 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Feature Adjustment for Semi-supervised Learning from Pretrained Models
Sep 09, 2023As an effective way to alleviate the burden of data annotation, semi-supervised learning (SSL) provides an attractive solution due to its ability to leverage both labeled and unlabeled data to build a predictive model. While significant progress has been made recently, SSL algorithms are often evaluated and developed under the assumption that the network is randomly initialized. This is in sharp contrast to most vision recognition systems that are built from fine-tuning a pretrained network for better performance. While the marriage of SSL and a pretrained model seems to be straightforward, recent literature suggests that naively applying state-of-the-art SSL with a pretrained model fails to unleash the full potential of training data. In this paper, we postulate the underlying reason is that the pretrained feature representation could bring a bias inherited from the source data, and the bias tends to be magnified through the self-training process in a typical SSL algorithm. To overcome this issue, we propose to use pseudo-labels from the unlabelled data to update the feature extractor that is less sensitive to incorrect labels and only allow the classifier to be trained from the labeled data. More specifically, we progressively adjust the feature extractor to ensure its induced feature distribution maintains a good class separability even under strong input perturbation. Through extensive experimental studies, we show that the proposed approach achieves superior performance over existing solutions.
Noisy-label Learning with Sample Selection based on Noise Rate Estimate
May 31, 2023Noisy-labels are challenging for deep learning due to the high capacity of the deep models that can overfit noisy-label training samples. Arguably the most realistic and coincidentally challenging type of label noise is the instance-dependent noise (IDN), where the labelling errors are caused by the ambivalent information present in the images. The most successful label noise learning techniques to address IDN problems usually contain a noisy-label sample selection stage to separate clean and noisy-label samples during training. Such sample selection depends on a criterion, such as loss or gradient, and on a curriculum to define the proportion of training samples to be classified as clean at each training epoch. Even though the estimated noise rate from the training set appears to be a natural signal to be used in the definition of this curriculum, previous approaches generally rely on arbitrary thresholds or pre-defined selection functions to the best of our knowledge. This paper addresses this research gap by proposing a new noisy-label learning graphical model that can easily accommodate state-of-the-art (SOTA) noisy-label learning methods and provide them with a reliable noise rate estimate to be used in a new sample selection curriculum. We show empirically that our model integrated with many SOTA methods can improve their results in many IDN benchmarks, including synthetic and real-world datasets.
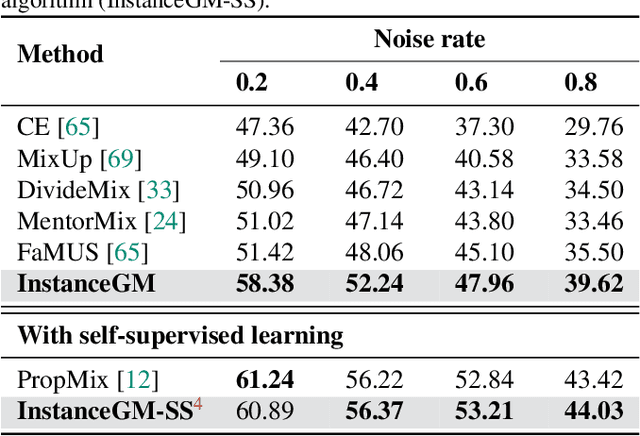
PASS: Peer-Agreement based Sample Selection for training with Noisy Labels
Mar 20, 2023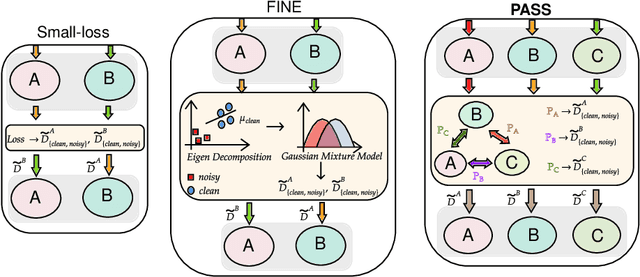
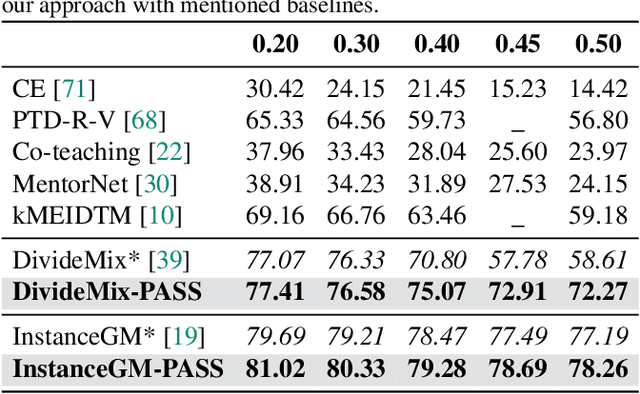

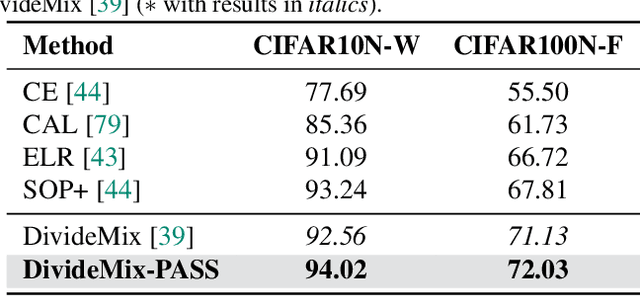
Noisy labels present a significant challenge in deep learning because models are prone to overfitting. This problem has driven the development of sophisticated techniques to address the issue, with one critical component being the selection of clean and noisy label samples. Selecting noisy label samples is commonly based on the small-loss hypothesis or on feature-based sampling, but we present empirical evidence that shows that both strategies struggle to differentiate between noisy label and hard samples, resulting in relatively large proportions of samples falsely selected as clean. To address this limitation, we propose a novel peer-agreement based sample selection (PASS). An automated thresholding technique is then applied to the agreement score to select clean and noisy label samples. PASS is designed to be easily integrated into existing noisy label robust frameworks, and it involves training a set of classifiers in a round-robin fashion, with peer models used for sample selection. In the experiments, we integrate our PASS with several state-of-the-art (SOTA) models, including InstanceGM, DivideMix, SSR, FaMUS, AugDesc, and C2D, and evaluate their effectiveness on several noisy label benchmark datasets, such as CIFAR-100, CIFAR-N, Animal-10N, Red Mini-Imagenet, Clothing1M, Mini-Webvision, and Imagenet. Our results demonstrate that our new sample selection approach improves the existing SOTA results of algorithms.
Instance-Dependent Noisy Label Learning via Graphical Modelling
Sep 02, 2022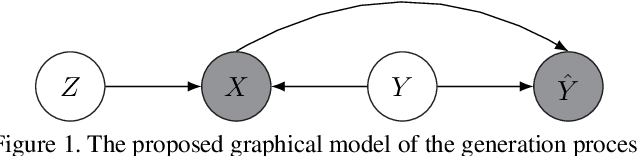
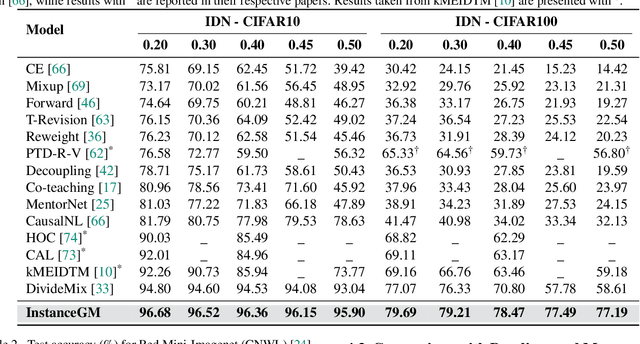
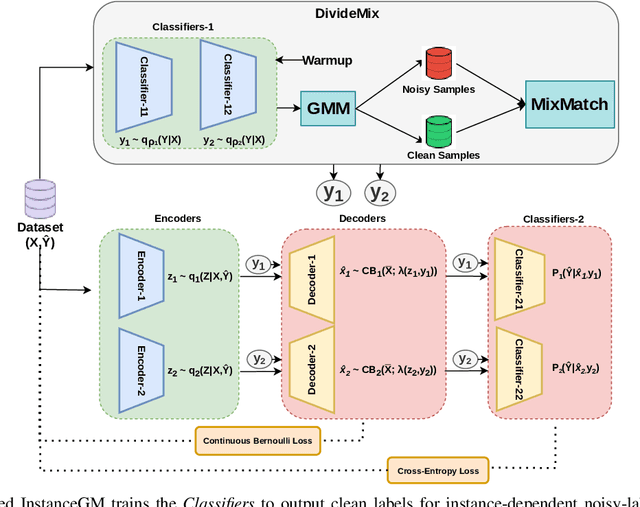
Noisy labels are unavoidable yet troublesome in the ecosystem of deep learning because models can easily overfit them. There are many types of label noise, such as symmetric, asymmetric and instance-dependent noise (IDN), with IDN being the only type that depends on image information. Such dependence on image information makes IDN a critical type of label noise to study, given that labelling mistakes are caused in large part by insufficient or ambiguous information about the visual classes present in images. Aiming to provide an effective technique to address IDN, we present a new graphical modelling approach called InstanceGM, that combines discriminative and generative models. The main contributions of InstanceGM are: i) the use of the continuous Bernoulli distribution to train the generative model, offering significant training advantages, and ii) the exploration of a state-of-the-art noisy-label discriminative classifier to generate clean labels from instance-dependent noisy-label samples. InstanceGM is competitive with current noisy-label learning approaches, particularly in IDN benchmarks using synthetic and real-world datasets, where our method shows better accuracy than the competitors in most experiments.
Generalised Zero-Shot Learning with Domain Classification in a Joint Semantic and Visual Space
Aug 14, 2019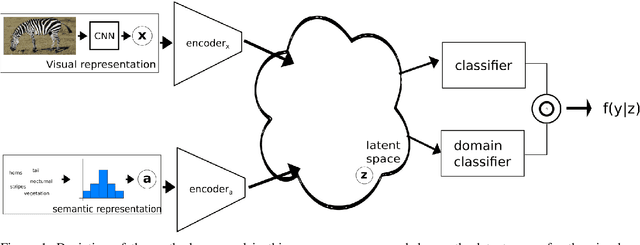
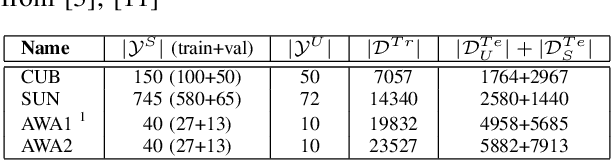
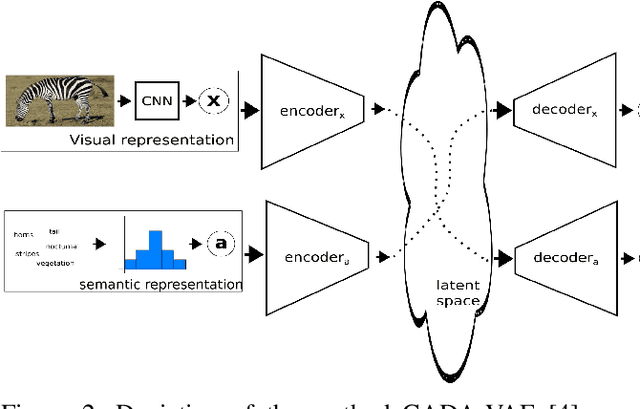
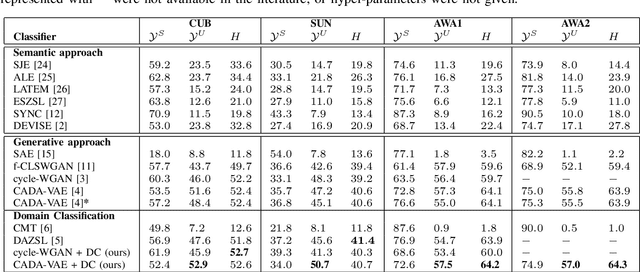
Generalised zero-shot learning (GZSL) is a classification problem where the learning stage relies on a set of seen visual classes and the inference stage aims to identify both the seen visual classes and a new set of unseen visual classes. Critically, both the learning and inference stages can leverage a semantic representation that is available for the seen and unseen classes. Most state-of-the-art GZSL approaches rely on a mapping between latent visual and semantic spaces without considering if a particular sample belongs to the set of seen or unseen classes. In this paper, we propose a novel GZSL method that learns a joint latent representation that combines both visual and semantic information. This mitigates the need for learning a mapping between the two spaces. Our method also introduces a domain classification that estimates whether a sample belongs to a seen or an unseen class. Our classifier then combines a class discriminator with this domain classifier with the goal of reducing the natural bias that GZSL approaches have toward the seen classes. Experiments show that our method achieves state-of-the-art results in terms of harmonic mean, the area under the seen and unseen curve and unseen classification accuracy on public GZSL benchmark data sets. Our code will be available upon acceptance of this paper.
Generalised Zero-Shot Learning with a Classifier Ensemble over Multi-Modal Embedding Spaces
Aug 06, 2019



Generalised zero-shot learning (GZSL) methods aim to classify previously seen and unseen visual classes by leveraging the semantic information of those classes. In the context of GZSL, semantic information is non-visual data such as a text description of both seen and unseen classes. Previous GZSL methods have utilised transformations between visual and semantic embedding spaces, as well as the learning of joint spaces that include both visual and semantic information. In either case, classification is then performed on a single learned space. We argue that each embedding space contains complementary information for the GZSL problem. By using just a visual, semantic or joint space some of this information will invariably be lost. In this paper, we demonstrate the advantages of our new GZSL method that combines the classification of visual, semantic and joint spaces. Most importantly, this ensembling allows for more information from the source domains to be seen during classification. An additional contribution of our work is the application of a calibration procedure for each classifier in the ensemble. This calibration mitigates the problem of model selection when combining the classifiers. Lastly, our proposed method achieves state-of-the-art results on the CUB, AWA1 and AWA2 benchmark data sets and provides competitive performance on the SUN data set.
Multi-modal Ensemble Classification for Generalized Zero Shot Learning
Jan 15, 2019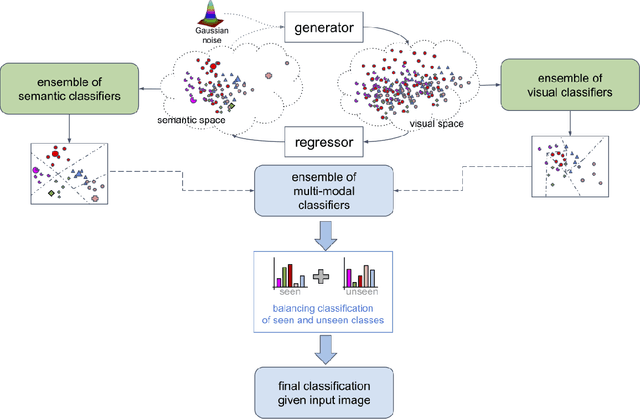



Generalized zero shot learning (GZSL) is defined by a training process containing a set of visual samples from seen classes and a set of semantic samples from seen and unseen classes, while the testing process consists of the classification of visual samples from seen and unseen classes. Current approaches are based on testing processes that focus on only one of the modalities (visual or semantic), even when the training uses both modalities (mostly for regularizing the training process). This under-utilization of modalities, particularly during testing, can hinder the classification accuracy of the method. In addition, we note a scarce attention to the development of learning methods that explicitly optimize a balanced performance of seen and unseen classes. Such issue is one of the reasons behind the vastly superior classification accuracy of seen classes in GZSL methods. In this paper, we mitigate these issues by proposing a new GZSL method based on multi-modal training and testing processes, where the optimization explicitly promotes a balanced classification accuracy between seen and unseen classes. Furthermore, we explore Bayesian inference for the visual and semantic classifiers, which is another novelty of our work in the GZSL framework. Experiments show that our method holds the state of the art (SOTA) results in terms of harmonic mean (H-mean) classification between seen and unseen classes and area under the seen and unseen curve (AUSUC) on several public GZSL benchmarks.
Multi-modal Cycle-consistent Generalized Zero-Shot Learning
Aug 02, 2018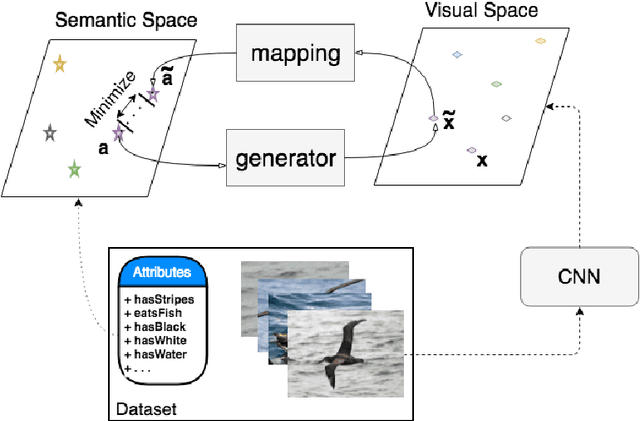
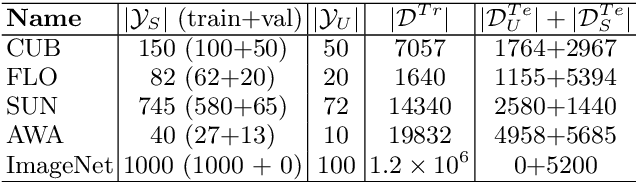
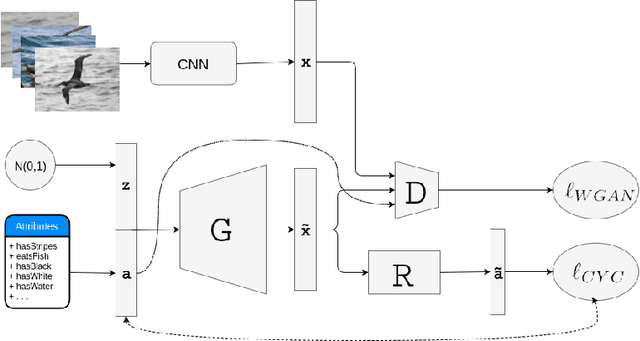

In generalized zero shot learning (GZSL), the set of classes are split into seen and unseen classes, where training relies on the semantic features of the seen and unseen classes and the visual representations of only the seen classes, while testing uses the visual representations of the seen and unseen classes. Current methods address GZSL by learning a transformation from the visual to the semantic space, exploring the assumption that the distribution of classes in the semantic and visual spaces is relatively similar. Such methods tend to transform unseen testing visual representations into one of the seen classes' semantic features instead of the semantic features of the correct unseen class, resulting in low accuracy GZSL classification. Recently, generative adversarial networks (GAN) have been explored to synthesize visual representations of the unseen classes from their semantic features - the synthesized representations of the seen and unseen classes are then used to train the GZSL classifier. This approach has been shown to boost GZSL classification accuracy, however, there is no guarantee that synthetic visual representations can generate back their semantic feature in a multi-modal cycle-consistent manner. This constraint can result in synthetic visual representations that do not represent well their semantic features. In this paper, we propose the use of such constraint based on a new regularization for the GAN training that forces the generated visual features to reconstruct their original semantic features. Once our model is trained with this multi-modal cycle-consistent semantic compatibility, we can then synthesize more representative visual representations for the seen and, more importantly, for the unseen classes. Our proposed approach shows the best GZSL classification results in the field in several publicly available datasets.