 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation for Satellite-Borne Hyperspectral Cloud Detection
Sep 05, 2023


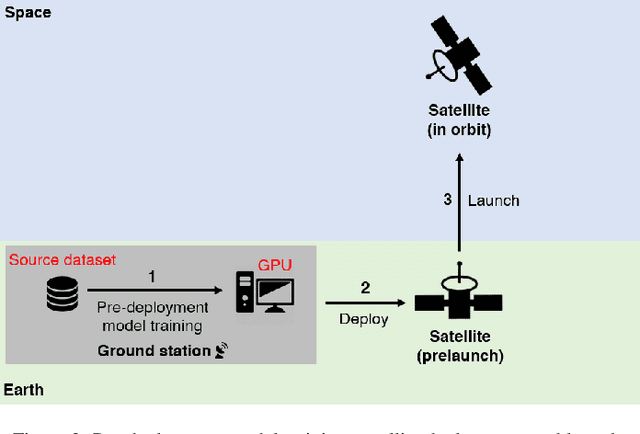
The advent of satellite-borne machine learning hardware accelerators has enabled the on-board processing of payload data using machine learning techniques such as convolutional neural networks (CNN). A notable example is using a CNN to detect the presence of clouds in hyperspectral data captured on Earth observation (EO) missions, whereby only clear sky data is downlinked to conserve bandwidth. However, prior to deployment, new missions that employ new sensors will not have enough representative datasets to train a CNN model, while a model trained solely on data from previous missions will underperform when deployed to process the data on the new missions. This underperformance stems from the domain gap, i.e., differences in the underlying distributions of the data generated by the different sensors in previous and future missions. In this paper, we address the domain gap problem in the context of on-board hyperspectral cloud detection. Our main contributions lie in formulating new domain adaptation tasks that are motivated by a concrete EO mission, developing a novel algorithm for bandwidth-efficient supervised domain adaptation, and demonstrating test-time adaptation algorithms on space deployable neural network accelerators. Our contributions enable minimal data transmission to be invoked (e.g., only 1% of the weights in ResNet50) to achieve domain adaptation, thereby allowing more sophisticated CNN models to be deployed and updated on satellites without being hampered by domain gap and bandwidth limitations.
Adversarial Attacks against a Satellite-borne Multispectral Cloud Detector
Dec 03, 2021
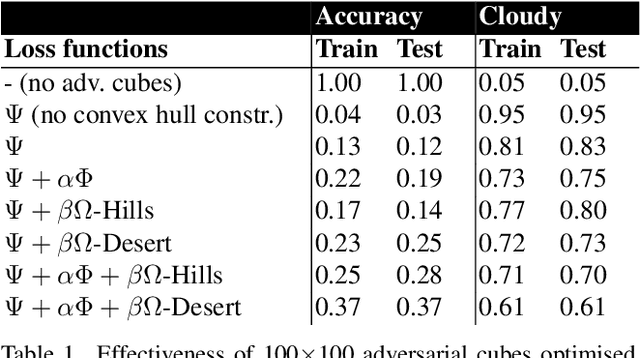

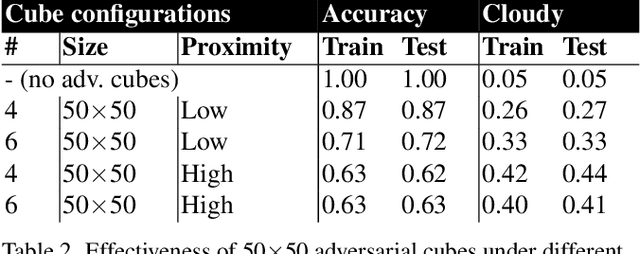
Data collected by Earth-observing (EO) satellites are often afflicted by cloud cover. Detecting the presence of clouds -- which is increasingly done using deep learning -- is crucial preprocessing in EO applications. In fact, advanced EO satellites perform deep learning-based cloud detection on board the satellites and downlink only clear-sky data to save precious bandwidth. In this paper, we highlight the vulnerability of deep learning-based cloud detection towards adversarial attacks. By optimising an adversarial pattern and superimposing it into a cloudless scene, we bias the neural network into detecting clouds in the scene. Since the input spectra of cloud detectors include the non-visible bands, we generated our attacks in the multispectral domain. This opens up the potential of multi-objective attacks, specifically, adversarial biasing in the cloud-sensitive bands and visual camouflage in the visible bands. We also investigated mitigation strategies against the adversarial attacks. We hope our work further builds awareness of the potential of adversarial attacks in the EO community.
A Multi-viewpoint Outdoor Dataset for Human Action Recognition
Oct 07, 2021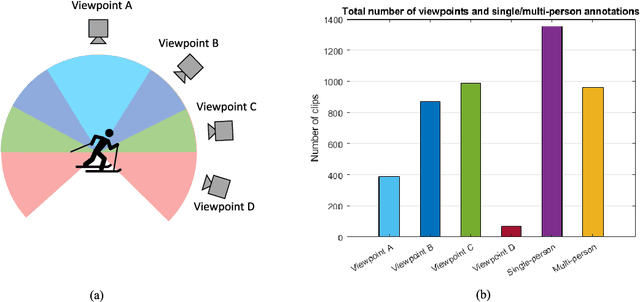

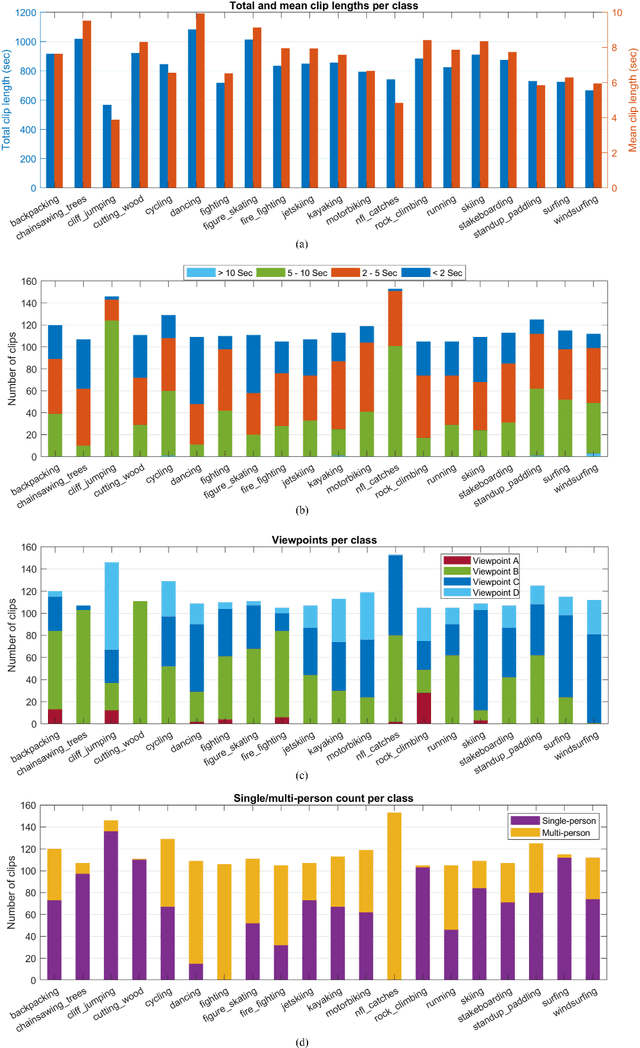
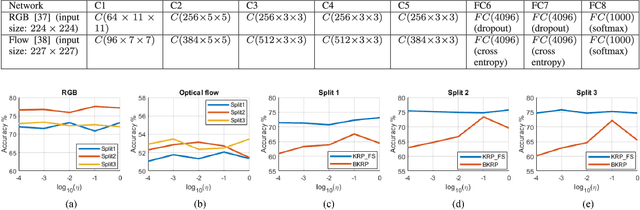
Advancements in deep neural networks have contributed to near perfect results for many computer vision problems such as object recognition, face recognition and pose estimation. However, human action recognition is still far from human-level performance. Owing to the articulated nature of the human body, it is challenging to detect an action from multiple viewpoints, particularly from an aerial viewpoint. This is further compounded by a scarcity of datasets that cover multiple viewpoints of actions. To fill this gap and enable research in wider application areas, we present a multi-viewpoint outdoor action recognition dataset collected from YouTube and our own drone. The dataset consists of 20 dynamic human action classes, 2324 video clips and 503086 frames. All videos are cropped and resized to 720x720 without distorting the original aspect ratio of the human subjects in videos. This dataset should be useful to many research areas including action recognition, surveillance and situational awareness. We evaluated the dataset with a two-stream CNN architecture coupled with a recently proposed temporal pooling scheme called kernelized rank pooling that produces nonlinear feature subspace representations. The overall baseline action recognition accuracy is 74.0%.
* 10 pages, 4 figures
Physical Adversarial Attacks on an Aerial Imagery Object Detector
Aug 26, 2021
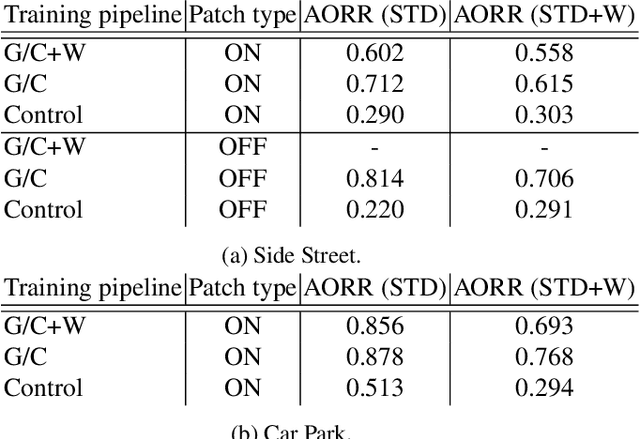

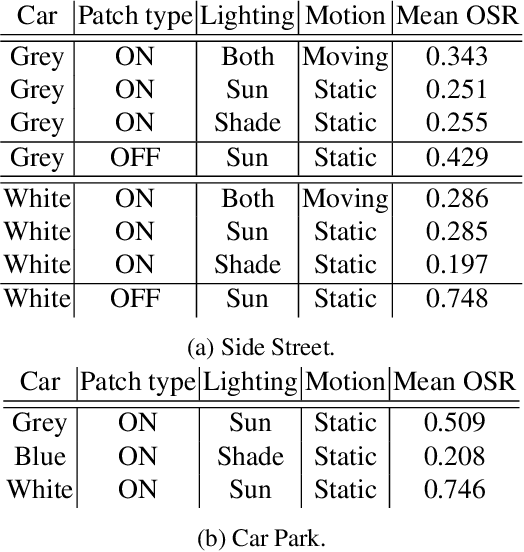
Deep neural networks (DNNs) have become essential for processing the vast amounts of aerial imagery collected using earth-observing satellite platforms. However, DNNs are vulnerable towards adversarial examples, and it is expected that this weakness also plagues DNNs for aerial imagery. In this work, we demonstrate one of the first efforts on physical adversarial attacks on aerial imagery, whereby adversarial patches were optimised, fabricated and installed on or near target objects (cars) to significantly reduce the efficacy of an object detector applied on overhead images. Physical adversarial attacks on aerial images, particularly those captured from satellite platforms, are challenged by atmospheric factors (lighting, weather, seasons) and the distance between the observer and target. To investigate the effects of these challenges, we devised novel experiments and metrics to evaluate the efficacy of physical adversarial attacks against object detectors in aerial scenes. Our results indicate the palpable threat posed by physical adversarial attacks towards DNNs for processing satellite imagery.
UAV-GESTURE: A Dataset for UAV Control and Gesture Recognition
Jan 09, 2019
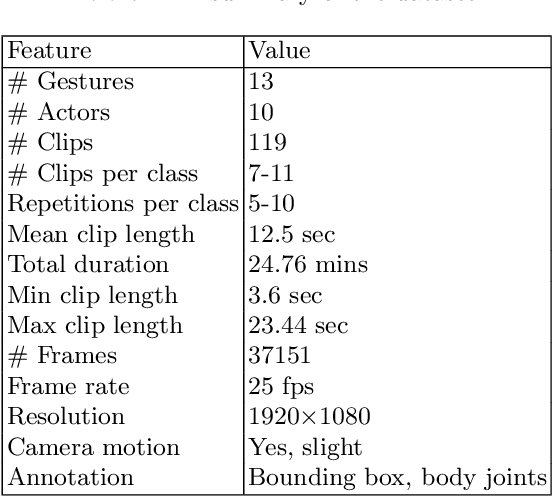


Current UAV-recorded datasets are mostly limited to action recognition and object tracking, whereas the gesture signals datasets were mostly recorded in indoor spaces. Currently, there is no outdoor recorded public video dataset for UAV commanding signals. Gesture signals can be effectively used with UAVs by leveraging the UAVs visual sensors and operational simplicity. To fill this gap and enable research in wider application areas, we present a UAV gesture signals dataset recorded in an outdoor setting. We selected 13 gestures suitable for basic UAV navigation and command from general aircraft handling and helicopter handling signals. We provide 119 high-definition video clips consisting of 37151 frames. The overall baseline gesture recognition performance computed using Pose-based Convolutional Neural Network (P-CNN) is 91.9 %. All the frames are annotated with body joints and gesture classes in order to extend the dataset's applicability to a wider research area including gesture recognition, action recognition, human pose recognition and situation awareness.
Human Pose and Path Estimation from Aerial Video using Dynamic Classifier Selection
Dec 16, 2018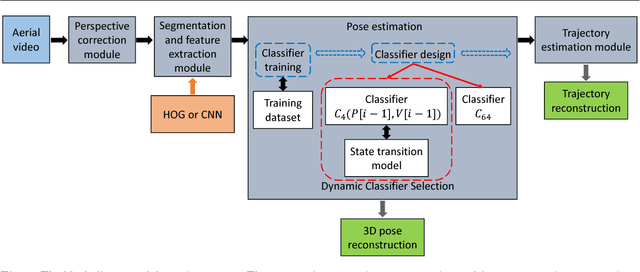
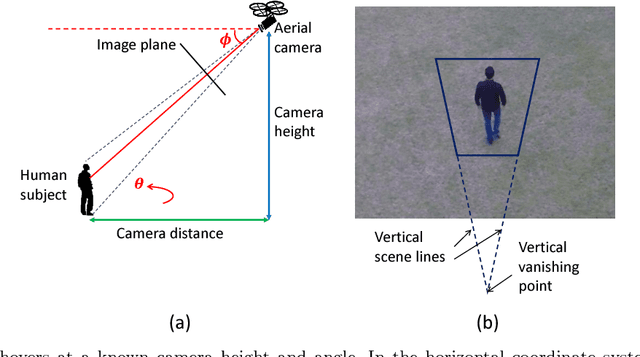
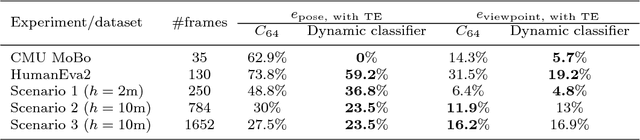

We consider the problem of estimating human pose and trajectory by an aerial robot with a monocular camera in near real time. We present a preliminary solution whose distinguishing feature is a dynamic classifier selection architecture. In our solution, each video frame is corrected for perspective using projective transformation. Then, two alternative feature sets are used: (i) Histogram of Oriented Gradients (HOG) of the silhouette, (ii) Convolutional Neural Network (CNN) features of the RGB image. The features (HOG or CNN) are classified using a dynamic classifier. A class is defined as a pose-viewpoint pair, and a total of 64 classes are defined to represent a forward walking and turning gait sequence. Our solution provides three main advantages: (i) Classification is efficient due to dynamic selection (4-class vs. 64-class classification). (ii) Classification errors are confined to neighbors of the true view-points. (iii) The robust temporal relationship between poses is used to resolve the left-right ambiguities of human silhouettes. Experiments conducted on both fronto-parallel videos and aerial videos confirm our solution can achieve accurate pose and trajectory estimation for both scenarios. We found using HOG features provides higher accuracy than using CNN features. For example, applying the HOG-based variant of our scheme to the 'walking on a figure 8-shaped path' dataset (1652 frames) achieved estimation accuracies of 99.6% for viewpoints and 96.2% for number of poses.
* For associated dataset, see https://asankagp.github.io/aerialgaitdataset/