 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Barriers: Evaluating Cross-Lingual Performance of CNN and Transformer Architectures for Speech Quality Estimation
Feb 18, 2025
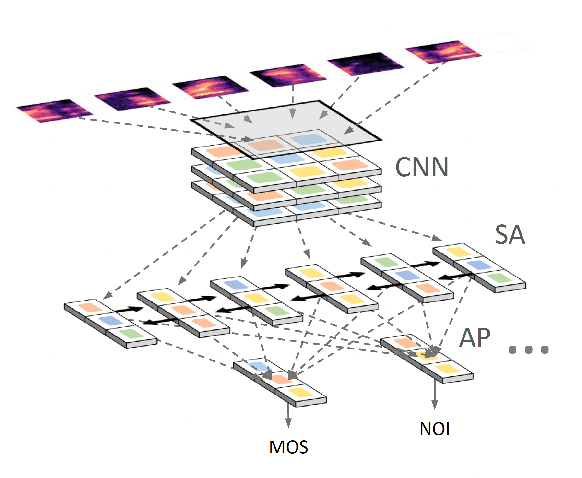
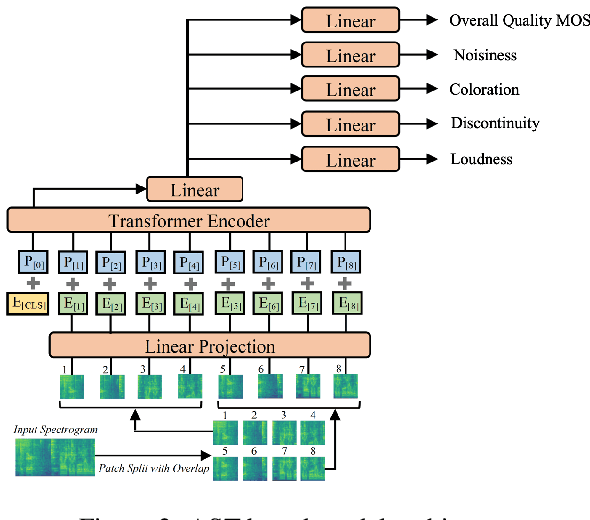

Objective speech quality models aim to predict human-perceived speech quality using automated methods. However, cross-lingual generalization remains a major challenge, as Mean Opinion Scores (MOS) vary across languages due to linguistic, perceptual, and dataset-specific differences. A model trained primarily on English data may struggle to generalize to languages with different phonetic, tonal, and prosodic characteristics, leading to inconsistencies in objective assessments. This study investigates the cross-lingual performance of two speech quality models: NISQA, a CNN-based model, and a Transformer-based Audio Spectrogram Transformer (AST) model. Both models were trained exclusively on English datasets containing over 49,000 speech samples and subsequently evaluated on speech in German, French, Mandarin, Swedish, and Dutch. We analyze model performance using Pearson Correlation Coefficient (PCC) and Root Mean Square Error (RMSE) across five speech quality dimensions: coloration, discontinuity, loudness, noise, and MOS. Our findings show that while AST achieves a more stable cross-lingual performance, both models exhibit noticeable biases. Notably, Mandarin speech quality predictions correlate highly with human MOS scores, whereas Swedish and Dutch present greater prediction challenges. Discontinuities remain difficult to model across all languages. These results highlight the need for more balanced multilingual datasets and architecture-specific adaptations to improve cross-lingual generalization.
Protect and Extend -- Using GANs for Synthetic Data Generation of Time-Series Medical Records
Mar 01, 2024Preservation of private user data is of paramount importance for high Quality of Experience (QoE) and acceptability, particularly with services treating sensitive data, such as IT-based health services. Whereas anonymization techniques were shown to be prone to data re-identification, synthetic data generation has gradually replaced anonymization since it is relatively less time and resource-consuming and more robust to data leakage. Generative Adversarial Networks (GANs) have been used for generating synthetic datasets, especially GAN frameworks adhering to the differential privacy phenomena. This research compares state-of-the-art GAN-based models for synthetic data generation to generate time-series synthetic medical records of dementia patients which can be distributed without privacy concerns. Predictive modeling, autocorrelation, and distribution analysis are used to assess the Quality of Generating (QoG) of the generated data. The privacy preservation of the respective models is assessed by applying membership inference attacks to determine potential data leakage risks. Our experiments indicate the superiority of the privacy-preserving GAN (PPGAN) model over other models regarding privacy preservation while maintaining an acceptable level of QoG. The presented results can support better data protection for medical use cases in the future.