 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum-enhanced Computer Vision: Going Beyond Classical Algorithms
Oct 08, 2025Quantum-enhanced Computer Vision (QeCV) is a new research field at the intersection of computer vision, optimisation theory, machine learning and quantum computing. It has high potential to transform how visual signals are processed and interpreted with the help of quantum computing that leverages quantum-mechanical effects in computations inaccessible to classical (i.e. non-quantum) computers. In scenarios where existing non-quantum methods cannot find a solution in a reasonable time or compute only approximate solutions, quantum computers can provide, among others, advantages in terms of better time scalability for multiple problem classes. Parametrised quantum circuits can also become, in the long term, a considerable alternative to classical neural networks in computer vision. However, specialised and fundamentally new algorithms must be developed to enable compatibility with quantum hardware and unveil the potential of quantum computational paradigms in computer vision. This survey contributes to the existing literature on QeCV with a holistic review of this research field. It is designed as a quantum computing reference for the computer vision community, targeting computer vision students, scientists and readers with related backgrounds who want to familiarise themselves with QeCV. We provide a comprehensive introduction to QeCV, its specifics, and methodologies for formulations compatible with quantum hardware and QeCV methods, leveraging two main quantum computational paradigms, i.e. gate-based quantum computing and quantum annealing. We elaborate on the operational principles of quantum computers and the available tools to access, program and simulate them in the context of QeCV. Finally, we review existing quantum computing tools and learning materials and discuss aspects related to publishing and reviewing QeCV papers, open challenges and potential social implications.
Robust Fitting on a Gate Quantum Computer
Sep 03, 2024


Gate quantum computers generate significant interest due to their potential to solve certain difficult problems such as prime factorization in polynomial time. Computer vision researchers have long been attracted to the power of quantum computers. Robust fitting, which is fundamentally important to many computer vision pipelines, has recently been shown to be amenable to gate quantum computing. The previous proposed solution was to compute Boolean influence as a measure of outlyingness using the Bernstein-Vazirani quantum circuit. However, the method assumed a quantum implementation of an $\ell_\infty$ feasibility test, which has not been demonstrated. In this paper, we take a big stride towards quantum robust fitting: we propose a quantum circuit to solve the $\ell_\infty$ feasibility test in the 1D case, which allows to demonstrate for the first time quantum robust fitting on a real gate quantum computer, the IonQ Aria. We also show how 1D Boolean influences can be accumulated to compute Boolean influences for higher-dimensional non-linear models, which we experimentally validate on real benchmark datasets.
Training Multilayer Perceptrons by Sampling with Quantum Annealers
Mar 22, 2023



A successful application of quantum annealing to machine learning is training restricted Boltzmann machines (RBM). However, many neural networks for vision applications are feedforward structures, such as multilayer perceptrons (MLP). Backpropagation is currently the most effective technique to train MLPs for supervised learning. This paper aims to be forward-looking by exploring the training of MLPs using quantum annealers. We exploit an equivalence between MLPs and energy-based models (EBM), which are a variation of RBMs with a maximum conditional likelihood objective. This leads to a strategy to train MLPs with quantum annealers as a sampling engine. We prove our setup for MLPs with sigmoid activation functions and one hidden layer, and demonstrated training of binary image classifiers on small subsets of the MNIST and Fashion-MNIST datasets using the D-Wave quantum annealer. Although problem sizes that are feasible on current annealers are limited, we obtained comprehensive results on feasible instances that validate our ideas. Our work establishes the potential of quantum computing for training MLPs.
A Hybrid Quantum-Classical Algorithm for Robust Fitting
Jan 31, 2022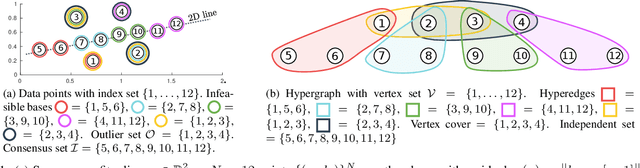
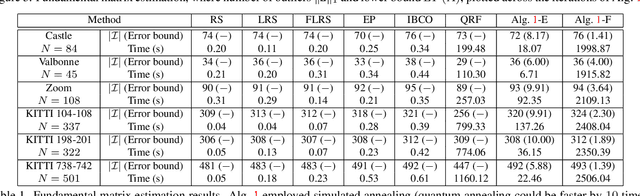
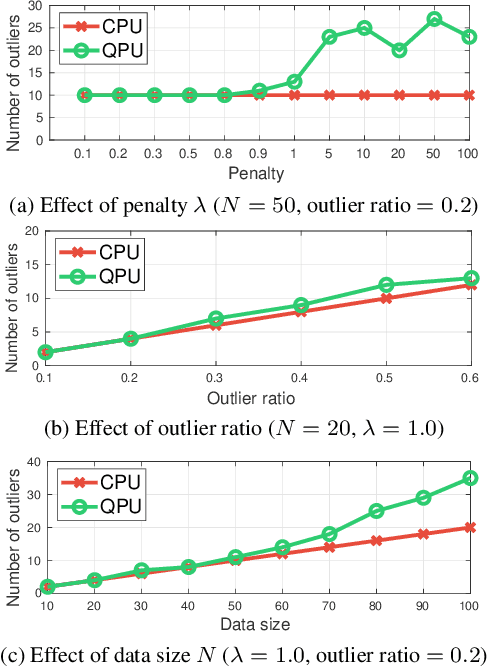
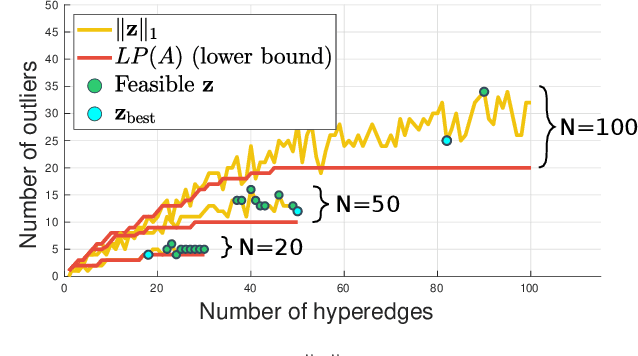
Fitting geometric models onto outlier contaminated data is provably intractable. Many computer vision systems rely on random sampling heuristics to solve robust fitting, which do not provide optimality guarantees and error bounds. It is therefore critical to develop novel approaches that can bridge the gap between exact solutions that are costly, and fast heuristics that offer no quality assurances. In this paper, we propose a hybrid quantum-classical algorithm for robust fitting. Our core contribution is a novel robust fitting formulation that solves a sequence of integer programs and terminates with a global solution or an error bound. The combinatorial subproblems are amenable to a quantum annealer, which helps to tighten the bound efficiently. While our usage of quantum computing does not surmount the fundamental intractability of robust fitting, by providing error bounds our algorithm is a practical improvement over randomised heuristics. Moreover, our work represents a concrete application of quantum computing in computer vision. We present results obtained using an actual quantum computer (D-Wave Advantage) and via simulation. Source code: https://github.com/dadung/HQC-robust-fitting
Mutual information neural estimation for unsupervised multi-modal registration of brain images
Jan 25, 2022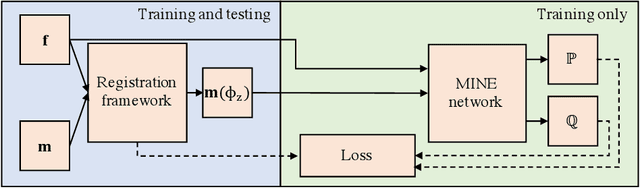
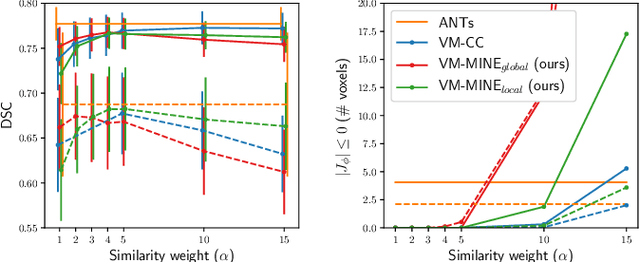
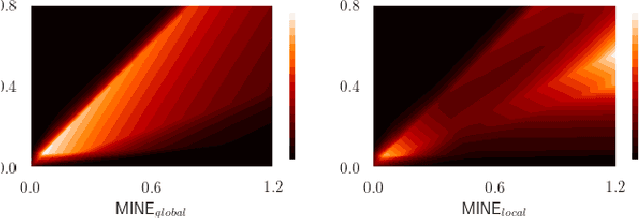

Many applications in image-guided surgery and therapy require fast and reliable non-linear, multi-modal image registration. Recently proposed unsupervised deep learning-based registration methods have demonstrated superior performance compared to iterative methods in just a fraction of the time. Most of the learning-based methods have focused on mono-modal image registration. The extension to multi-modal registration depends on the use of an appropriate similarity function, such as the mutual information (MI). We propose guiding the training of a deep learning-based registration method with MI estimation between an image-pair in an end-to-end trainable network. Our results show that a small, 2-layer network produces competitive results in both mono- and multimodal registration, with sub-second run-times. Comparisons to both iterative and deep learning-based methods show that our MI-based method produces topologically and qualitatively superior results with an extremely low rate of non-diffeomorphic transformations. Real-time clinical application will benefit from a better visual matching of anatomical structures and less registration failures/outliers.
Adversarial Attacks against a Satellite-borne Multispectral Cloud Detector
Dec 03, 2021
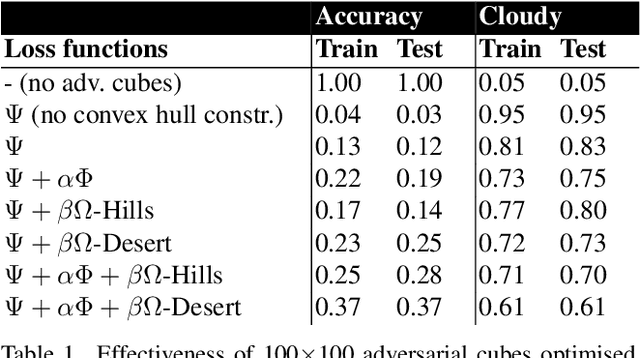

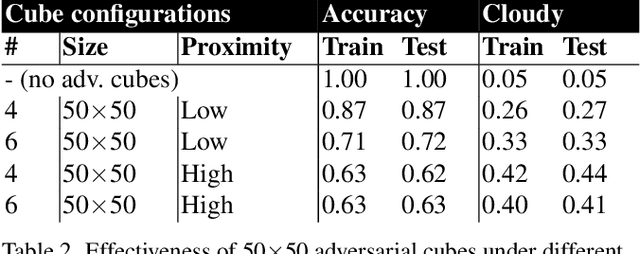
Data collected by Earth-observing (EO) satellites are often afflicted by cloud cover. Detecting the presence of clouds -- which is increasingly done using deep learning -- is crucial preprocessing in EO applications. In fact, advanced EO satellites perform deep learning-based cloud detection on board the satellites and downlink only clear-sky data to save precious bandwidth. In this paper, we highlight the vulnerability of deep learning-based cloud detection towards adversarial attacks. By optimising an adversarial pattern and superimposing it into a cloudless scene, we bias the neural network into detecting clouds in the scene. Since the input spectra of cloud detectors include the non-visible bands, we generated our attacks in the multispectral domain. This opens up the potential of multi-objective attacks, specifically, adversarial biasing in the cloud-sensitive bands and visual camouflage in the visible bands. We also investigated mitigation strategies against the adversarial attacks. We hope our work further builds awareness of the potential of adversarial attacks in the EO community.
Physical Adversarial Attacks on an Aerial Imagery Object Detector
Aug 26, 2021
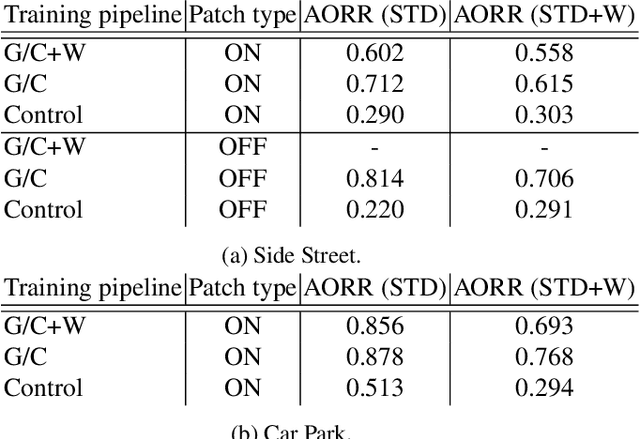

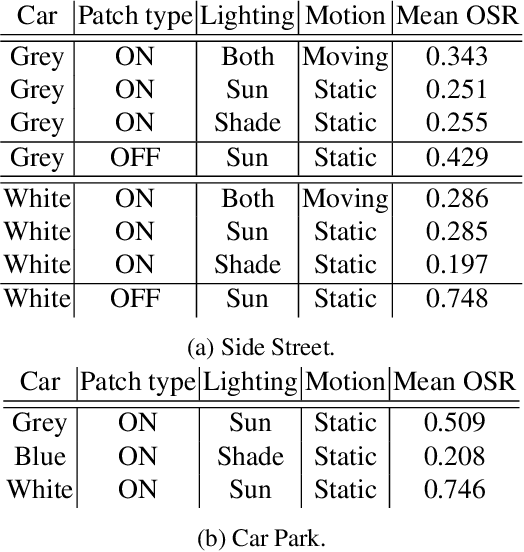
Deep neural networks (DNNs) have become essential for processing the vast amounts of aerial imagery collected using earth-observing satellite platforms. However, DNNs are vulnerable towards adversarial examples, and it is expected that this weakness also plagues DNNs for aerial imagery. In this work, we demonstrate one of the first efforts on physical adversarial attacks on aerial imagery, whereby adversarial patches were optimised, fabricated and installed on or near target objects (cars) to significantly reduce the efficacy of an object detector applied on overhead images. Physical adversarial attacks on aerial images, particularly those captured from satellite platforms, are challenged by atmospheric factors (lighting, weather, seasons) and the distance between the observer and target. To investigate the effects of these challenges, we devised novel experiments and metrics to evaluate the efficacy of physical adversarial attacks against object detectors in aerial scenes. Our results indicate the palpable threat posed by physical adversarial attacks towards DNNs for processing satellite imagery.
Quantum Annealing Formulation for Binary Neural Networks
Jul 05, 2021
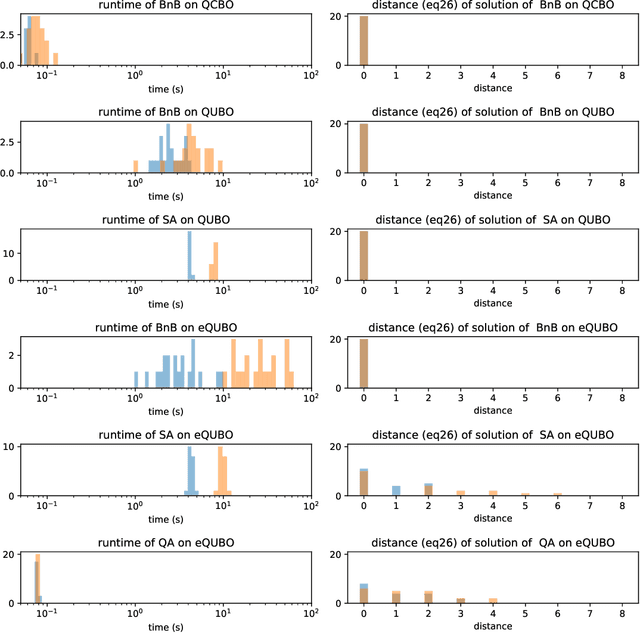
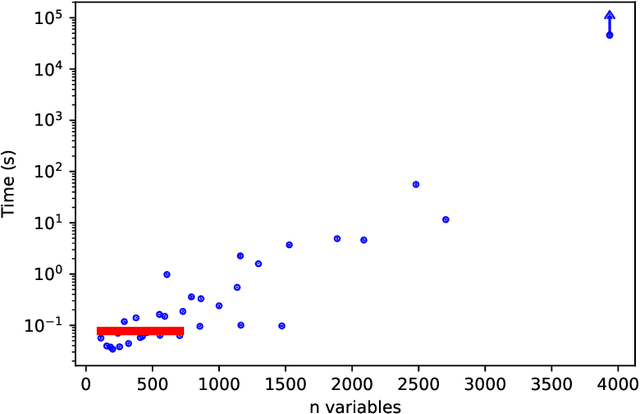

Quantum annealing is a promising paradigm for building practical quantum computers. Compared to other approaches, quantum annealing technology has been scaled up to a larger number of qubits. On the other hand, deep learning has been profoundly successful in pushing the boundaries of AI. It is thus natural to investigate potentially game changing technologies such as quantum annealers to augment the capabilities of deep learning. In this work, we explore binary neural networks, which are lightweight yet powerful models typically intended for resource constrained devices. Departing from current training regimes for binary networks that smooth/approximate the activation functions to make the network differentiable, we devise a quadratic unconstrained binary optimization formulation for the training problem. While the problem is intractable, i.e., the cost to estimate the binary weights scales exponentially with network size, we show how the problem can be optimized directly on a quantum annealer, thereby opening up to the potential gains of quantum computing. We experimentally validated our formulation via simulation and testing on an actual quantum annealer (D-Wave Advantage), the latter to the extent allowable by the capacity of current technology.
Generalised Zero-Shot Learning with Domain Classification in a Joint Semantic and Visual Space
Aug 14, 2019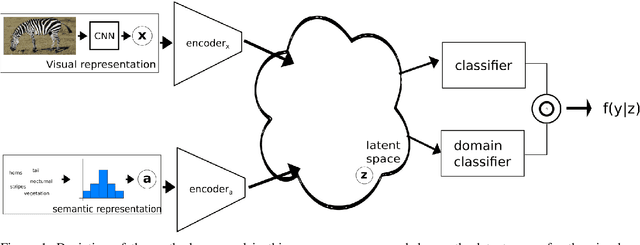
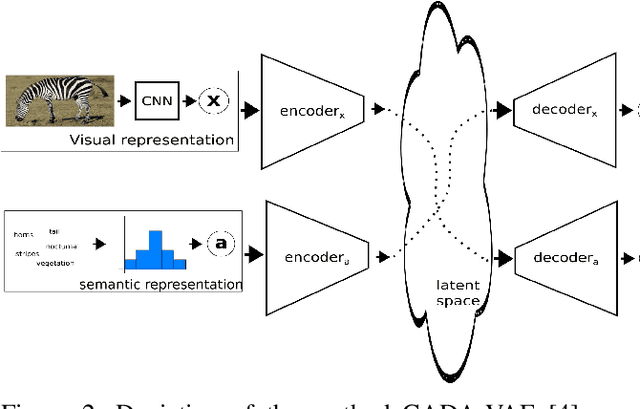
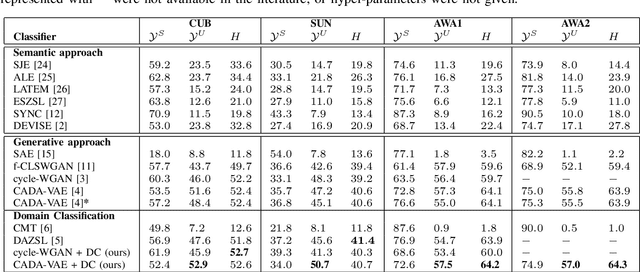
Generalised zero-shot learning (GZSL) is a classification problem where the learning stage relies on a set of seen visual classes and the inference stage aims to identify both the seen visual classes and a new set of unseen visual classes. Critically, both the learning and inference stages can leverage a semantic representation that is available for the seen and unseen classes. Most state-of-the-art GZSL approaches rely on a mapping between latent visual and semantic spaces without considering if a particular sample belongs to the set of seen or unseen classes. In this paper, we propose a novel GZSL method that learns a joint latent representation that combines both visual and semantic information. This mitigates the need for learning a mapping between the two spaces. Our method also introduces a domain classification that estimates whether a sample belongs to a seen or an unseen class. Our classifier then combines a class discriminator with this domain classifier with the goal of reducing the natural bias that GZSL approaches have toward the seen classes. Experiments show that our method achieves state-of-the-art results in terms of harmonic mean, the area under the seen and unseen curve and unseen classification accuracy on public GZSL benchmark data sets. Our code will be available upon acceptance of this paper.
Generalised Zero-Shot Learning with a Classifier Ensemble over Multi-Modal Embedding Spaces
Aug 06, 2019



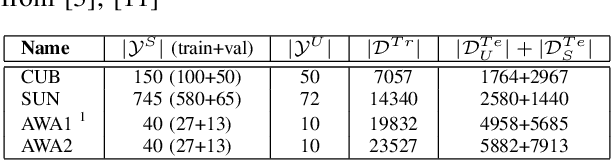
Generalised zero-shot learning (GZSL) methods aim to classify previously seen and unseen visual classes by leveraging the semantic information of those classes. In the context of GZSL, semantic information is non-visual data such as a text description of both seen and unseen classes. Previous GZSL methods have utilised transformations between visual and semantic embedding spaces, as well as the learning of joint spaces that include both visual and semantic information. In either case, classification is then performed on a single learned space. We argue that each embedding space contains complementary information for the GZSL problem. By using just a visual, semantic or joint space some of this information will invariably be lost. In this paper, we demonstrate the advantages of our new GZSL method that combines the classification of visual, semantic and joint spaces. Most importantly, this ensembling allows for more information from the source domains to be seen during classification. An additional contribution of our work is the application of a calibration procedure for each classifier in the ensemble. This calibration mitigates the problem of model selection when combining the classifiers. Lastly, our proposed method achieves state-of-the-art results on the CUB, AWA1 and AWA2 benchmark data sets and provides competitive performance on the SUN data set.