 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Learning of Word and Label Embeddings for Sequence Labelling in Spoken Language Understanding
Oct 16, 2019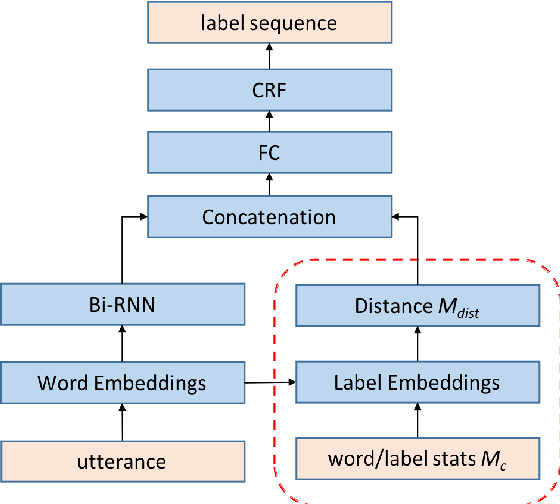
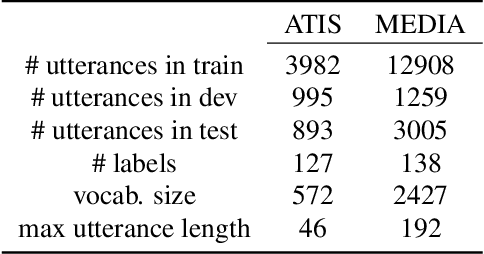
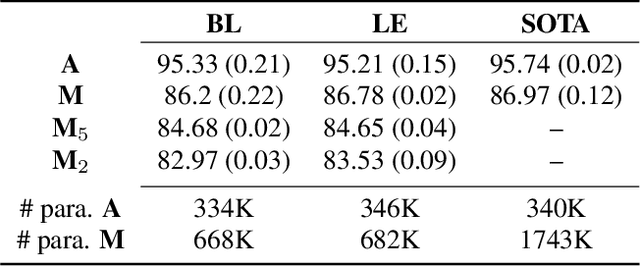

We propose an architecture to jointly learn word and label embeddings for slot filling in spoken language understanding. The proposed approach encodes labels using a combination of word embeddings and straightforward word-label association from the training data. Compared to the state-of-the-art methods, our approach does not require label embeddings as part of the input and therefore lends itself nicely to a wide range of model architectures. In addition, our architecture computes contextual distances between words and labels to avoid adding contextual windows, thus reducing memory footprint. We validate the approach on established spoken dialogue datasets and show that it can achieve state-of-the-art performance with much fewer trainable parameters.
Semantic Explanations of Predictions
May 27, 2018
The main objective of explanations is to transmit knowledge to humans. This work proposes to construct informative explanations for predictions made from machine learning models. Motivated by the observations from social sciences, our approach selects data points from the training sample that exhibit special characteristics crucial for explanation, for instance, ones contrastive to the classification prediction and ones representative of the models. Subsequently, semantic concepts are derived from the selected data points through the use of domain ontologies. These concepts are filtered and ranked to produce informative explanations that improves human understanding. The main features of our approach are that (1) knowledge about explanations is captured in the form of ontological concepts, (2) explanations include contrastive evidences in addition to normal evidences, and (3) explanations are user relevant.