 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Barriers: Evaluating Cross-Lingual Performance of CNN and Transformer Architectures for Speech Quality Estimation
Feb 18, 2025Objective speech quality models aim to predict human-perceived speech quality using automated methods. However, cross-lingual generalization remains a major challenge, as Mean Opinion Scores (MOS) vary across languages due to linguistic, perceptual, and dataset-specific differences. A model trained primarily on English data may struggle to generalize to languages with different phonetic, tonal, and prosodic characteristics, leading to inconsistencies in objective assessments. This study investigates the cross-lingual performance of two speech quality models: NISQA, a CNN-based model, and a Transformer-based Audio Spectrogram Transformer (AST) model. Both models were trained exclusively on English datasets containing over 49,000 speech samples and subsequently evaluated on speech in German, French, Mandarin, Swedish, and Dutch. We analyze model performance using Pearson Correlation Coefficient (PCC) and Root Mean Square Error (RMSE) across five speech quality dimensions: coloration, discontinuity, loudness, noise, and MOS. Our findings show that while AST achieves a more stable cross-lingual performance, both models exhibit noticeable biases. Notably, Mandarin speech quality predictions correlate highly with human MOS scores, whereas Swedish and Dutch present greater prediction challenges. Discontinuities remain difficult to model across all languages. These results highlight the need for more balanced multilingual datasets and architecture-specific adaptations to improve cross-lingual generalization.
ConferencingSpeech 2022 Challenge: Non-intrusive Objective Speech Quality Assessment (NISQA) Challenge for Online Conferencing Applications
Apr 01, 2022
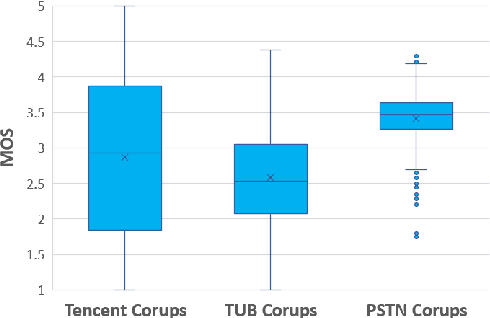

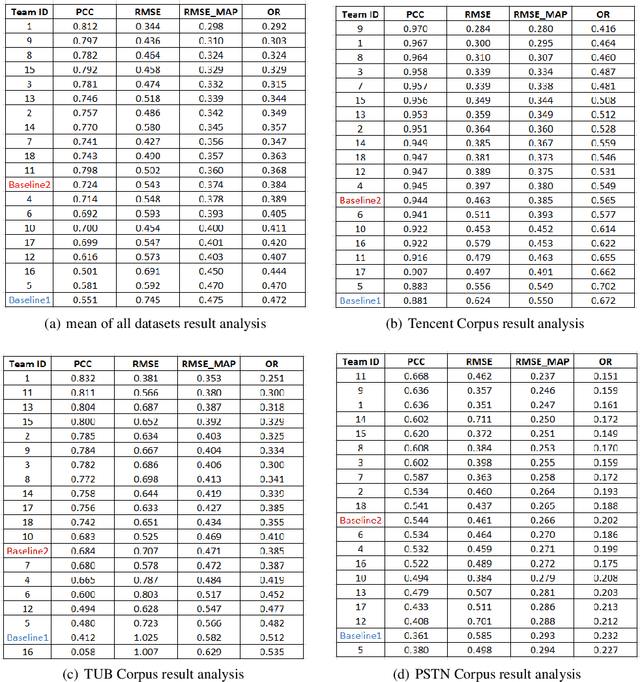
With the advances in speech communication systems such as online conferencing applications, we can seamlessly work with people regardless of where they are. However, during online meetings, speech quality can be significantly affected by background noise, reverberation, packet loss, network jitter, etc. Because of its nature, speech quality is traditionally assessed in subjective tests in laboratories and lately also in crowdsourcing following the international standards from ITU-T Rec. P.800 series. However, those approaches are costly and cannot be applied to customer data. Therefore, an effective objective assessment approach is needed to evaluate or monitor the speech quality of the ongoing conversation. The ConferencingSpeech 2022 challenge targets the non-intrusive deep neural network models for the speech quality assessment task. We open-sourced a training corpus with more than 86K speech clips in different languages, with a wide range of synthesized and live degradations and their corresponding subjective quality scores through crowdsourcing. 18 teams submitted their models for evaluation in this challenge. The blind test sets included about 4300 clips from wide ranges of degradations. This paper describes the challenge, the datasets, and the evaluation methods and reports the final results.