 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-viewpoint Outdoor Dataset for Human Action Recognition
Oct 07, 2021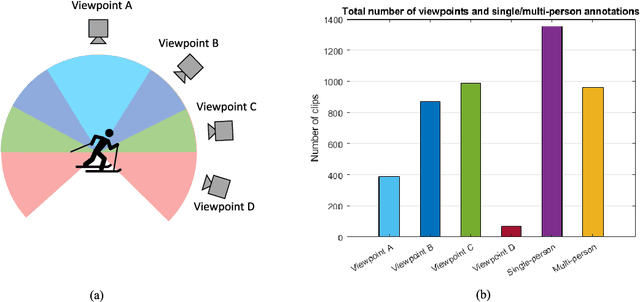

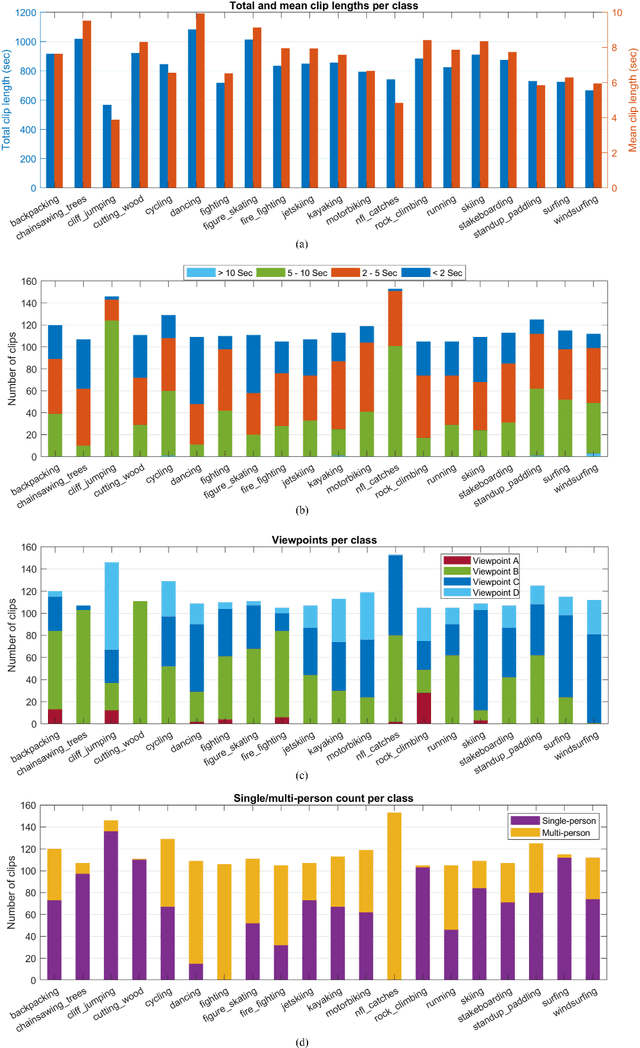
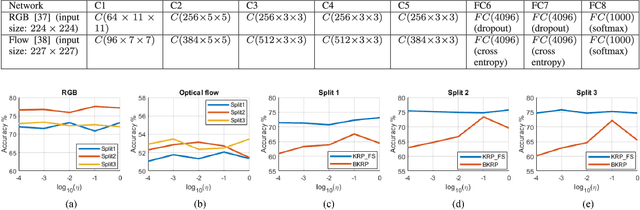
Advancements in deep neural networks have contributed to near perfect results for many computer vision problems such as object recognition, face recognition and pose estimation. However, human action recognition is still far from human-level performance. Owing to the articulated nature of the human body, it is challenging to detect an action from multiple viewpoints, particularly from an aerial viewpoint. This is further compounded by a scarcity of datasets that cover multiple viewpoints of actions. To fill this gap and enable research in wider application areas, we present a multi-viewpoint outdoor action recognition dataset collected from YouTube and our own drone. The dataset consists of 20 dynamic human action classes, 2324 video clips and 503086 frames. All videos are cropped and resized to 720x720 without distorting the original aspect ratio of the human subjects in videos. This dataset should be useful to many research areas including action recognition, surveillance and situational awareness. We evaluated the dataset with a two-stream CNN architecture coupled with a recently proposed temporal pooling scheme called kernelized rank pooling that produces nonlinear feature subspace representations. The overall baseline action recognition accuracy is 74.0%.
* 10 pages, 4 figures
Sim2real gap is non-monotonic with robot complexity for morphology-in-the-loop flapping wing design
Oct 30, 2019


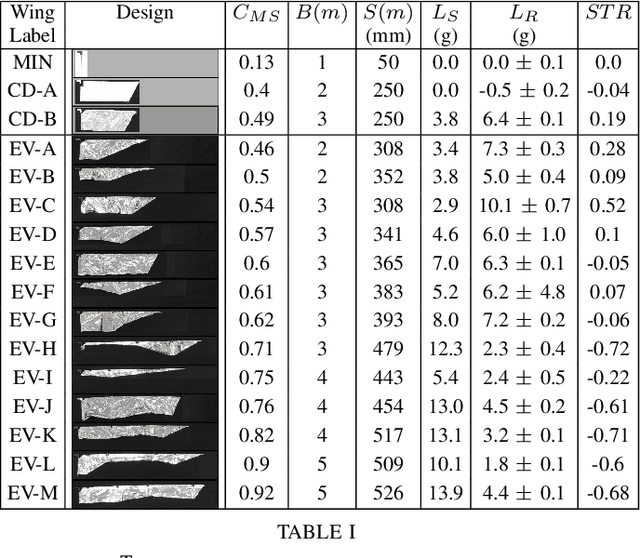
Morphology of a robot design is important to its ability to achieve a stated goal and therefore applying machine learning approaches that incorporate morphology in the design space can provide scope for significant advantage. Our study is set in a domain known to be reliant on morphology: flapping wing flight. We developed a parameterised morphology design space that draws features from biological exemplars and apply automated design to produce a set of high performance robot morphologies in simulation. By performing sim2real transfer on a selection, for the first time we measure the shape of the reality gap for variations in design complexity. We found for the flapping wing that the reality gap changes non-monotonically with complexity, suggesting that certain morphology details narrow the gap more than others, and that such details could be identified and further optimised in a future end-to-end automated morphology design process.
UAV-GESTURE: A Dataset for UAV Control and Gesture Recognition
Jan 09, 2019
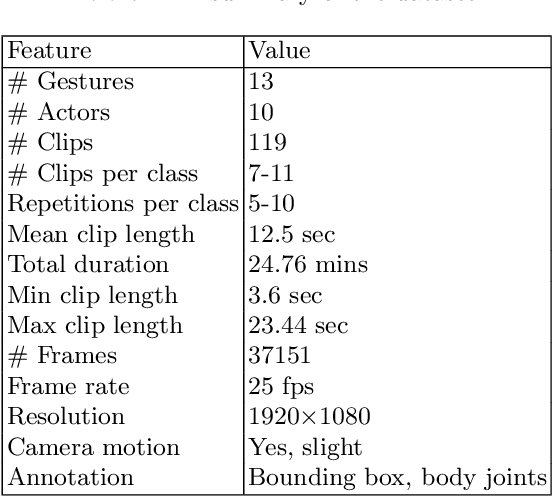


Current UAV-recorded datasets are mostly limited to action recognition and object tracking, whereas the gesture signals datasets were mostly recorded in indoor spaces. Currently, there is no outdoor recorded public video dataset for UAV commanding signals. Gesture signals can be effectively used with UAVs by leveraging the UAVs visual sensors and operational simplicity. To fill this gap and enable research in wider application areas, we present a UAV gesture signals dataset recorded in an outdoor setting. We selected 13 gestures suitable for basic UAV navigation and command from general aircraft handling and helicopter handling signals. We provide 119 high-definition video clips consisting of 37151 frames. The overall baseline gesture recognition performance computed using Pose-based Convolutional Neural Network (P-CNN) is 91.9 %. All the frames are annotated with body joints and gesture classes in order to extend the dataset's applicability to a wider research area including gesture recognition, action recognition, human pose recognition and situation awareness.
Human Pose and Path Estimation from Aerial Video using Dynamic Classifier Selection
Dec 16, 2018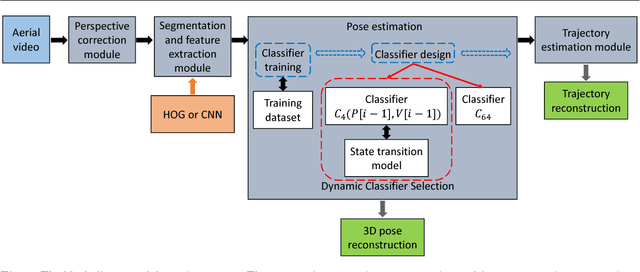
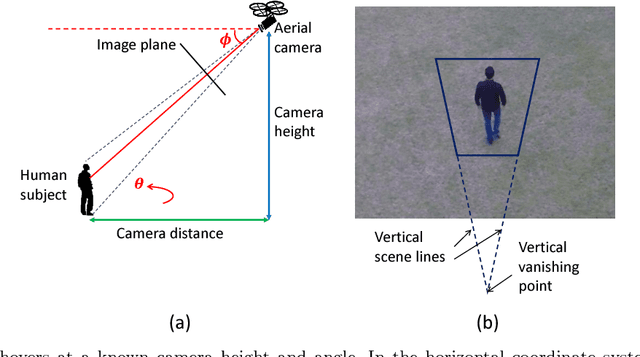
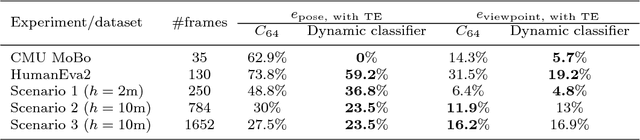

We consider the problem of estimating human pose and trajectory by an aerial robot with a monocular camera in near real time. We present a preliminary solution whose distinguishing feature is a dynamic classifier selection architecture. In our solution, each video frame is corrected for perspective using projective transformation. Then, two alternative feature sets are used: (i) Histogram of Oriented Gradients (HOG) of the silhouette, (ii) Convolutional Neural Network (CNN) features of the RGB image. The features (HOG or CNN) are classified using a dynamic classifier. A class is defined as a pose-viewpoint pair, and a total of 64 classes are defined to represent a forward walking and turning gait sequence. Our solution provides three main advantages: (i) Classification is efficient due to dynamic selection (4-class vs. 64-class classification). (ii) Classification errors are confined to neighbors of the true view-points. (iii) The robust temporal relationship between poses is used to resolve the left-right ambiguities of human silhouettes. Experiments conducted on both fronto-parallel videos and aerial videos confirm our solution can achieve accurate pose and trajectory estimation for both scenarios. We found using HOG features provides higher accuracy than using CNN features. For example, applying the HOG-based variant of our scheme to the 'walking on a figure 8-shaped path' dataset (1652 frames) achieved estimation accuracies of 99.6% for viewpoints and 96.2% for number of poses.
* For associated dataset, see https://asankagp.github.io/aerialgaitdataset/