 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Nearest Neighbour Search on Dynamic Datasets: An Investigation
Apr 30, 2024Approximate k-Nearest Neighbour (ANN) methods are often used for mining information and aiding machine learning on large scale high-dimensional datasets. ANN methods typically differ in the index structure used for accelerating searches, resulting in various recall/runtime trade-off points. For applications with static datasets, runtime constraints and dataset properties can be used to empirically select an ANN method with suitable operating characteristics. However, for applications with dynamic datasets, which are subject to frequent online changes (like addition of new samples), there is currently no consensus as to which ANN methods are most suitable. Traditional evaluation approaches do not consider the computational costs of updating the index structure, as well as the frequency and size of index updates. To address this, we empirically evaluate 5 popular ANN methods on two main applications (online data collection and online feature learning) while taking into account these considerations. Two dynamic datasets are used, derived from the SIFT1M dataset with 1 million samples and the DEEP1B dataset with 1 billion samples. The results indicate that the often used k-d trees method is not suitable on dynamic datasets as it is slower than a straightforward baseline exhaustive search method. For online data collection, the Hierarchical Navigable Small World Graphs method achieves a consistent speedup over baseline across a wide range of recall rates. For online feature learning, the Scalable Nearest Neighbours method is faster than baseline for recall rates below 75%.
Locus: LiDAR-based Place Recognition using Spatiotemporal Higher-Order Pooling
Nov 30, 2020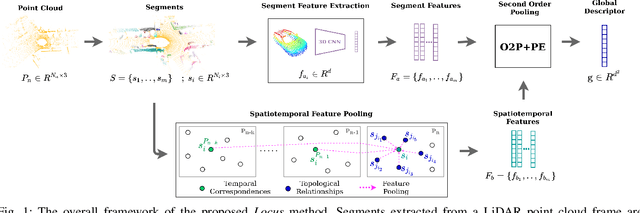
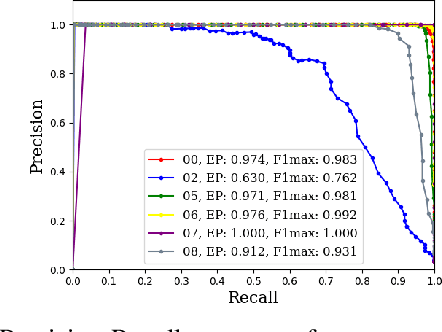
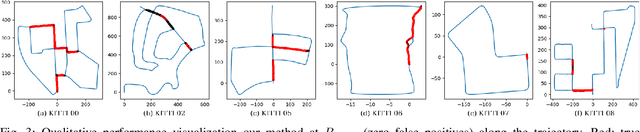
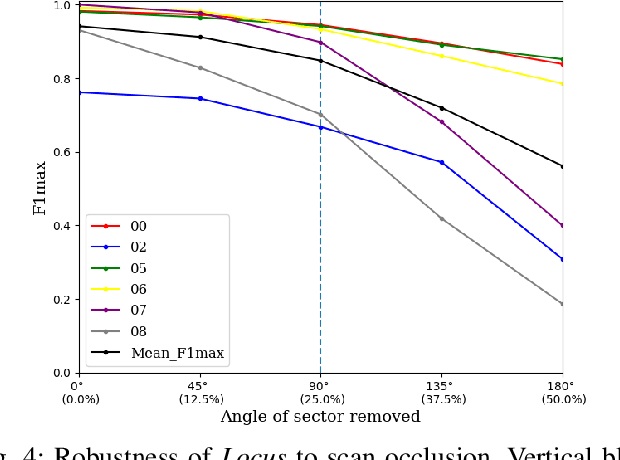
Place Recognition (PR) enables the estimation of a globally consistent map and trajectory by providing non-local constraints in Simultaneous Localisation and Mapping (SLAM). This paper presents Locus, a novel place recognition method using 3D LiDAR point clouds in large-scale environments. We propose a novel method for extracting and encoding topological and temporal information related to components in a scene and demonstrate how the inclusion of this auxiliary information in place description leads to more robust and discriminative scene representations. Second-order pooling along with a non-linear transform is used to aggregate these multi-level features to generate a fixed-length global descriptor, which is invariant to the permutation of input features. The proposed method outperforms state-of-the-art methods on the KITTI dataset. Furthermore, Locus is demonstrated to be robust across several challenging situations such as occlusions and viewpoint changes.
Delta Descriptors: Change-Based Place Representation for Robust Visual Localization
Jun 10, 2020
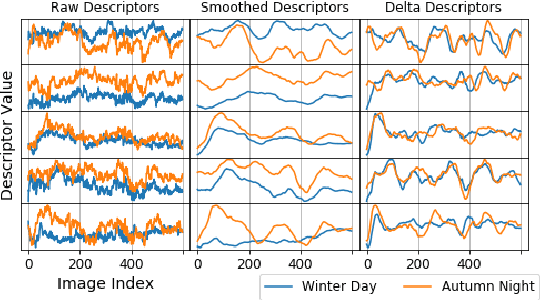

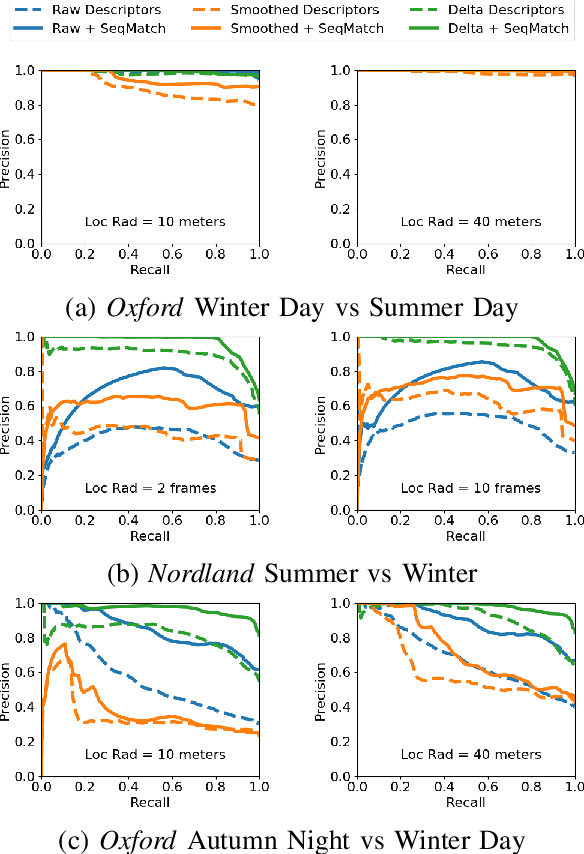
Visual place recognition is challenging because there are so many factors that can cause the appearance of a place to change, from day-night cycles to seasonal change to atmospheric conditions. In recent years a large range of approaches have been developed to address this challenge including deep-learnt image descriptors, domain translation, and sequential filtering, all with shortcomings including generality and velocity-sensitivity. In this paper we propose a novel descriptor derived from tracking changes in any learned global descriptor over time, dubbed Delta Descriptors. Delta Descriptors mitigate the offsets induced in the original descriptor matching space in an unsupervised manner by considering temporal differences across places observed along a route. Like all other approaches, Delta Descriptors have a shortcoming - volatility on a frame to frame basis - which can be overcome by combining them with sequential filtering methods. Using two benchmark datasets, we first demonstrate the high performance of Delta Descriptors in isolation, before showing new state-of-the-art performance when combined with sequence-based matching. We also present results demonstrating the approach working with a second different underlying descriptor type, and two other beneficial properties of Delta Descriptors in comparison to existing techniques: their increased inherent robustness to variations in camera motion and a reduced rate of performance degradation as dimensional reduction is applied. Source code will be released upon publication.
Generalised Zero-Shot Learning with Domain Classification in a Joint Semantic and Visual Space
Aug 14, 2019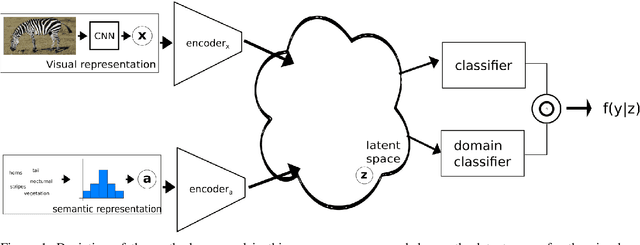
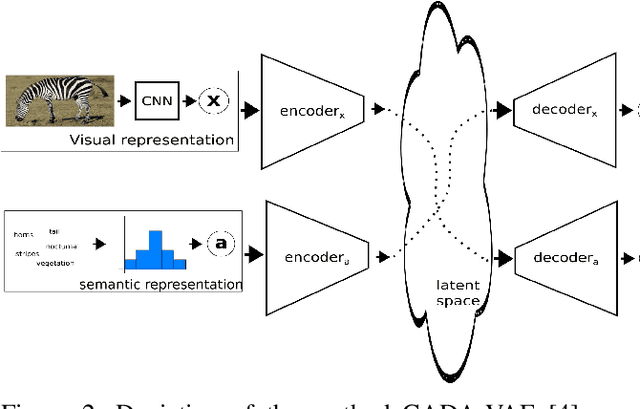
Generalised zero-shot learning (GZSL) is a classification problem where the learning stage relies on a set of seen visual classes and the inference stage aims to identify both the seen visual classes and a new set of unseen visual classes. Critically, both the learning and inference stages can leverage a semantic representation that is available for the seen and unseen classes. Most state-of-the-art GZSL approaches rely on a mapping between latent visual and semantic spaces without considering if a particular sample belongs to the set of seen or unseen classes. In this paper, we propose a novel GZSL method that learns a joint latent representation that combines both visual and semantic information. This mitigates the need for learning a mapping between the two spaces. Our method also introduces a domain classification that estimates whether a sample belongs to a seen or an unseen class. Our classifier then combines a class discriminator with this domain classifier with the goal of reducing the natural bias that GZSL approaches have toward the seen classes. Experiments show that our method achieves state-of-the-art results in terms of harmonic mean, the area under the seen and unseen curve and unseen classification accuracy on public GZSL benchmark data sets. Our code will be available upon acceptance of this paper.
Generalised Zero-Shot Learning with a Classifier Ensemble over Multi-Modal Embedding Spaces
Aug 06, 2019



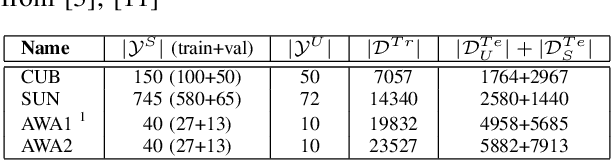
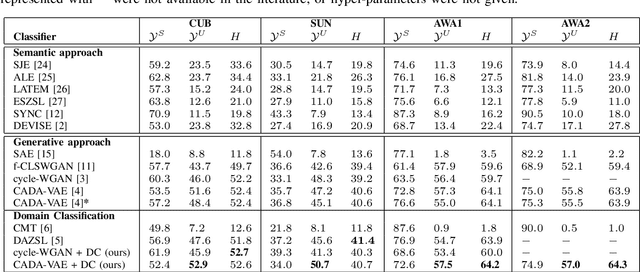
Generalised zero-shot learning (GZSL) methods aim to classify previously seen and unseen visual classes by leveraging the semantic information of those classes. In the context of GZSL, semantic information is non-visual data such as a text description of both seen and unseen classes. Previous GZSL methods have utilised transformations between visual and semantic embedding spaces, as well as the learning of joint spaces that include both visual and semantic information. In either case, classification is then performed on a single learned space. We argue that each embedding space contains complementary information for the GZSL problem. By using just a visual, semantic or joint space some of this information will invariably be lost. In this paper, we demonstrate the advantages of our new GZSL method that combines the classification of visual, semantic and joint spaces. Most importantly, this ensembling allows for more information from the source domains to be seen during classification. An additional contribution of our work is the application of a calibration procedure for each classifier in the ensemble. This calibration mitigates the problem of model selection when combining the classifiers. Lastly, our proposed method achieves state-of-the-art results on the CUB, AWA1 and AWA2 benchmark data sets and provides competitive performance on the SUN data set.
Deep Metric Learning and Image Classification with Nearest Neighbour Gaussian Kernels
Jul 02, 2018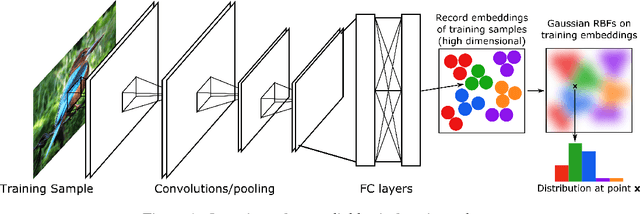
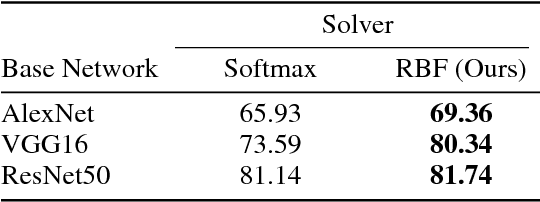
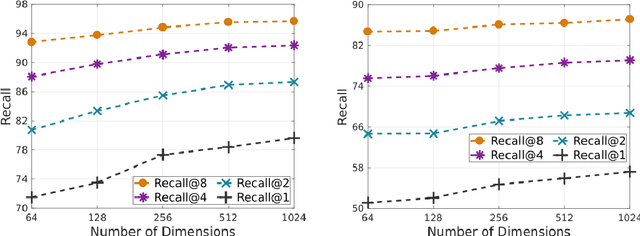
We present a Gaussian kernel loss function and training algorithm for convolutional neural networks that can be directly applied to both distance metric learning and image classification problems. Our method treats all training features from a deep neural network as Gaussian kernel centres and computes loss by summing the influence of a feature's nearby centres in the feature embedding space. Our approach is made scalable by treating it as an approximate nearest neighbour search problem. We show how to make end-to-end learning feasible, resulting in a well formed embedding space, in which semantically related instances are likely to be located near one another, regardless of whether or not the network was trained on those classes. Our approach outperforms state-of-the-art deep metric learning approaches on embedding learning challenges, as well as conventional softmax classification on several datasets.
Smart Mining for Deep Metric Learning
Jul 27, 2017
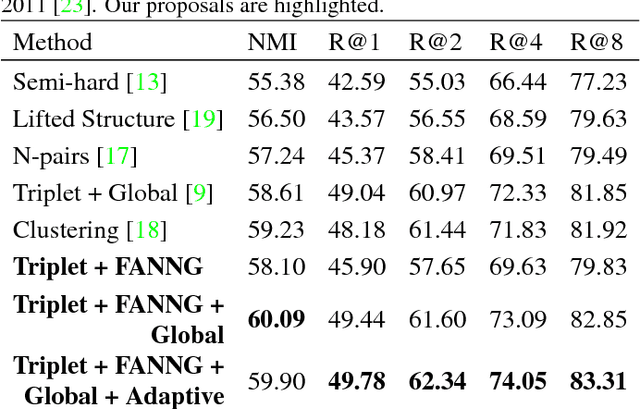
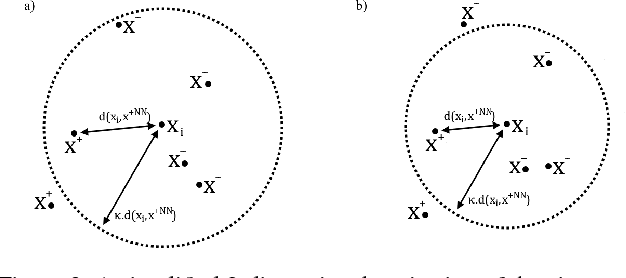
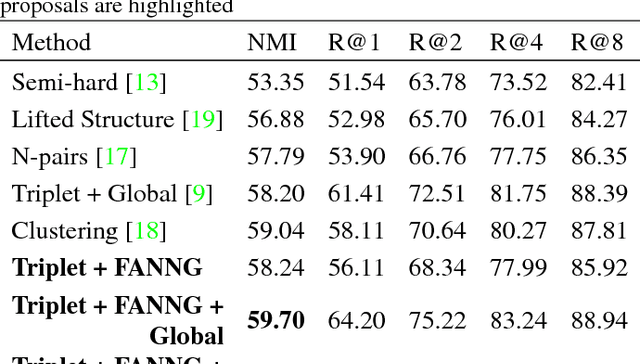
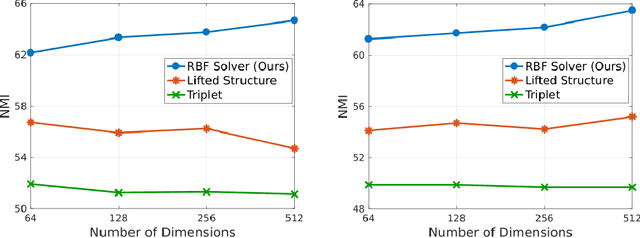
To solve deep metric learning problems and producing feature embeddings, current methodologies will commonly use a triplet model to minimise the relative distance between samples from the same class and maximise the relative distance between samples from different classes. Though successful, the training convergence of this triplet model can be compromised by the fact that the vast majority of the training samples will produce gradients with magnitudes that are close to zero. This issue has motivated the development of methods that explore the global structure of the embedding and other methods that explore hard negative/positive mining. The effectiveness of such mining methods is often associated with intractable computational requirements. In this paper, we propose a novel deep metric learning method that combines the triplet model and the global structure of the embedding space. We rely on a smart mining procedure that produces effective training samples for a low computational cost. In addition, we propose an adaptive controller that automatically adjusts the smart mining hyper-parameters and speeds up the convergence of the training process. We show empirically that our proposed method allows for fast and more accurate training of triplet ConvNets than other competing mining methods. Additionally, we show that our method achieves new state-of-the-art embedding results for CUB-200-2011 and Cars196 datasets.