 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Exploitation Bias in Learning to Rank with an Uncertainty-aware Empirical Bayes Approach
May 26, 2023



Ranking is at the core of many artificial intelligence (AI) applications, including search engines, recommender systems, etc. Modern ranking systems are often constructed with learning-to-rank (LTR) models built from user behavior signals. While previous studies have demonstrated the effectiveness of using user behavior signals (e.g., clicks) as both features and labels of LTR algorithms, we argue that existing LTR algorithms that indiscriminately treat behavior and non-behavior signals in input features could lead to suboptimal performance in practice. Particularly because user behavior signals often have strong correlations with the ranking objective and can only be collected on items that have already been shown to users, directly using behavior signals in LTR could create an exploitation bias that hurts the system performance in the long run. To address the exploitation bias, we propose EBRank, an empirical Bayes-based uncertainty-aware ranking algorithm. Specifically, to overcome exploitation bias brought by behavior features in ranking models, EBRank uses a sole non-behavior feature based prior model to get a prior estimation of relevance. In the dynamic training and serving of ranking systems, EBRank uses the observed user behaviors to update posterior relevance estimation instead of concatenating behaviors as features in ranking models. Besides, EBRank additionally applies an uncertainty-aware exploration strategy to explore actively, collect user behaviors for empirical Bayesian modeling and improve ranking performance. Experiments on three public datasets show that EBRank is effective, practical and significantly outperforms state-of-the-art ranking algorithms.
Analysis of E-commerce Ranking Signals via Signal Temporal Logic
Jan 14, 2021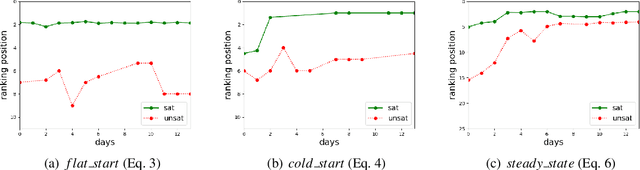
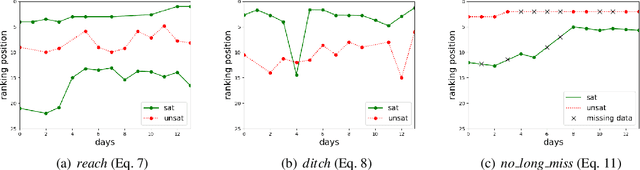
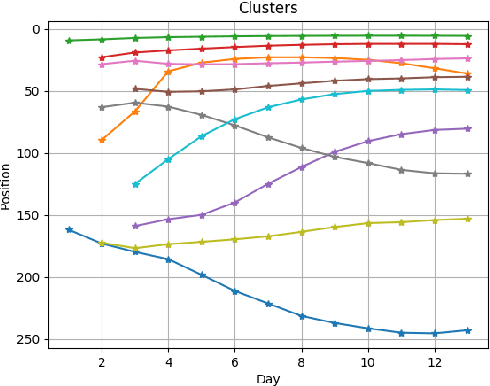
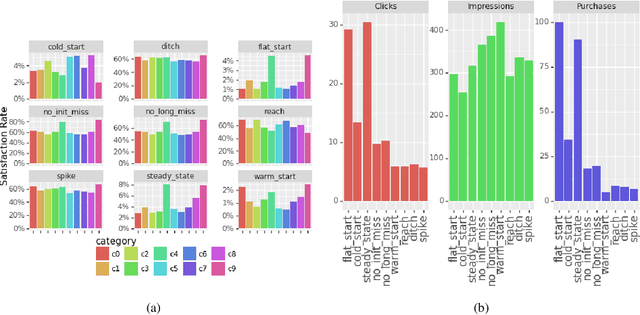
The timed position of documents retrieved by learning to rank models can be seen as signals. Signals carry useful information such as drop or rise of documents over time or user behaviors. In this work, we propose to use the logic formalism called Signal Temporal Logic (STL) to characterize document behaviors in ranking accordingly to the specified formulas. Our analysis shows that interesting document behaviors can be easily formalized and detected thanks to STL formulas. We validate our idea on a dataset of 100K product signals. Through the presented framework, we uncover interesting patterns, such as cold start, warm start, spikes, and inspect how they affect our learning to ranks models.
* In Proceedings SNR 2020, arXiv:2101.05256
Squeezing bottlenecks: exploring the limits of autoencoder semantic representation capabilities
Feb 13, 2014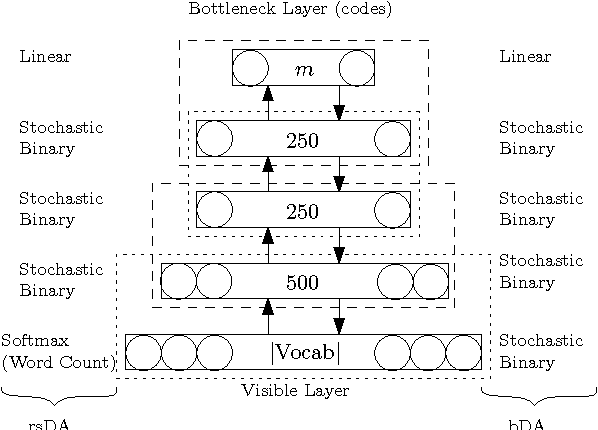
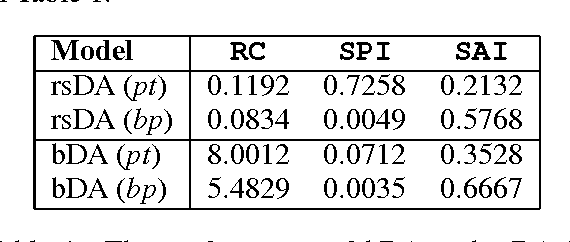
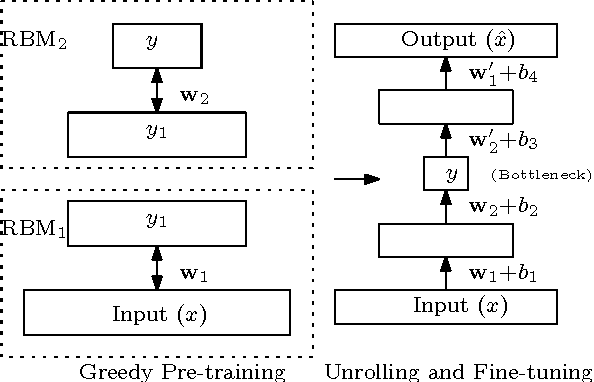
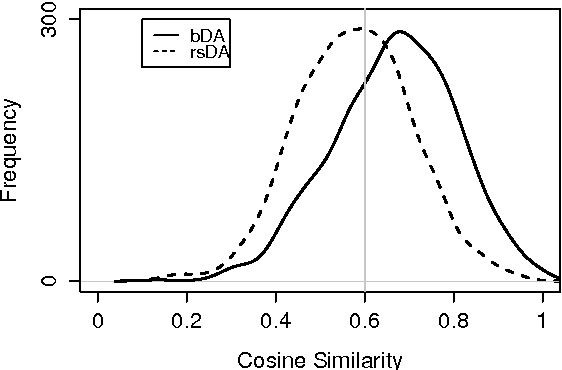
We present a comprehensive study on the use of autoencoders for modelling text data, in which (differently from previous studies) we focus our attention on the following issues: i) we explore the suitability of two different models bDA and rsDA for constructing deep autoencoders for text data at the sentence level; ii) we propose and evaluate two novel metrics for better assessing the text-reconstruction capabilities of autoencoders; and iii) we propose an automatic method to find the critical bottleneck dimensionality for text language representations (below which structural information is lost).