 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Ensemble Classification for Generalized Zero Shot Learning
Paper and Code
Jan 15, 2019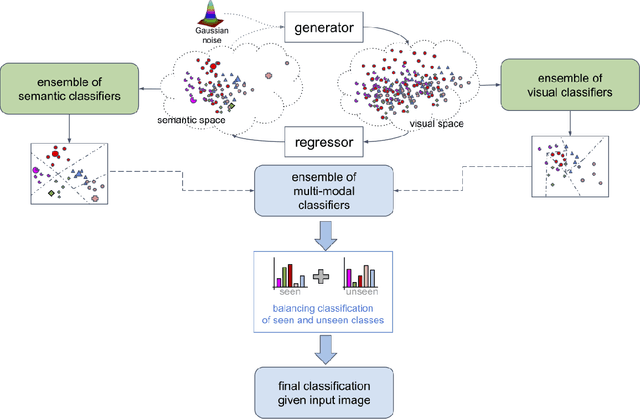



Generalized zero shot learning (GZSL) is defined by a training process containing a set of visual samples from seen classes and a set of semantic samples from seen and unseen classes, while the testing process consists of the classification of visual samples from seen and unseen classes. Current approaches are based on testing processes that focus on only one of the modalities (visual or semantic), even when the training uses both modalities (mostly for regularizing the training process). This under-utilization of modalities, particularly during testing, can hinder the classification accuracy of the method. In addition, we note a scarce attention to the development of learning methods that explicitly optimize a balanced performance of seen and unseen classes. Such issue is one of the reasons behind the vastly superior classification accuracy of seen classes in GZSL methods. In this paper, we mitigate these issues by proposing a new GZSL method based on multi-modal training and testing processes, where the optimization explicitly promotes a balanced classification accuracy between seen and unseen classes. Furthermore, we explore Bayesian inference for the visual and semantic classifiers, which is another novelty of our work in the GZSL framework. Experiments show that our method holds the state of the art (SOTA) results in terms of harmonic mean (H-mean) classification between seen and unseen classes and area under the seen and unseen curve (AUSUC) on several public GZSL benchmarks.