 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias-Aware Loss for Training Image and Speech Quality Prediction Models from Multiple Datasets
Paper and Code
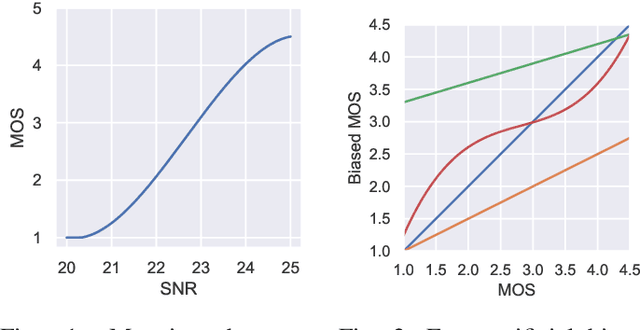
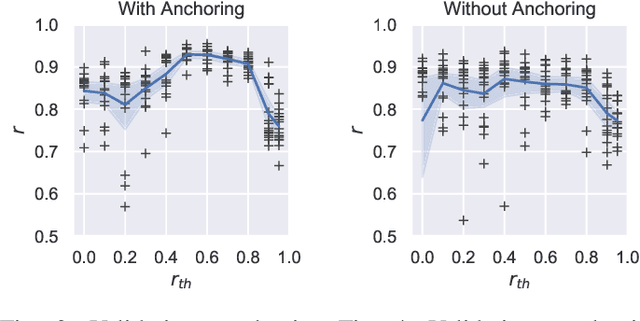
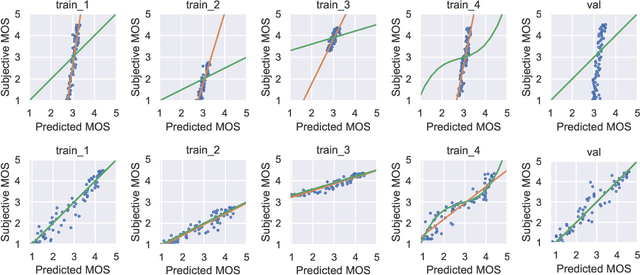
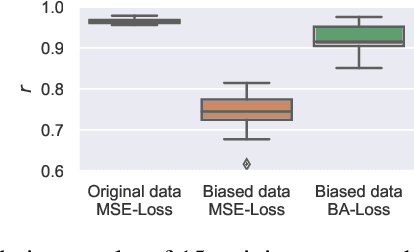
The ground truth used for training image, video, or speech quality prediction models is based on the Mean Opinion Scores (MOS) obtained from subjective experiments. Usually, it is necessary to conduct multiple experiments, mostly with different test participants, to obtain enough data to train quality models based on machine learning. Each of these experiments is subject to an experiment-specific bias, where the rating of the same file may be substantially different in two experiments (e.g. depending on the overall quality distribution). These different ratings for the same distortion levels confuse neural networks during training and lead to lower performance. To overcome this problem, we propose a bias-aware loss function that estimates each dataset's biases during training with a linear function and considers it while optimising the network weights. We prove the efficiency of the proposed method by training and validating quality prediction models on synthetic and subjective image and speech quality datasets.