to evaluate different TTS system configurations.
Bias-Aware Loss for Training Image and Speech Quality Prediction Models from Multiple Datasets
Apr 20, 2021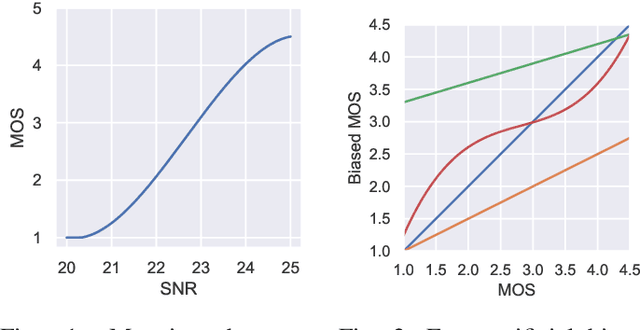
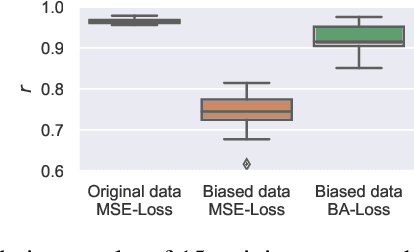
The ground truth used for training image, video, or speech quality prediction models is based on the Mean Opinion Scores (MOS) obtained from subjective experiments. Usually, it is necessary to conduct multiple experiments, mostly with different test participants, to obtain enough data to train quality models based on machine learning. Each of these experiments is subject to an experiment-specific bias, where the rating of the same file may be substantially different in two experiments (e.g. depending on the overall quality distribution). These different ratings for the same distortion levels confuse neural networks during training and lead to lower performance. To overcome this problem, we propose a bias-aware loss function that estimates each dataset's biases during training with a linear function and considers it while optimising the network weights. We prove the efficiency of the proposed method by training and validating quality prediction models on synthetic and subjective image and speech quality datasets.
NISQA: A Deep CNN-Self-Attention Model for Multidimensional Speech Quality Prediction with Crowdsourced Datasets
Apr 19, 2021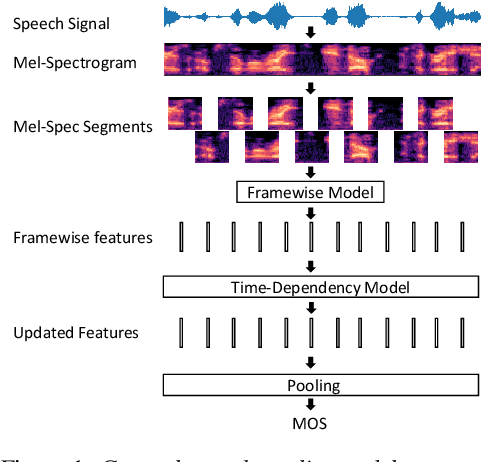
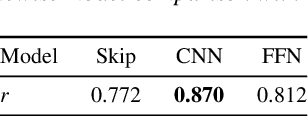
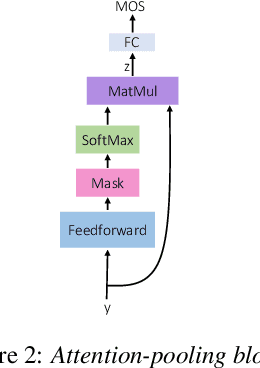
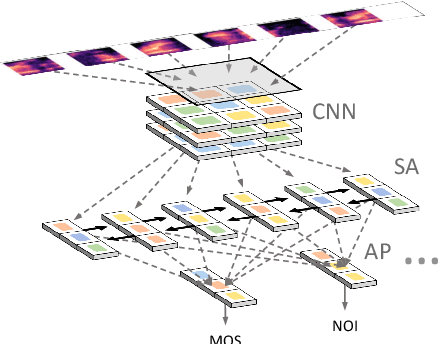
In this paper, we present an update to the NISQA speech quality prediction model that is focused on distortions that occur in communication networks. In contrast to the previous version, the model is trained end-to-end and the time-dependency modelling and time-pooling is achieved through a Self-Attention mechanism. Besides overall speech quality, the model also predicts the four speech quality dimensions Noisiness, Coloration, Discontinuity, and Loudness, and in this way gives more insight into the cause of a quality degradation. Furthermore, new datasets with over 13,000 speech files were created for training and validation of the model. The model was finally tested on a new, live-talking test dataset that contains recordings of real telephone calls. Overall, NISQA was trained and evaluated on 81 datasets from different sources and showed to provide reliable predictions also for unknown speech samples. The code, model weights, and datasets are open-sourced.