 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask the Target: A Plug-and-Play Regularizer Against LoRA Forgetting
May 28, 2026Low-Rank Adaptation (LoRA) has become one of the most widely used fine-tuning mechanisms for adapting large language models to new domains, tasks, and users. Yet adaptation performance alone can obscure an important failure mode: LoRA updates may improve performance on the target distribution while degrading prior capabilities learned during pretraining and alignment. We show that this forgetting becomes especially severe when the adaptation distribution differs substantially from the models original training or alignment distributions. The challenge is amplified in practical settings, where the original training and alignment data are typically unavailable. Motivated by this constraint, we study how LoRA based adaptation balances new learning against forgetting in a replay-free setting, and introduce a simple output space regularizer that can be added directly to existing training pipelines. Our method removes the ground-truth token from both the base and adapted model distributions, renormalizes the remaining probabilities, and applies KL regularization only over the non-target vocabulary. This preserves the base models relative preferences among alternative tokens without directly opposing the cross-entropy signal required for adaptation. As the regularizer acts only at the loss level, it requires no replay data, architectural changes, adapter redesign, or inference-time overhead, and can be applied directly to existing LoRA variants. Across all LoRA variants tested and across various backbones, our method improves the frontier between new learning and forgetting when the adaptation distribution differs substantially from the base models original training or alignment distributions, suggesting a broadly applicable route toward more reliable LLM updating.
STRIDE: Training-Free Diversity Guidance via PCA-Directed Feature Perturbation in Single-Step Diffusion Models
May 12, 2026Distilled one-step (T=1) or few-step (T$\leq$4) diffusion models enable real-time image generation but often exhibit reduced sample diversity compared to their multi-step counterparts. In multi-step diffusion, diversity can be introduced through schedules, trajectories, or iterative optimization; however, these mechanisms are unavailable in the few-step or single-step setting, limiting the effectiveness of existing diversity-enhancing methods. A natural alternative is to perturb intermediate features, but naive feature perturbation is often ineffective, either yielding limited diversity gains or degrading generation quality. We argue that effective diversity injection in few-step models requires perturbations that respect the model's learned feature geometry. Based on this insight, we propose STRIDE, a training-free and optimization-free method that operates in a single forward pass. STRIDE injects spatially coherent (pink) noise into intermediate transformer features, projected onto the principal components of the model's own activations, ensuring that perturbations lie on the learned feature manifold. This design enables controlled variation along meaningful directions in the representation space. Extensive experiments on FLUX.1-schnell and SD3.5 Turbo across COCO, DrawBench, PartiPrompts, and GenEval show that STRIDE consistently improves diversity while maintaining strong text alignment. In particular, STRIDE reduces intra-batch similarity with minimal impact on CLIP score, and Pareto-dominates existing training-free baselines on the diversity-fidelity frontier. These results highlight that, in the absence of iterative refinement, improving diversity in few-step and one-step diffusion depends not on increasing perturbation strength, but on aligning perturbations with the model's internal representation structure.
Noisy-label Learning with Sample Selection based on Noise Rate Estimate
May 31, 2023Noisy-labels are challenging for deep learning due to the high capacity of the deep models that can overfit noisy-label training samples. Arguably the most realistic and coincidentally challenging type of label noise is the instance-dependent noise (IDN), where the labelling errors are caused by the ambivalent information present in the images. The most successful label noise learning techniques to address IDN problems usually contain a noisy-label sample selection stage to separate clean and noisy-label samples during training. Such sample selection depends on a criterion, such as loss or gradient, and on a curriculum to define the proportion of training samples to be classified as clean at each training epoch. Even though the estimated noise rate from the training set appears to be a natural signal to be used in the definition of this curriculum, previous approaches generally rely on arbitrary thresholds or pre-defined selection functions to the best of our knowledge. This paper addresses this research gap by proposing a new noisy-label learning graphical model that can easily accommodate state-of-the-art (SOTA) noisy-label learning methods and provide them with a reliable noise rate estimate to be used in a new sample selection curriculum. We show empirically that our model integrated with many SOTA methods can improve their results in many IDN benchmarks, including synthetic and real-world datasets.
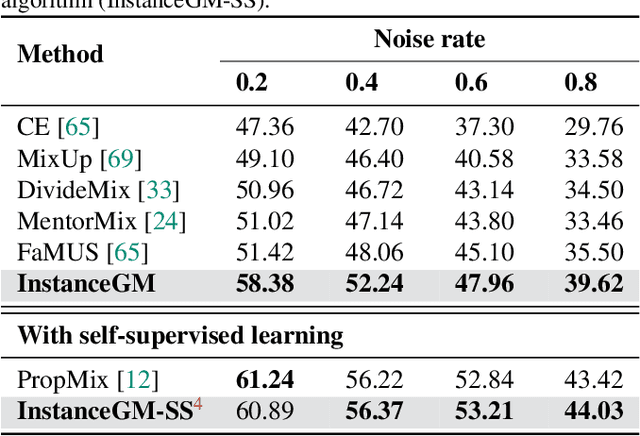
PASS: Peer-Agreement based Sample Selection for training with Noisy Labels
Mar 20, 2023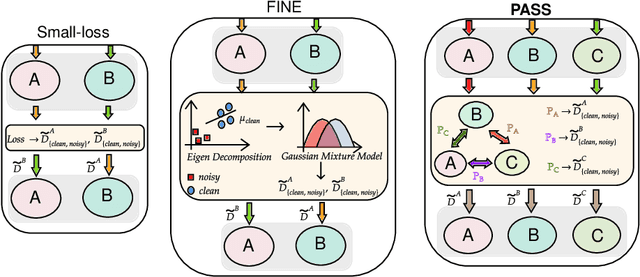
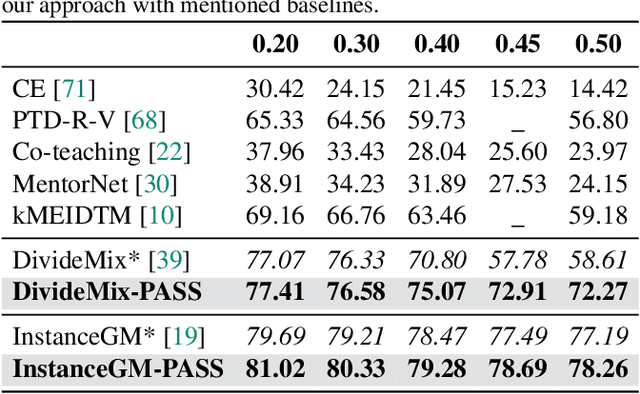

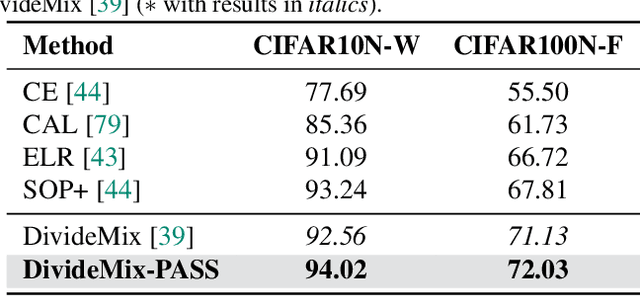
Noisy labels present a significant challenge in deep learning because models are prone to overfitting. This problem has driven the development of sophisticated techniques to address the issue, with one critical component being the selection of clean and noisy label samples. Selecting noisy label samples is commonly based on the small-loss hypothesis or on feature-based sampling, but we present empirical evidence that shows that both strategies struggle to differentiate between noisy label and hard samples, resulting in relatively large proportions of samples falsely selected as clean. To address this limitation, we propose a novel peer-agreement based sample selection (PASS). An automated thresholding technique is then applied to the agreement score to select clean and noisy label samples. PASS is designed to be easily integrated into existing noisy label robust frameworks, and it involves training a set of classifiers in a round-robin fashion, with peer models used for sample selection. In the experiments, we integrate our PASS with several state-of-the-art (SOTA) models, including InstanceGM, DivideMix, SSR, FaMUS, AugDesc, and C2D, and evaluate their effectiveness on several noisy label benchmark datasets, such as CIFAR-100, CIFAR-N, Animal-10N, Red Mini-Imagenet, Clothing1M, Mini-Webvision, and Imagenet. Our results demonstrate that our new sample selection approach improves the existing SOTA results of algorithms.
Instance-Dependent Noisy Label Learning via Graphical Modelling
Sep 02, 2022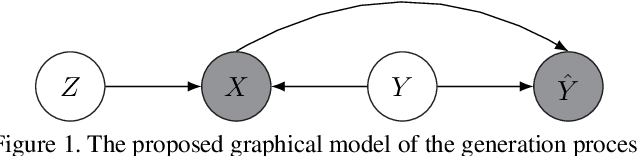
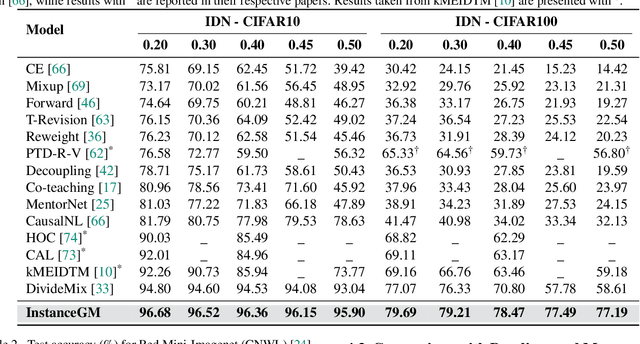
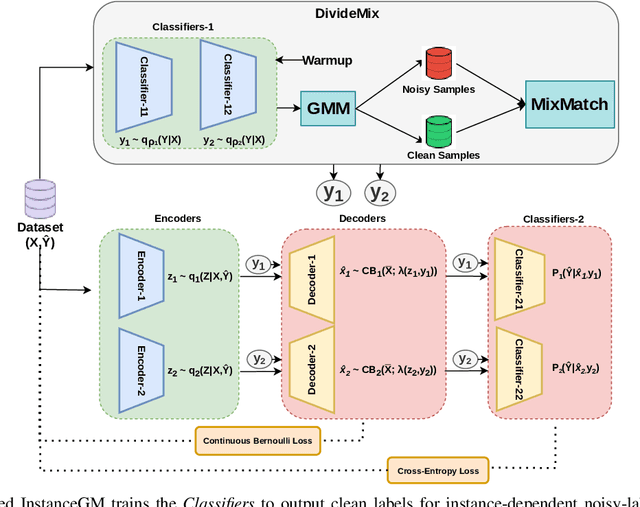
Noisy labels are unavoidable yet troublesome in the ecosystem of deep learning because models can easily overfit them. There are many types of label noise, such as symmetric, asymmetric and instance-dependent noise (IDN), with IDN being the only type that depends on image information. Such dependence on image information makes IDN a critical type of label noise to study, given that labelling mistakes are caused in large part by insufficient or ambiguous information about the visual classes present in images. Aiming to provide an effective technique to address IDN, we present a new graphical modelling approach called InstanceGM, that combines discriminative and generative models. The main contributions of InstanceGM are: i) the use of the continuous Bernoulli distribution to train the generative model, offering significant training advantages, and ii) the exploration of a state-of-the-art noisy-label discriminative classifier to generate clean labels from instance-dependent noisy-label samples. InstanceGM is competitive with current noisy-label learning approaches, particularly in IDN benchmarks using synthetic and real-world datasets, where our method shows better accuracy than the competitors in most experiments.
PeR-ViS: Person Retrieval in Video Surveillance using Semantic Description
Dec 04, 2020
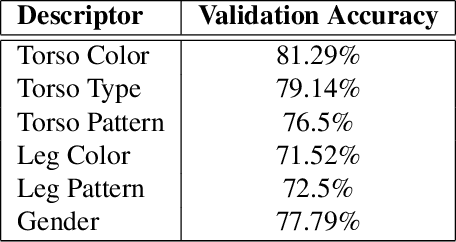
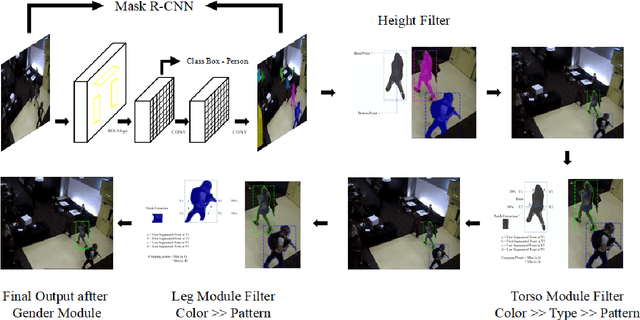
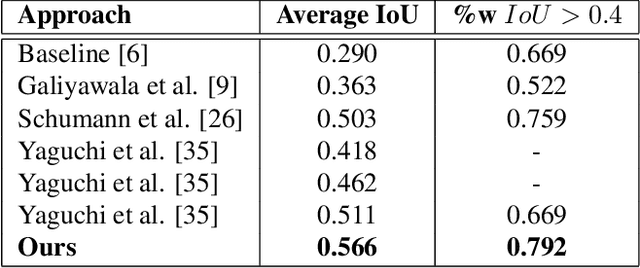
A person is usually characterized by descriptors like age, gender, height, cloth type, pattern, color, etc. Such descriptors are known as attributes and/or soft-biometrics. They link the semantic gap between a person's description and retrieval in video surveillance. Retrieving a specific person with the query of semantic description has an important application in video surveillance. Using computer vision to fully automate the person retrieval task has been gathering interest within the research community. However, the Current, trend mainly focuses on retrieving persons with image-based queries, which have major limitations for practical usage. Instead of using an image query, in this paper, we study the problem of person retrieval in video surveillance with a semantic description. To solve this problem, we develop a deep learning-based cascade filtering approach (PeR-ViS), which uses Mask R-CNN [14] (person detection and instance segmentation) and DenseNet-161 [16] (soft-biometric classification). On the standard person retrieval dataset of SoftBioSearch [6], we achieve 0.566 Average IoU and 0.792 %w $IoU > 0.4$, surpassing the current state-of-the-art by a large margin. We hope our simple, reproducible, and effective approach will help ease future research in the domain of person retrieval in video surveillance. The source code and pretrained weights available at https://parshwa1999.github.io/PeR-ViS/.
Defensive Escort Teams via Multi-Agent Deep Reinforcement Learning
Oct 09, 2019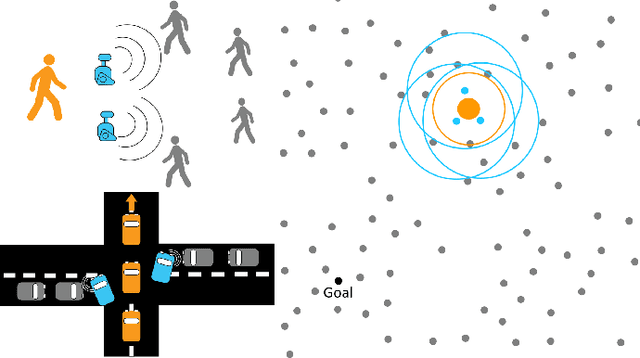
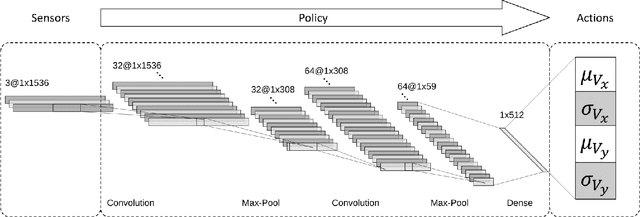
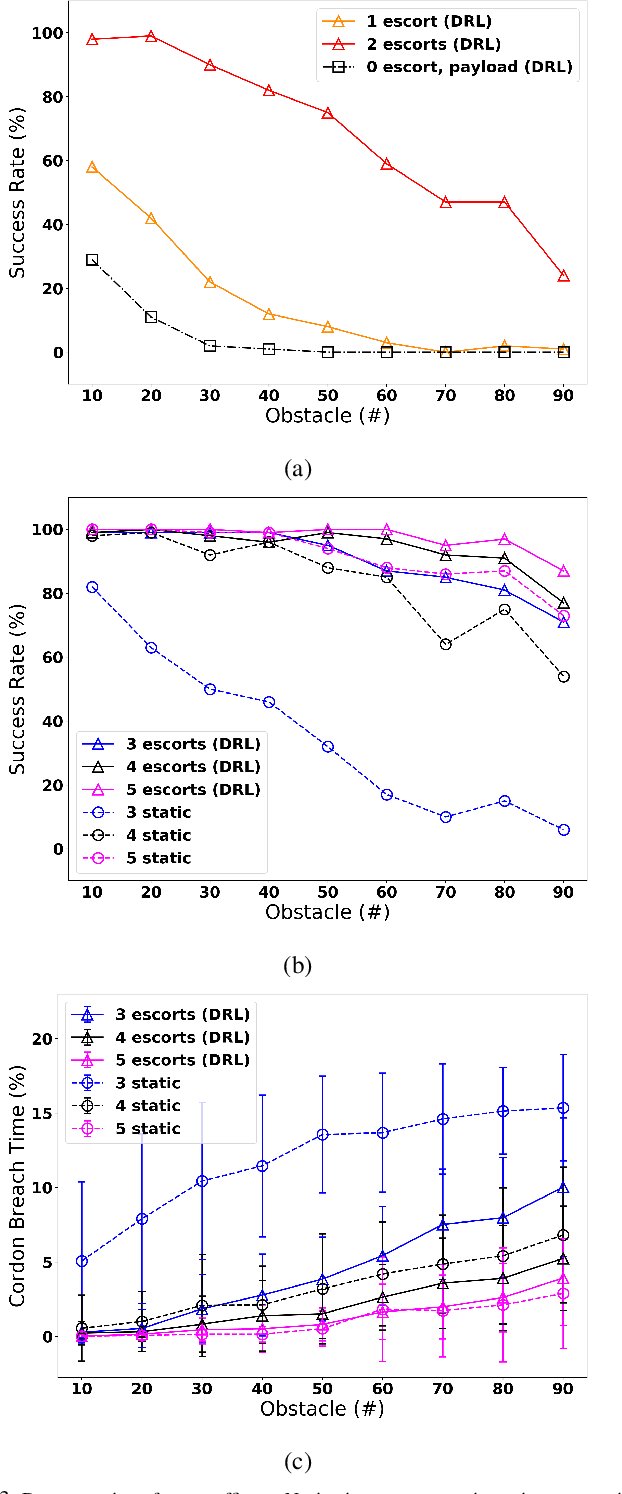
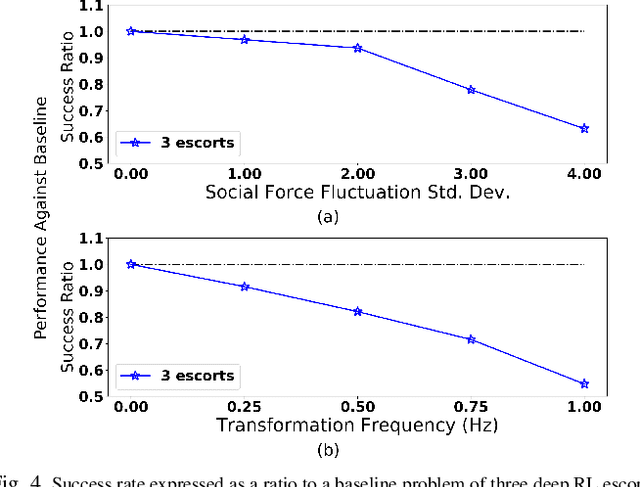
Coordinated defensive escorts can aid a navigating payload by positioning themselves in order to maintain the safety of the payload from obstacles. In this paper, we present a novel, end-to-end solution for coordinating an escort team for protecting high-value payloads. Our solution employs deep reinforcement learning (RL) in order to train a team of escorts to maintain payload safety while navigating alongside the payload. This is done in a distributed fashion, relying only on limited range positional information of other escorts, the payload, and the obstacles. When compared to a state-of-art algorithm for obstacle avoidance, our solution with a single escort increases navigation success up to 31%. Additionally, escort teams increase success rate by up to 75% percent over escorts in static formations. We also show that this learned solution is general to several adaptations in the scenario including: a changing number of escorts in the team, changing obstacle density, and changes in payload conformation. Video: https://youtu.be/SoYesKti4VA.