 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Learning of Word and Label Embeddings for Sequence Labelling in Spoken Language Understanding
Oct 16, 2019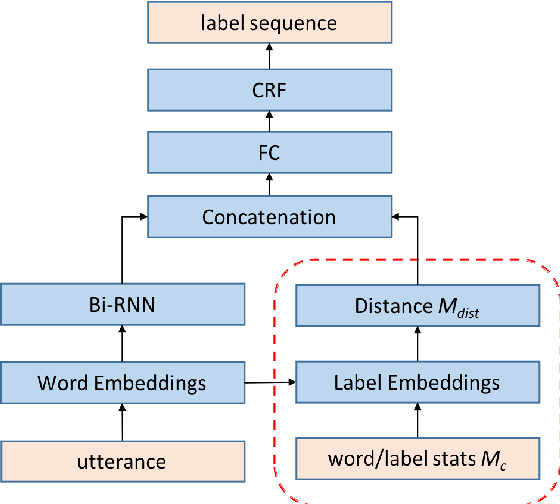
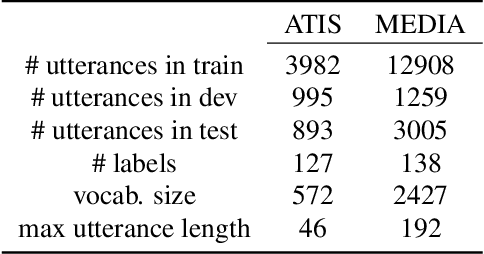
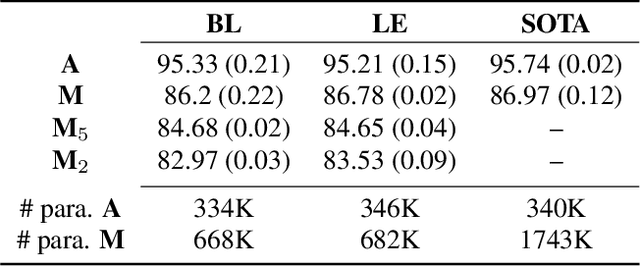

We propose an architecture to jointly learn word and label embeddings for slot filling in spoken language understanding. The proposed approach encodes labels using a combination of word embeddings and straightforward word-label association from the training data. Compared to the state-of-the-art methods, our approach does not require label embeddings as part of the input and therefore lends itself nicely to a wide range of model architectures. In addition, our architecture computes contextual distances between words and labels to avoid adding contextual windows, thus reducing memory footprint. We validate the approach on established spoken dialogue datasets and show that it can achieve state-of-the-art performance with much fewer trainable parameters.
Squeezing bottlenecks: exploring the limits of autoencoder semantic representation capabilities
Feb 13, 2014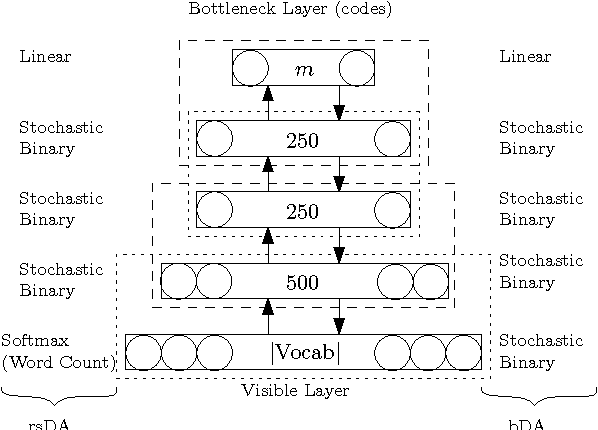
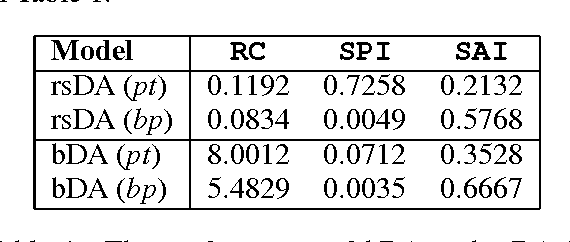
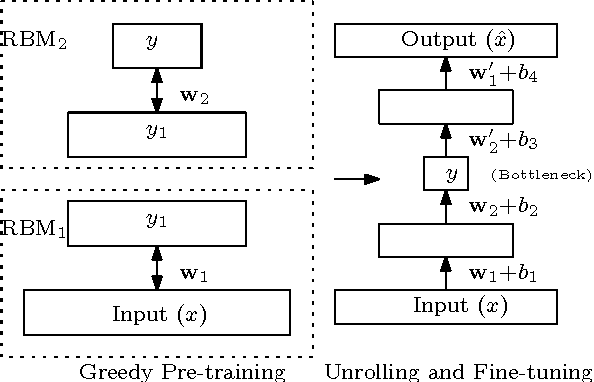
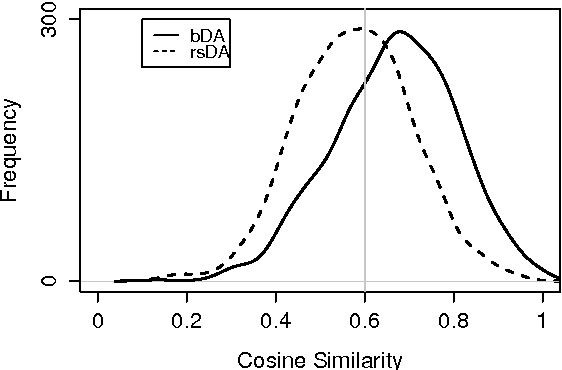
We present a comprehensive study on the use of autoencoders for modelling text data, in which (differently from previous studies) we focus our attention on the following issues: i) we explore the suitability of two different models bDA and rsDA for constructing deep autoencoders for text data at the sentence level; ii) we propose and evaluate two novel metrics for better assessing the text-reconstruction capabilities of autoencoders; and iii) we propose an automatic method to find the critical bottleneck dimensionality for text language representations (below which structural information is lost).
Evaluating Indirect Strategies for Chinese-Spanish Statistical Machine Translation
Feb 04, 2014

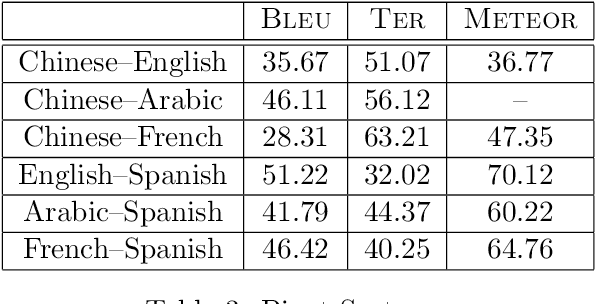
Although, Chinese and Spanish are two of the most spoken languages in the world, not much research has been done in machine translation for this language pair. This paper focuses on investigating the state-of-the-art of Chinese-to-Spanish statistical machine translation (SMT), which nowadays is one of the most popular approaches to machine translation. For this purpose, we report details of the available parallel corpus which are Basic Traveller Expressions Corpus (BTEC), Holy Bible and United Nations (UN). Additionally, we conduct experimental work with the largest of these three corpora to explore alternative SMT strategies by means of using a pivot language. Three alternatives are considered for pivoting: cascading, pseudo-corpus and triangulation. As pivot language, we use either English, Arabic or French. Results show that, for a phrase-based SMT system, English is the best pivot language between Chinese and Spanish. We propose a system output combination using the pivot strategies which is capable of outperforming the direct translation strategy. The main objective of this work is motivating and involving the research community to work in this important pair of languages given their demographic impact.