 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Based Assessment of Synthetic Speech Naturalness
Paper and Code
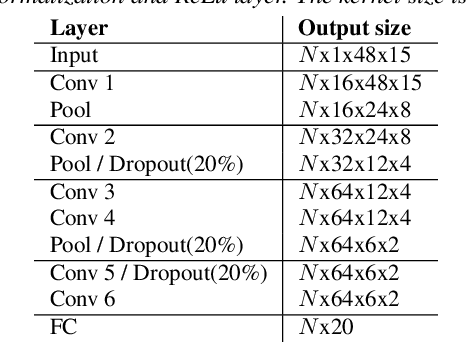
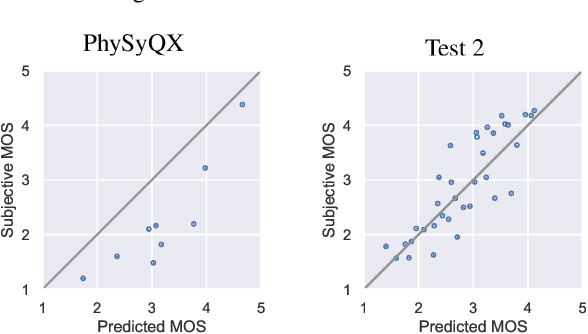
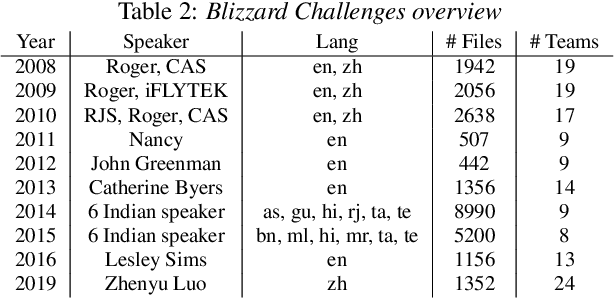

In this paper, we present a new objective prediction model for synthetic speech naturalness. It can be used to evaluate Text-To-Speech or Voice Conversion systems and works language independently. The model is trained end-to-end and based on a CNN-LSTM network that previously showed to give good results for speech quality estimation. We trained and tested the model on 16 different datasets, such as from the Blizzard Challenge and the Voice Conversion Challenge. Further, we show that the reliability of deep learning-based naturalness prediction can be improved by transfer learning from speech quality prediction models that are trained on objective POLQA scores. The proposed model is made publicly available and can, for example, be used to evaluate different TTS system configurations.