 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNISQA: A Deep CNN-Self-Attention Model for Multidimensional Speech Quality Prediction with Crowdsourced Datasets
Paper and Code
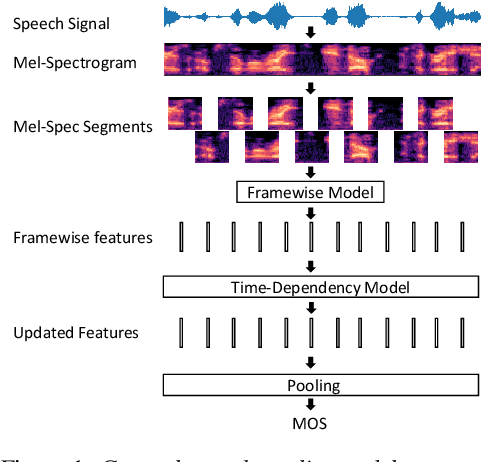
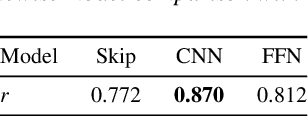
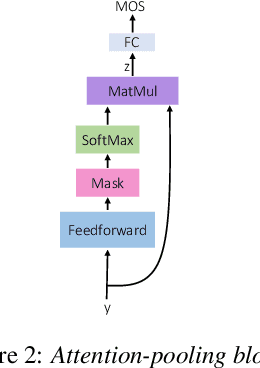
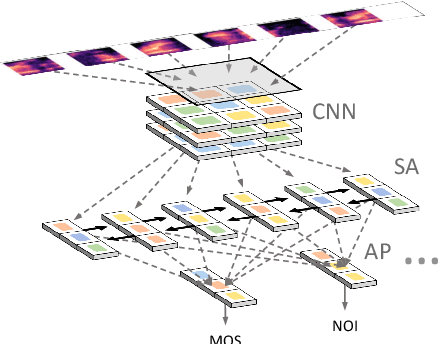
In this paper, we present an update to the NISQA speech quality prediction model that is focused on distortions that occur in communication networks. In contrast to the previous version, the model is trained end-to-end and the time-dependency modelling and time-pooling is achieved through a Self-Attention mechanism. Besides overall speech quality, the model also predicts the four speech quality dimensions Noisiness, Coloration, Discontinuity, and Loudness, and in this way gives more insight into the cause of a quality degradation. Furthermore, new datasets with over 13,000 speech files were created for training and validation of the model. The model was finally tested on a new, live-talking test dataset that contains recordings of real telephone calls. Overall, NISQA was trained and evaluated on 81 datasets from different sources and showed to provide reliable predictions also for unknown speech samples. The code, model weights, and datasets are open-sourced.