 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemLayer: Semantic-aware Generative Segmentation and Layer Construction for Abstract Icons
Mar 25, 2026Graphic icons are a cornerstone of modern design workflows, yet they are often distributed as flattened single-path or compound-path graphics, where the original semantic layering is lost. This absence of semantic decomposition hinders downstream tasks such as editing, restyling, and animation. We formalize this problem as semantic layer construction for flattened vector art and introduce SemLayer, a visual generation empowered pipeline that restores editable layered structures. Given an abstract icon, SemLayer first generates a chromatically differentiated representation in which distinct semantic components become visually separable. To recover the complete geometry of each part, including occluded regions, we then perform a semantic completion step that reconstructs coherent object-level shapes. Finally, the recovered parts are assembled into a layered vector representation with inferred occlusion relationships. Extensive qualitative comparisons and quantitative evaluations demonstrate the effectiveness of SemLayer, enabling editing workflows previously inapplicable to flattened vector graphics and establishing semantic layer reconstruction as a practical and valuable task. Project page: https://xxuhaiyang.github.io/SemLayer/
Rethinking Output Alignment For 1-bit Post-Training Quantization of Large Language Models
Dec 25, 2025Large Language Models (LLMs) deliver strong performance across a wide range of NLP tasks, but their massive sizes hinder deployment on resource-constrained devices. To reduce their computational and memory burden, various compression techniques have been proposed, including quantization, pruning, and knowledge distillation. Among these, post-training quantization (PTQ) is widely adopted for its efficiency, as it requires no retraining and only a small dataset for calibration, enabling low-cost deployment. Recent advances for post-training quantization have demonstrated that even sub-4-bit methods can maintain most of the original model performance. However, 1-bit quantization that converts floating-point weights to \(\pm\)1, remains particularly challenging, as existing 1-bit PTQ methods often suffer from significant performance degradation compared to the full-precision models. Specifically, most of existing 1-bit PTQ approaches focus on weight alignment, aligning the full-precision model weights with those of the quantized models, rather than directly aligning their outputs. Although the output-matching approach objective is more intuitive and aligns with the quantization goal, naively applying it in 1-bit LLMs often leads to notable performance degradation. In this paper, we investigate why and under what conditions output-matching fails, in the context of 1-bit LLM quantization. Based on our findings, we propose a novel data-aware PTQ approach for 1-bit LLMs that explicitly accounts for activation error accumulation while keeping optimization efficient. Empirical experiments demonstrate that our solution consistently outperforms existing 1-bit PTQ methods with minimal overhead.
SweeperBot: Making 3D Browsing Accessible through View Analysis and Visual Question Answering
Nov 19, 2025Accessing 3D models remains challenging for Screen Reader (SR) users. While some existing 3D viewers allow creators to provide alternative text, they often lack sufficient detail about the 3D models. Grounded on a formative study, this paper introduces SweeperBot, a system that enables SR users to leverage visual question answering to explore and compare 3D models. SweeperBot answers SR users' visual questions by combining an optimal view selection technique with the strength of generative- and recognition-based foundation models. An expert review with 10 Blind and Low-Vision (BLV) users with SR experience demonstrated the feasibility of using SweeperBot to assist BLV users in exploring and comparing 3D models. The quality of the descriptions generated by SweeperBot was validated by a second survey study with 30 sighted participants.
VRAE: Vertical Residual Autoencoder for License Plate Denoising and Deblurring
Sep 11, 2025In real-world traffic surveillance, vehicle images captured under adverse weather, poor lighting, or high-speed motion often suffer from severe noise and blur. Such degradations significantly reduce the accuracy of license plate recognition systems, especially when the plate occupies only a small region within the full vehicle image. Restoring these degraded images a fast realtime manner is thus a crucial pre-processing step to enhance recognition performance. In this work, we propose a Vertical Residual Autoencoder (VRAE) architecture designed for the image enhancement task in traffic surveillance. The method incorporates an enhancement strategy that employs an auxiliary block, which injects input-aware features at each encoding stage to guide the representation learning process, enabling better general information preservation throughout the network compared to conventional autoencoders. Experiments on a vehicle image dataset with visible license plates demonstrate that our method consistently outperforms Autoencoder (AE), Generative Adversarial Network (GAN), and Flow-Based (FB) approaches. Compared with AE at the same depth, it improves PSNR by about 20%, reduces NMSE by around 50%, and enhances SSIM by 1%, while requiring only a marginal increase of roughly 1% in parameters.
Coverage-Constrained Human-AI Cooperation with Multiple Experts
Nov 18, 2024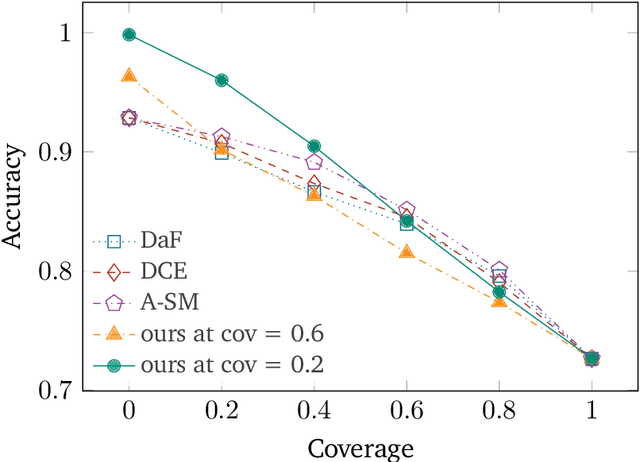

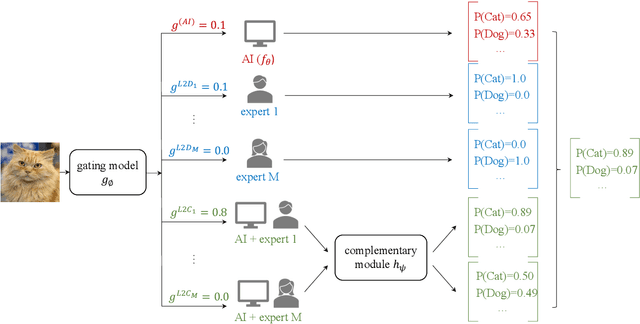
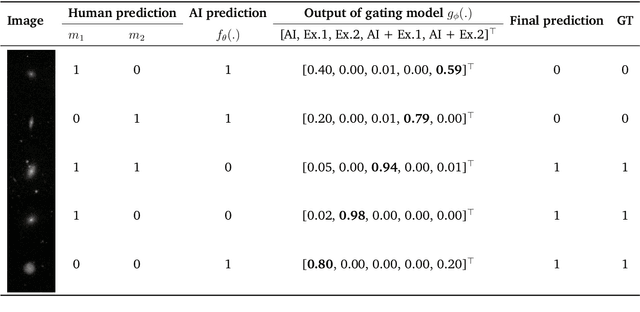
Human-AI cooperative classification (HAI-CC) approaches aim to develop hybrid intelligent systems that enhance decision-making in various high-stakes real-world scenarios by leveraging both human expertise and AI capabilities. Current HAI-CC methods primarily focus on learning-to-defer (L2D), where decisions are deferred to human experts, and learning-to-complement (L2C), where AI and human experts make predictions cooperatively. However, a notable research gap remains in effectively exploring both L2D and L2C under diverse expert knowledge to improve decision-making, particularly when constrained by the cooperation cost required to achieve a target probability for AI-only selection (i.e., coverage). In this paper, we address this research gap by proposing the Coverage-constrained Learning to Defer and Complement with Specific Experts (CL2DC) method. CL2DC makes final decisions through either AI prediction alone or by deferring to or complementing a specific expert, depending on the input data. Furthermore, we propose a coverage-constrained optimisation to control the cooperation cost, ensuring it approximates a target probability for AI-only selection. This approach enables an effective assessment of system performance within a specified budget. Also, CL2DC is designed to address scenarios where training sets contain multiple noisy-label annotations without any clean-label references. Comprehensive evaluations on both synthetic and real-world datasets demonstrate that CL2DC achieves superior performance compared to state-of-the-art HAI-CC methods.
Multi-omics Prediction from High-content Cellular Imaging with Deep Learning
Jun 19, 2023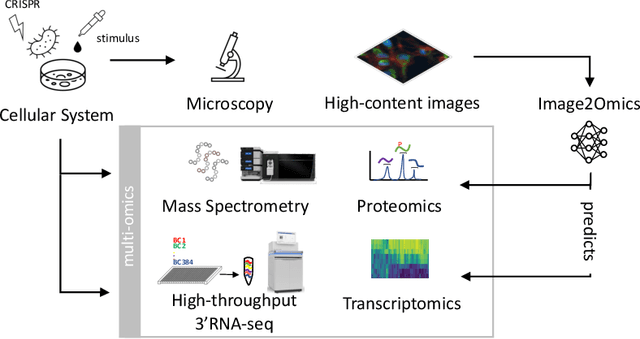
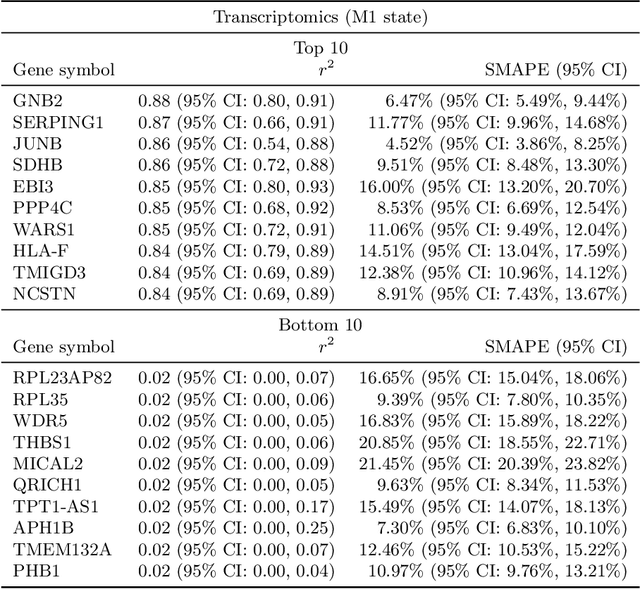
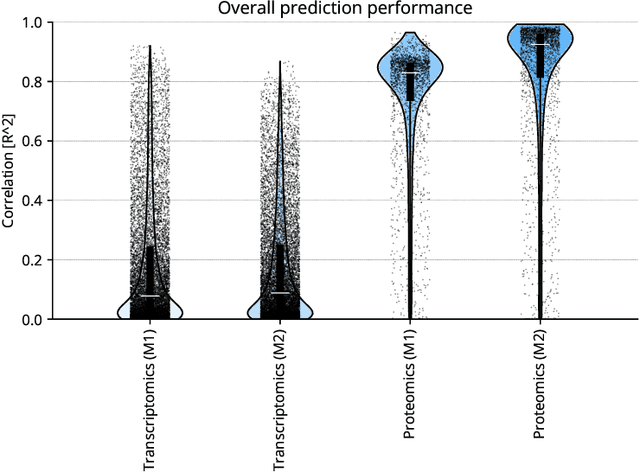
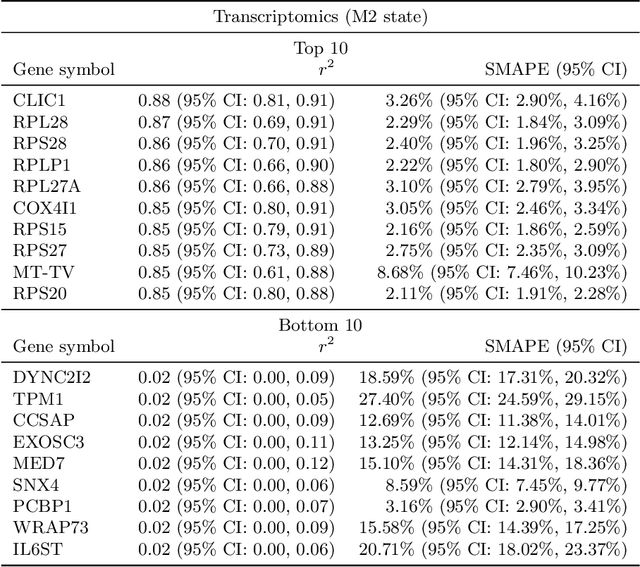
High-content cellular imaging, transcriptomics, and proteomics data provide rich and complementary views on the molecular layers of biology that influence cellular states and function. However, the biological determinants through which changes in multi-omics measurements influence cellular morphology have not yet been systematically explored, and the degree to which cell imaging could potentially enable the prediction of multi-omics directly from cell imaging data is therefore currently unclear. Here, we address the question of whether it is possible to predict bulk multi-omics measurements directly from cell images using Image2Omics -- a deep learning approach that predicts multi-omics in a cell population directly from high-content images stained with multiplexed fluorescent dyes. We perform an experimental evaluation in gene-edited macrophages derived from human induced pluripotent stem cell (hiPSC) under multiple stimulation conditions and demonstrate that Image2Omics achieves significantly better performance in predicting transcriptomics and proteomics measurements directly from cell images than predictors based on the mean observed training set abundance. We observed significant predictability of abundances for 5903 (22.43%; 95% CI: 8.77%, 38.88%) and 5819 (22.11%; 95% CI: 10.40%, 38.08%) transcripts out of 26137 in M1 and M2-stimulated macrophages respectively and for 1933 (38.77%; 95% CI: 36.94%, 39.85%) and 2055 (41.22%; 95% CI: 39.31%, 42.42%) proteins out of 4986 in M1 and M2-stimulated macrophages respectively. Our results show that some transcript and protein abundances are predictable from cell imaging and that cell imaging may potentially, in some settings and depending on the mechanisms of interest and desired performance threshold, even be a scalable and resource-efficient substitute for multi-omics measurements.
Noisy-label Learning with Sample Selection based on Noise Rate Estimate
May 31, 2023Noisy-labels are challenging for deep learning due to the high capacity of the deep models that can overfit noisy-label training samples. Arguably the most realistic and coincidentally challenging type of label noise is the instance-dependent noise (IDN), where the labelling errors are caused by the ambivalent information present in the images. The most successful label noise learning techniques to address IDN problems usually contain a noisy-label sample selection stage to separate clean and noisy-label samples during training. Such sample selection depends on a criterion, such as loss or gradient, and on a curriculum to define the proportion of training samples to be classified as clean at each training epoch. Even though the estimated noise rate from the training set appears to be a natural signal to be used in the definition of this curriculum, previous approaches generally rely on arbitrary thresholds or pre-defined selection functions to the best of our knowledge. This paper addresses this research gap by proposing a new noisy-label learning graphical model that can easily accommodate state-of-the-art (SOTA) noisy-label learning methods and provide them with a reliable noise rate estimate to be used in a new sample selection curriculum. We show empirically that our model integrated with many SOTA methods can improve their results in many IDN benchmarks, including synthetic and real-world datasets.
PASS: Peer-Agreement based Sample Selection for training with Noisy Labels
Mar 20, 2023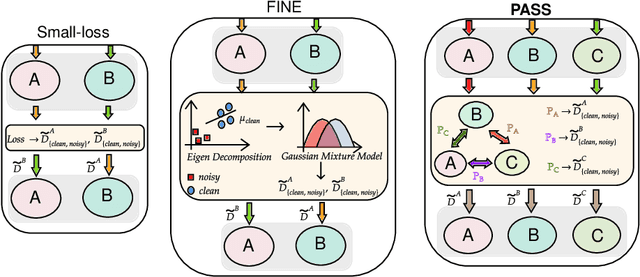
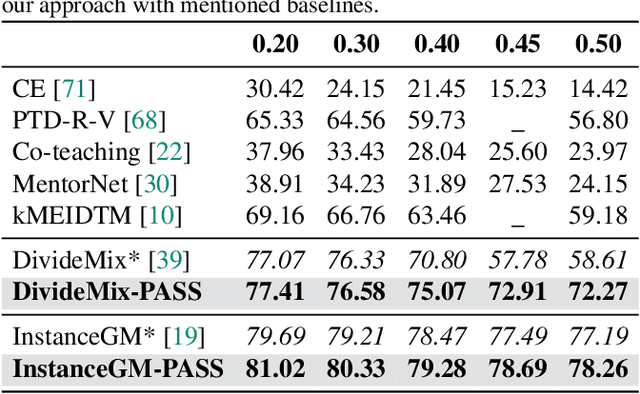

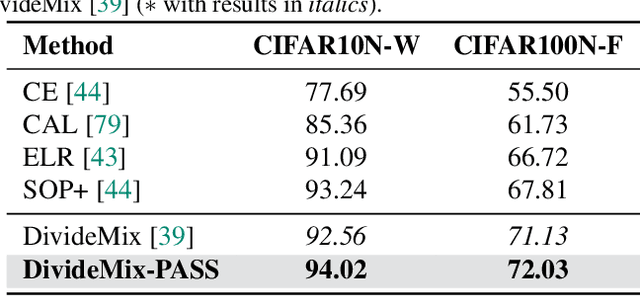
Noisy labels present a significant challenge in deep learning because models are prone to overfitting. This problem has driven the development of sophisticated techniques to address the issue, with one critical component being the selection of clean and noisy label samples. Selecting noisy label samples is commonly based on the small-loss hypothesis or on feature-based sampling, but we present empirical evidence that shows that both strategies struggle to differentiate between noisy label and hard samples, resulting in relatively large proportions of samples falsely selected as clean. To address this limitation, we propose a novel peer-agreement based sample selection (PASS). An automated thresholding technique is then applied to the agreement score to select clean and noisy label samples. PASS is designed to be easily integrated into existing noisy label robust frameworks, and it involves training a set of classifiers in a round-robin fashion, with peer models used for sample selection. In the experiments, we integrate our PASS with several state-of-the-art (SOTA) models, including InstanceGM, DivideMix, SSR, FaMUS, AugDesc, and C2D, and evaluate their effectiveness on several noisy label benchmark datasets, such as CIFAR-100, CIFAR-N, Animal-10N, Red Mini-Imagenet, Clothing1M, Mini-Webvision, and Imagenet. Our results demonstrate that our new sample selection approach improves the existing SOTA results of algorithms.
Task Weighting in Meta-learning with Trajectory Optimisation
Jan 04, 2023Developing meta-learning algorithms that are un-biased toward a subset of training tasks often requires hand-designed criteria to weight tasks, potentially resulting in sub-optimal solutions. In this paper, we introduce a new principled and fully-automated task-weighting algorithm for meta-learning methods. By considering the weights of tasks within the same mini-batch as an action, and the meta-parameter of interest as the system state, we cast the task-weighting meta-learning problem to a trajectory optimisation and employ the iterative linear quadratic regulator to determine the optimal action or weights of tasks. We theoretically show that the proposed algorithm converges to an $\epsilon_{0}$-stationary point, and empirically demonstrate that the proposed approach out-performs common hand-engineering weighting methods in two few-shot learning benchmarks.
Towards the Identifiability in Noisy Label Learning: A Multinomial Mixture Approach
Jan 04, 2023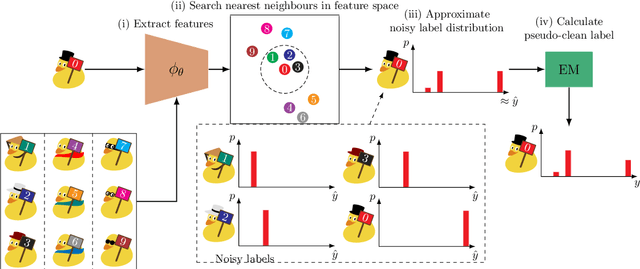
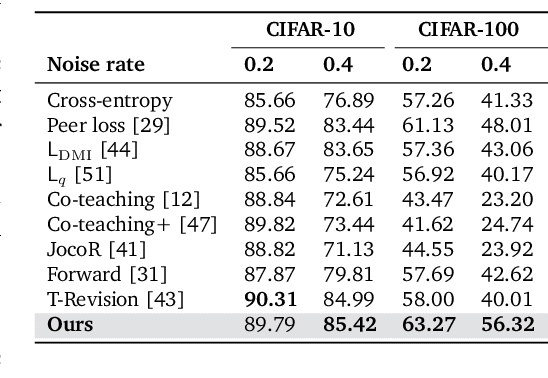
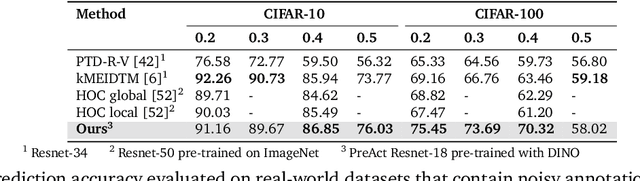
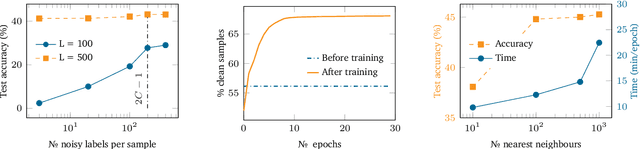
Learning from noisy labels plays an important role in the deep learning era. Despite numerous studies with promising results, identifying clean labels from a noisily-annotated dataset is still challenging since the conventional noisy label learning problem with single noisy label per instance is not identifiable, i.e., it does not theoretically have a unique solution unless one has access to clean labels or introduces additional assumptions. This paper aims to formally investigate such identifiability issue by formulating the noisy label learning problem as a multinomial mixture model, enabling the formulation of the identifiability constraint. In particular, we prove that the noisy label learning problem is identifiable if there are at least $2C - 1$ noisy labels per instance provided, with $C$ being the number of classes. In light of such requirement, we propose a method that automatically generates additional noisy labels per training sample by estimating the noisy label distribution based on nearest neighbours. Such additional noisy labels allow us to apply the Expectation - Maximisation algorithm to estimate the posterior of clean labels. We empirically demonstrate that the proposed method is not only capable of estimating clean labels without any heuristics in several challenging label noise benchmarks, including synthetic, web-controlled and real-world label noises, but also of performing competitively with many state-of-the-art methods.