 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Effective Human-Swarm Interaction Interfaces: Insights from a User Study on Task Performance
Apr 03, 2025In this paper, we present a systematic method of design for human-swarm interaction interfaces, combining theoretical insights with empirical evaluation. We first derive ten design principles from existing literature, apply them to key information dimensions identified through goal-directed task analysis and developed a tablet-based interface for a target search task. We then conducted a user study with 31 participants where humans were required to guide a robotic swarm to a target in the presence of three types of hazards that pose a risk to the robots: Distributed, Moving, and Spreading. Performance was measured based on the proximity of the robots to the target and the number of deactivated robots at the end of the task. Results indicate that at least one robot was bought closer to the target in 98% of tasks, demonstrating the interface's success fulfilling the primary objective of the task. Additionally, in nearly 67% of tasks, more than 50% of the robots reached the target. Moreover, particularly better performance was noted in moving hazards. Additionally, the interface appeared to help minimize robot deactivation, as evidenced by nearly 94% of tasks where participants managed to keep more than 50% of the robots active, ensuring that most of the swarm remained operational. However, its effectiveness varied across hazards, with robot deactivation being lowest in distributed hazard scenarios, suggesting that the interface provided the most support in these conditions.
A Study on Human-Swarm Interaction: A Framework for Assessing Situation Awareness and Task Performance
Mar 19, 2025This paper introduces a framework for human swarm interaction studies that measures situation awareness in dynamic environments. A tablet-based interface was developed for a user study by implementing the concepts introduced in the framework, where operators guided a robotic swarm in a single-target search task, marking hazardous cells unknown to the swarm. Both subjective and objective situation awareness measures were used, with task performance evaluated based on how close the robots were to the target. The framework enabled a structured investigation of the role of situation awareness in human swarm interaction, leading to key findings such as improved task performance across attempts, showing the interface was learnable, centroid active robot position proved to be a useful task performance metric for assessing situation awareness, perception and projection played a key role in task performance, highlighting their importance in interface design and both subjective and objective situation awareness influenced task performance, emphasizing the need for interfaces that support both. These findings validate our framework as a structured approach for integrating situation awareness concepts into human swarm interaction studies, offering a systematic way to assess situation awareness and task performance. The framework can be applied to other swarming studies to evaluate interface learnability, identify meaningful task performance metrics, and refine interface designs to enhance situation awareness, ultimately improving human swarm interaction in dynamic environments.
Active Sensing Strategy: Multi-Modal, Multi-Robot Source Localization and Mapping in Real-World Settings with Fixed One-Way Switching
Jul 01, 2024This paper introduces a state-machine model for a multi-modal, multi-robot environmental sensing algorithm tailored to dynamic real-world settings. The algorithm uniquely combines two exploration strategies for gas source localization and mapping: (1) an initial exploration phase using multi-robot coverage path planning with variable formations for early gas field indication; and (2) a subsequent active sensing phase employing multi-robot swarms for precise field estimation. The state machine governs the transition between these two phases. During exploration, a coverage path maximizes the visited area while measuring gas concentration and estimating the initial gas field at predefined sample times. In the active sensing phase, mobile robots in a swarm collaborate to select the next measurement point, ensuring coordinated and efficient sensing. System validation involves hardware-in-the-loop experiments and real-time tests with a radio source emulating a gas field. The approach is benchmarked against state-of-the-art single-mode active sensing and gas source localization techniques. Evaluation highlights the multi-modal switching approach's ability to expedite convergence, navigate obstacles in dynamic environments, and significantly enhance gas source location accuracy. The findings show a 43% reduction in turnaround time, a 50% increase in estimation accuracy, and improved robustness of multi-robot environmental sensing in cluttered scenarios without collisions, surpassing the performance of conventional active sensing strategies.
Radio Source Localization using Sparse Signal Measurements from Uncrewed Ground Vehicles
Dec 06, 2023



Radio source localization can benefit many fields, including wireless communications, radar, radio astronomy, wireless sensor networks, positioning systems, and surveillance systems. However, accurately estimating the position of a radio transmitter using a remote sensor is not an easy task, as many factors contribute to the highly dynamic behavior of radio signals. In this study, we investigate techniques to use a mobile robot to explore an outdoor area and localize the radio source using sparse Received Signal Strength Indicator (RSSI) measurements. We propose a novel radio source localization method with fast turnaround times and reduced complexity compared to the state-of-the-art. Our technique uses RSSI measurements collected while the robot completed a sparse trajectory using a coverage path planning map. The mean RSSI within each grid cell was used to find the most likely cell containing the source. Three techniques were analyzed with the data from eight field tests using a mobile robot. The proposed method can localize a gas source in a basketball field with a 1.2 m accuracy and within three minutes of convergence time, whereas the state-of-the-art active sensing technique took more than 30 minutes to reach a source estimation accuracy below 1 m.
A Robust Policy Bootstrapping Algorithm for Multi-objective Reinforcement Learning in Non-stationary Environments
Aug 18, 2023



Multi-objective Markov decision processes are a special kind of multi-objective optimization problem that involves sequential decision making while satisfying the Markov property of stochastic processes. Multi-objective reinforcement learning methods address this problem by fusing the reinforcement learning paradigm with multi-objective optimization techniques. One major drawback of these methods is the lack of adaptability to non-stationary dynamics in the environment. This is because they adopt optimization procedures that assume stationarity to evolve a coverage set of policies that can solve the problem. This paper introduces a developmental optimization approach that can evolve the policy coverage set while exploring the preference space over the defined objectives in an online manner. We propose a novel multi-objective reinforcement learning algorithm that can robustly evolve a convex coverage set of policies in an online manner in non-stationary environments. We compare the proposed algorithm with two state-of-the-art multi-objective reinforcement learning algorithms in stationary and non-stationary environments. Results showed that the proposed algorithm significantly outperforms the existing algorithms in non-stationary environments while achieving comparable results in stationary environments.
Coverage Path Planning with Budget Constraints for Multiple Unmanned Ground Vehicles
Jun 07, 2023



This paper proposes a state-machine model for a multi-modal, multi-robot environmental sensing algorithm. This multi-modal algorithm integrates two different exploration algorithms: (1) coverage path planning using variable formations and (2) collaborative active sensing using multi-robot swarms. The state machine provides the logic for when to switch between these different sensing algorithms. We evaluate the performance of the proposed approach on a gas source localisation and mapping task. We use hardware-in-the-loop experiments and real-time experiments with a radio source simulating a real gas field. We compare the proposed approach with a single-mode, state-of-the-art collaborative active sensing approach. Our results indicate that our multi-modal switching approach can converge more rapidly than single-mode active sensing.
Fusing Interpretable Knowledge of Neural Network Learning Agents For Swarm-Guidance
Apr 01, 2022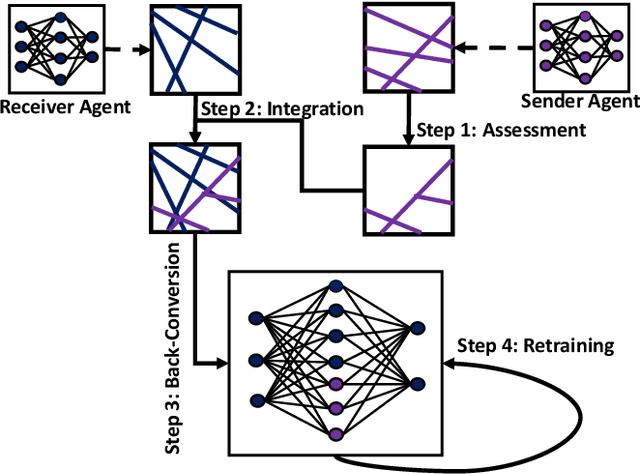
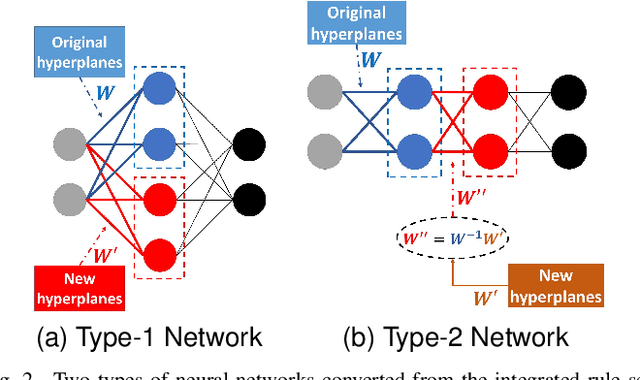
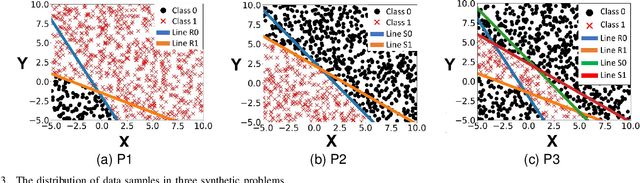
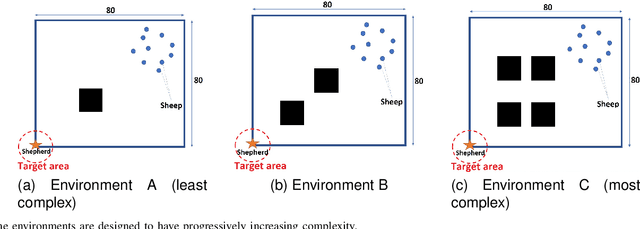
Neural-based learning agents make decisions using internal artificial neural networks. In certain situations, it becomes pertinent that this knowledge is re-interpreted in a friendly form to both the human and the machine. These situations include: when agents are required to communicate the knowledge they learn to each other in a transparent way in the presence of an external human observer, in human-machine teaming settings where humans and machines need to collaborate on a task, or where there is a requirement to verify the knowledge exchanged between the agents. We propose an interpretable knowledge fusion framework suited for neural-based learning agents, and propose a Priority on Weak State Areas (PoWSA) retraining technique. We first test the proposed framework on a synthetic binary classification task before evaluating it on a shepherding-based multi-agent swarm guidance task. Results demonstrate that the proposed framework increases the success rate on the swarm-guidance environment by 11% and better stability in return for a modest increase in computational cost of 14.5% to achieve interpretability. Moreover, the framework presents the knowledge learnt by an agent in a human-friendly representation, leading to a better descriptive visual representation of an agent's knowledge.
Robust Multi-Robot Coverage of Unknown Environments using a Distributed Robot Swarm
Nov 29, 2021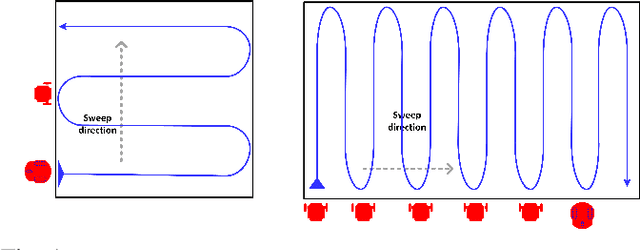
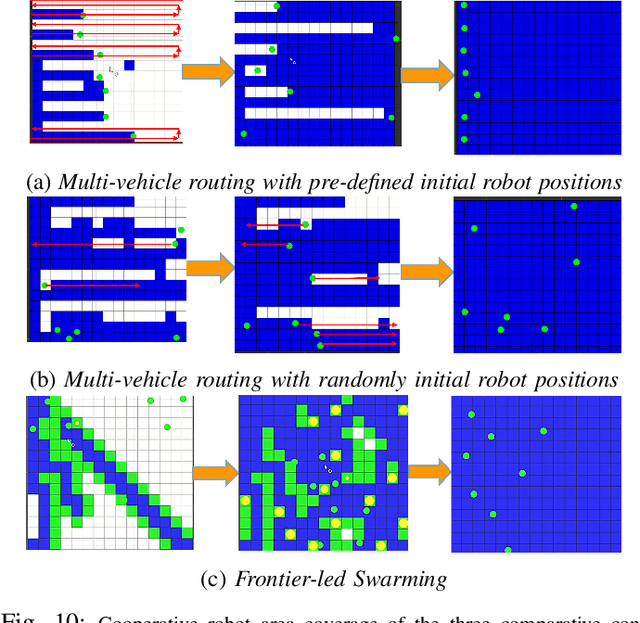
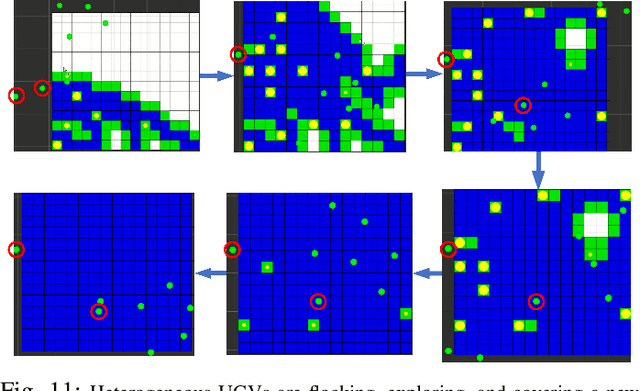

In mobile robotics, area exploration and coverage are critical capabilities. In most of the available research, a common assumption is global, long-range communication and centralised cooperation. This paper proposes a novel swarm-based coverage control algorithm that relaxes these assumptions. The algorithm combines two elements: swarm rules and frontier search algorithms. Inspired by natural systems in which large numbers of simple agents (e.g., schooling fish, flocking birds, swarming insects) perform complicated collective behaviors, the first element uses three simple rules to maintain a swarm formation in a distributed manner. The second element provides means to select promising regions to explore (and cover) using the minimization of a cost function involving the agent's relative position to the frontier cells and the frontier's size. We tested our approach's performance on both heterogeneous and homogeneous groups of mobile robots in different environments. We measure both coverage performance and swarm formation statistics that permit the group to maintain communication. Through a series of comparison experiments, we demonstrate the proposed strategy has superior performance over recently presented map coverage methodologies and the conventional artificial potential field based on a percentage of cell-coverage, turnaround, and safe paths while maintaining a formation that permits short-range communication.
Continuous Deep Hierarchical Reinforcement Learning for Ground-Air Swarm Shepherding
Apr 27, 2020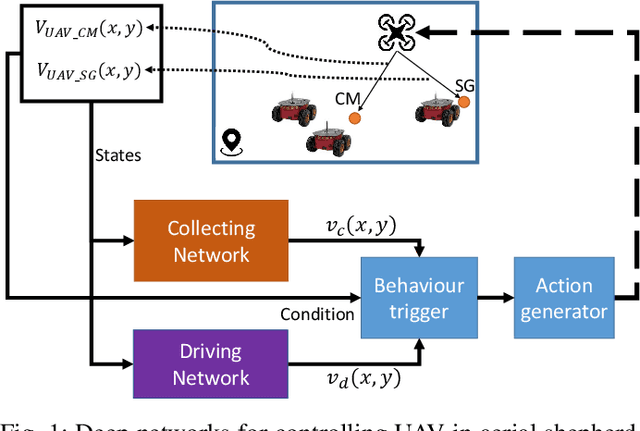
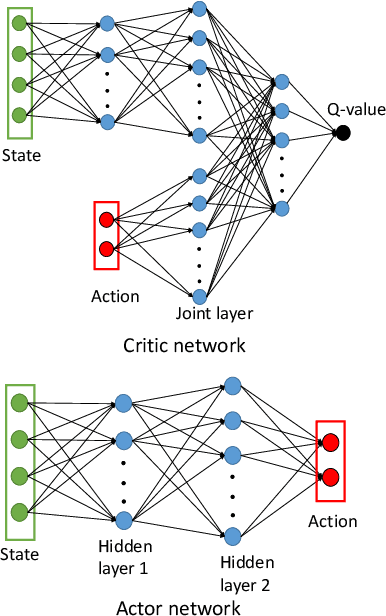


The control and guidance of multi-robots (swarm) is a non-trivial problem due to the complexity inherent in the coupled interaction among the group. Whether the swarm is cooperative or non cooperative, lessons could be learnt from sheepdogs herding sheep. Biomimicry of shepherding offers computational methods for swarm control with the potential to generalize and scale in different environments. However, learning to shepherd is complex due to the large search space that a machine learner is faced with. We present a deep hierarchical reinforcement learning approach for shepherding, whereby an unmanned aerial vehicle (UAV) learns to act as an Aerial sheepdog to control and guide a swarm of unmanned ground vehicles (UGVs). The approach extends our previous work on machine education to decompose the search space into hierarchically organized curriculum. Each lesson in the curriculum is learnt by a deep reinforcement learning model. The hierarchy is formed by fusing the outputs of the model. The approach is demonstrated first in a high-fidelity robotic-operating-system (ROS)-based simulation environment, then with physical UGVs and a UAV in an in-door testing facility. We investigate the ability of the method to generalize as the models move from simulation to the real-world and as the models move from one scale to another.
Apprenticeship Bootstrapping Via Deep Learning with a Safety Net for UAV-UGV Interaction
Oct 10, 2018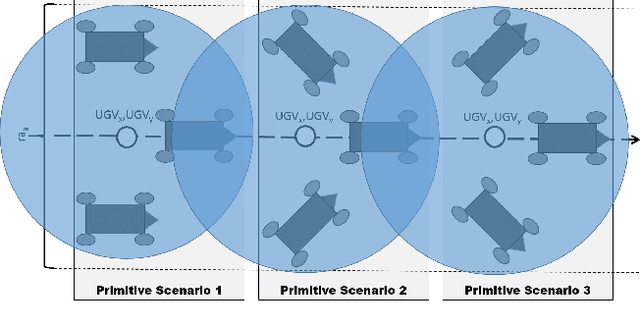

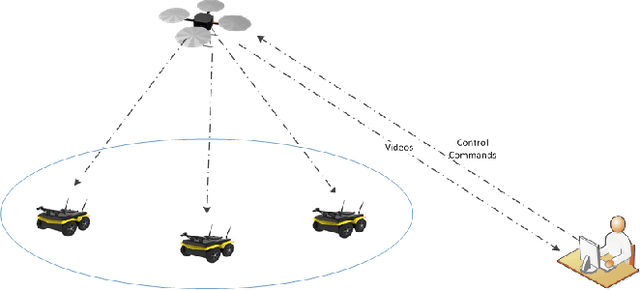

In apprenticeship learning (AL), agents learn by watching or acquiring human demonstrations on some tasks of interest. However, the lack of human demonstrations in novel tasks where they may not be a human expert yet, or when it is too expensive and/or time consuming to acquire human demonstrations motivated a new algorithm: Apprenticeship bootstrapping (ABS). The basic idea is to learn from demonstrations on sub-tasks then autonomously bootstrap a model on the main, more complex, task. The original ABS used inverse reinforcement learning (ABS-IRL). However, the approach is not suitable for continuous action spaces. In this paper, we propose ABS via Deep learning (ABS-DL). It is first validated in a simulation environment on an aerial and ground coordination scenario, where an Unmanned Aerial Vehicle (UAV) is required to maintain three Unmanned Ground Vehicles (UGVs) within a field of view of the UAV 's camera (FoV). Moving a machine learning algorithm from a simulation environment to an actual physical platform is challenging because `mistakes' made by the algorithm while learning could lead to the damage of the platform. We then take this extra step to test the algorithm in a physical environment. We propose a safety-net as a protection layer to ensure that the autonomy of the algorithm in learning does not compromise the safety of the platform. The tests of ABS-DL in the real environment can guarantee a damage-free, collision avoidance behaviour of autonomous bodies. The results show that performance of the proposed approach is comparable to that of a human, and competitive to the traditional approach using expert demonstrations performed on the composite task. The proposed safety-net approach demonstrates its advantages when it enables the UAV to operate more safely under the control of the ABS-DL algorithm.