 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Semantic Chasm: Synergistic Conceptual Anchoring for Generalized Few-Shot and Zero-Shot OOD Perception
Jan 30, 2026This manuscript presents a pioneering Synergistic Neural Agents Network (SynerNet) framework designed to mitigate the phenomenon of cross-modal alignment degeneration in Vision-Language Models (VLMs) when encountering Out-of-Distribution (OOD) concepts. Specifically, four specialized computational units - visual perception, linguistic context, nominal embedding, and global coordination - collaboratively rectify modality disparities via a structured message-propagation protocol. The principal contributions encompass a multi-agent latent space nomenclature acquisition framework, a semantic context-interchange algorithm for enhanced few-shot adaptation, and an adaptive dynamic equilibrium mechanism. Empirical evaluations conducted on the VISTA-Beyond benchmark demonstrate that SynerNet yields substantial performance augmentations in both few-shot and zero-shot scenarios, exhibiting precision improvements ranging from 1.2% to 5.4% across a diverse array of domains.
Multispectral Demosaicing via Dual Cameras
Mar 27, 2025



Multispectral (MS) images capture detailed scene information across a wide range of spectral bands, making them invaluable for applications requiring rich spectral data. Integrating MS imaging into multi camera devices, such as smartphones, has the potential to enhance both spectral applications and RGB image quality. A critical step in processing MS data is demosaicing, which reconstructs color information from the mosaic MS images captured by the camera. This paper proposes a method for MS image demosaicing specifically designed for dual-camera setups where both RGB and MS cameras capture the same scene. Our approach leverages co-captured RGB images, which typically have higher spatial fidelity, to guide the demosaicing of lower-fidelity MS images. We introduce the Dual-camera RGB-MS Dataset - a large collection of paired RGB and MS mosaiced images with ground-truth demosaiced outputs - that enables training and evaluation of our method. Experimental results demonstrate that our method achieves state-of-the-art accuracy compared to existing techniques.
ReverBERT: A State Space Model for Efficient Text-Driven Speech Style Transfer
Mar 26, 2025Text-driven speech style transfer aims to mold the intonation, pace, and timbre of a spoken utterance to match stylistic cues from text descriptions. While existing methods leverage large-scale neural architectures or pre-trained language models, the computational costs often remain high. In this paper, we present \emph{ReverBERT}, an efficient framework for text-driven speech style transfer that draws inspiration from a state space model (SSM) paradigm, loosely motivated by the image-based method of Wang and Liu~\cite{wang2024stylemamba}. Unlike image domain techniques, our method operates in the speech space and integrates a discrete Fourier transform of latent speech features to enable smooth and continuous style modulation. We also propose a novel \emph{Transformer-based SSM} layer for bridging textual style descriptors with acoustic attributes, dramatically reducing inference time while preserving high-quality speech characteristics. Extensive experiments on benchmark speech corpora demonstrate that \emph{ReverBERT} significantly outperforms baselines in terms of naturalness, expressiveness, and computational efficiency. We release our model and code publicly to foster further research in text-driven speech style transfer.
Mixed Graph Signal Analysis of Joint Image Denoising / Interpolation
Sep 18, 2023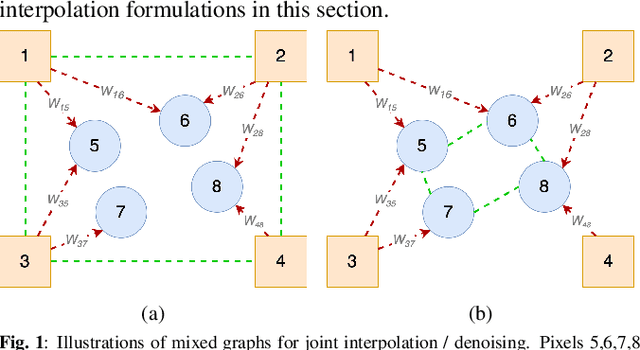

A noise-corrupted image often requires interpolation. Given a linear denoiser and a linear interpolator, when should the operations be independently executed in separate steps, and when should they be combined and jointly optimized? We study joint denoising / interpolation of images from a mixed graph filtering perspective: we model denoising using an undirected graph, and interpolation using a directed graph. We first prove that, under mild conditions, a linear denoiser is a solution graph filter to a maximum a posteriori (MAP) problem regularized using an undirected graph smoothness prior, while a linear interpolator is a solution to a MAP problem regularized using a directed graph smoothness prior. Next, we study two variants of the joint interpolation / denoising problem: a graph-based denoiser followed by an interpolator has an optimal separable solution, while an interpolator followed by a denoiser has an optimal non-separable solution. Experiments show that our joint denoising / interpolation method outperformed separate approaches noticeably.
Adversarial Attacks against a Satellite-borne Multispectral Cloud Detector
Dec 03, 2021
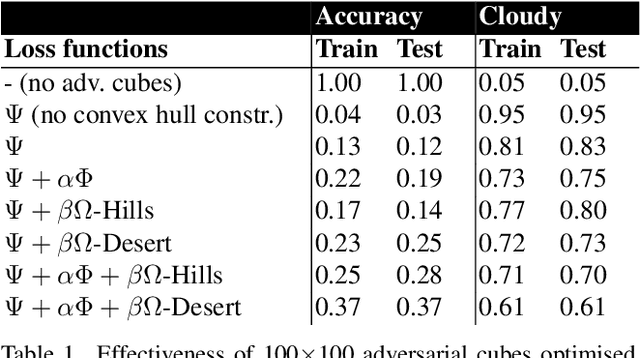

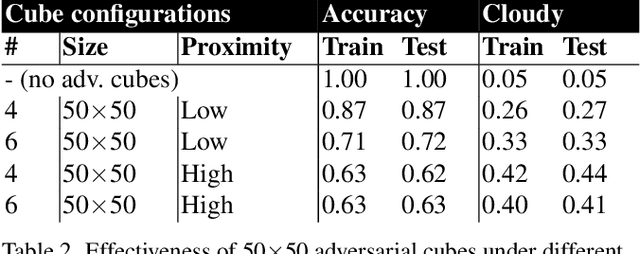
Data collected by Earth-observing (EO) satellites are often afflicted by cloud cover. Detecting the presence of clouds -- which is increasingly done using deep learning -- is crucial preprocessing in EO applications. In fact, advanced EO satellites perform deep learning-based cloud detection on board the satellites and downlink only clear-sky data to save precious bandwidth. In this paper, we highlight the vulnerability of deep learning-based cloud detection towards adversarial attacks. By optimising an adversarial pattern and superimposing it into a cloudless scene, we bias the neural network into detecting clouds in the scene. Since the input spectra of cloud detectors include the non-visible bands, we generated our attacks in the multispectral domain. This opens up the potential of multi-objective attacks, specifically, adversarial biasing in the cloud-sensitive bands and visual camouflage in the visible bands. We also investigated mitigation strategies against the adversarial attacks. We hope our work further builds awareness of the potential of adversarial attacks in the EO community.
The ISTI Rapid Response on Exploring Cloud Computing 2018
Jan 04, 2019
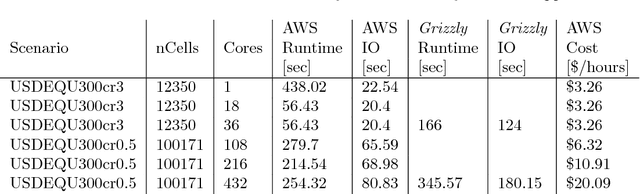

This report describes eighteen projects that explored how commercial cloud computing services can be utilized for scientific computation at national laboratories. These demonstrations ranged from deploying proprietary software in a cloud environment to leveraging established cloud-based analytics workflows for processing scientific datasets. By and large, the projects were successful and collectively they suggest that cloud computing can be a valuable computational resource for scientific computation at national laboratories.