 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Sensing Strategy: Multi-Modal, Multi-Robot Source Localization and Mapping in Real-World Settings with Fixed One-Way Switching
Jul 01, 2024This paper introduces a state-machine model for a multi-modal, multi-robot environmental sensing algorithm tailored to dynamic real-world settings. The algorithm uniquely combines two exploration strategies for gas source localization and mapping: (1) an initial exploration phase using multi-robot coverage path planning with variable formations for early gas field indication; and (2) a subsequent active sensing phase employing multi-robot swarms for precise field estimation. The state machine governs the transition between these two phases. During exploration, a coverage path maximizes the visited area while measuring gas concentration and estimating the initial gas field at predefined sample times. In the active sensing phase, mobile robots in a swarm collaborate to select the next measurement point, ensuring coordinated and efficient sensing. System validation involves hardware-in-the-loop experiments and real-time tests with a radio source emulating a gas field. The approach is benchmarked against state-of-the-art single-mode active sensing and gas source localization techniques. Evaluation highlights the multi-modal switching approach's ability to expedite convergence, navigate obstacles in dynamic environments, and significantly enhance gas source location accuracy. The findings show a 43% reduction in turnaround time, a 50% increase in estimation accuracy, and improved robustness of multi-robot environmental sensing in cluttered scenarios without collisions, surpassing the performance of conventional active sensing strategies.
A Multi-viewpoint Outdoor Dataset for Human Action Recognition
Oct 07, 2021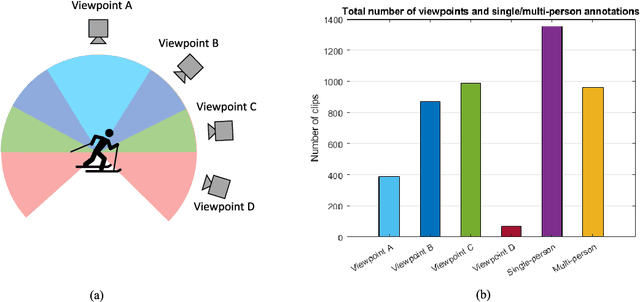

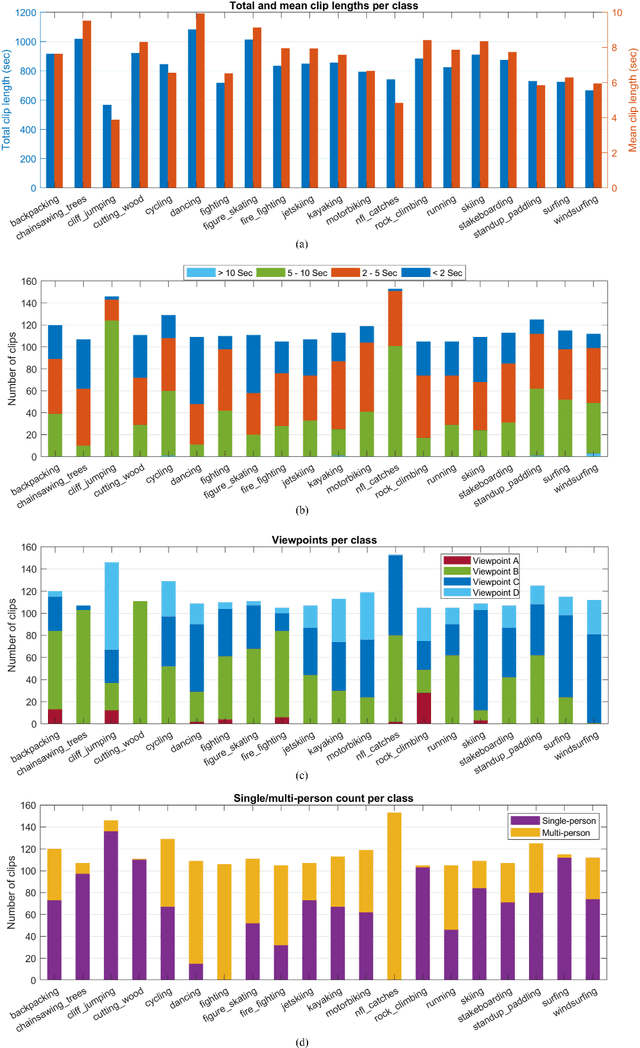
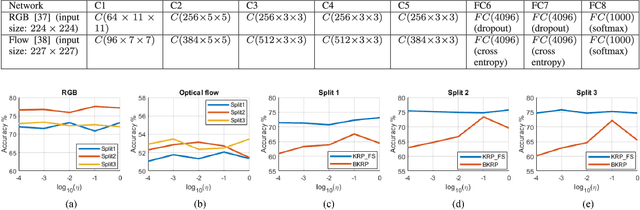
Advancements in deep neural networks have contributed to near perfect results for many computer vision problems such as object recognition, face recognition and pose estimation. However, human action recognition is still far from human-level performance. Owing to the articulated nature of the human body, it is challenging to detect an action from multiple viewpoints, particularly from an aerial viewpoint. This is further compounded by a scarcity of datasets that cover multiple viewpoints of actions. To fill this gap and enable research in wider application areas, we present a multi-viewpoint outdoor action recognition dataset collected from YouTube and our own drone. The dataset consists of 20 dynamic human action classes, 2324 video clips and 503086 frames. All videos are cropped and resized to 720x720 without distorting the original aspect ratio of the human subjects in videos. This dataset should be useful to many research areas including action recognition, surveillance and situational awareness. We evaluated the dataset with a two-stream CNN architecture coupled with a recently proposed temporal pooling scheme called kernelized rank pooling that produces nonlinear feature subspace representations. The overall baseline action recognition accuracy is 74.0%.
* 10 pages, 4 figures