 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Long-Term Time-Series Forecasting via Meta Transformer Networks
Jan 25, 2024



A reliable long-term time-series forecaster is highly demanded in practice but comes across many challenges such as low computational and memory footprints as well as robustness against dynamic learning environments. This paper proposes Meta-Transformer Networks (MANTRA) to deal with the dynamic long-term time-series forecasting tasks. MANTRA relies on the concept of fast and slow learners where a collection of fast learners learns different aspects of data distributions while adapting quickly to changes. A slow learner tailors suitable representations to fast learners. Fast adaptations to dynamic environments are achieved using the universal representation transformer layers producing task-adapted representations with a small number of parameters. Our experiments using four datasets with different prediction lengths demonstrate the advantage of our approach with at least $3\%$ improvements over the baseline algorithms for both multivariate and univariate settings. Source codes of MANTRA are publicly available in \url{https://github.com/anwarmaxsum/MANTRA}.
Radio Source Localization using Sparse Signal Measurements from Uncrewed Ground Vehicles
Dec 06, 2023



Radio source localization can benefit many fields, including wireless communications, radar, radio astronomy, wireless sensor networks, positioning systems, and surveillance systems. However, accurately estimating the position of a radio transmitter using a remote sensor is not an easy task, as many factors contribute to the highly dynamic behavior of radio signals. In this study, we investigate techniques to use a mobile robot to explore an outdoor area and localize the radio source using sparse Received Signal Strength Indicator (RSSI) measurements. We propose a novel radio source localization method with fast turnaround times and reduced complexity compared to the state-of-the-art. Our technique uses RSSI measurements collected while the robot completed a sparse trajectory using a coverage path planning map. The mean RSSI within each grid cell was used to find the most likely cell containing the source. Three techniques were analyzed with the data from eight field tests using a mobile robot. The proposed method can localize a gas source in a basketball field with a 1.2 m accuracy and within three minutes of convergence time, whereas the state-of-the-art active sensing technique took more than 30 minutes to reach a source estimation accuracy below 1 m.
Coverage Path Planning with Budget Constraints for Multiple Unmanned Ground Vehicles
Jun 07, 2023



This paper proposes a state-machine model for a multi-modal, multi-robot environmental sensing algorithm. This multi-modal algorithm integrates two different exploration algorithms: (1) coverage path planning using variable formations and (2) collaborative active sensing using multi-robot swarms. The state machine provides the logic for when to switch between these different sensing algorithms. We evaluate the performance of the proposed approach on a gas source localisation and mapping task. We use hardware-in-the-loop experiments and real-time experiments with a radio source simulating a real gas field. We compare the proposed approach with a single-mode, state-of-the-art collaborative active sensing approach. Our results indicate that our multi-modal switching approach can converge more rapidly than single-mode active sensing.
Scalable Adversarial Online Continual Learning
Sep 04, 2022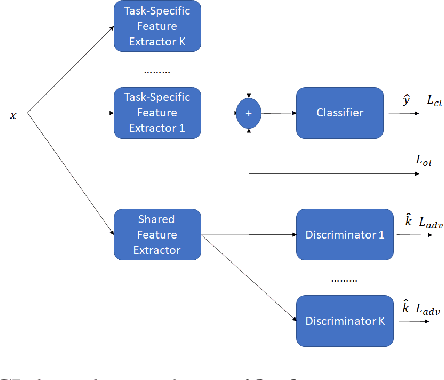
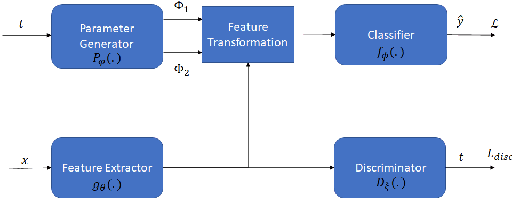
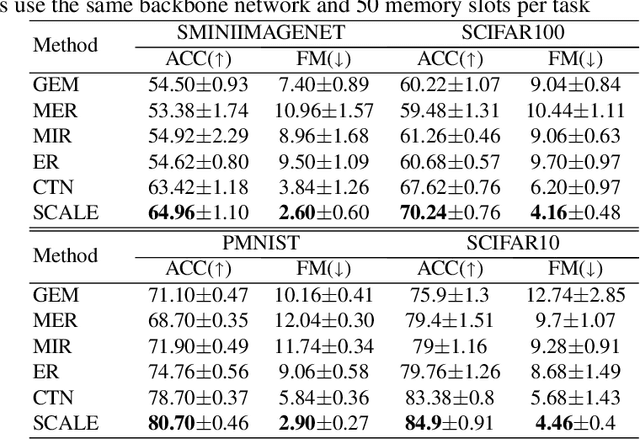
Adversarial continual learning is effective for continual learning problems because of the presence of feature alignment process generating task-invariant features having low susceptibility to the catastrophic forgetting problem. Nevertheless, the ACL method imposes considerable complexities because it relies on task-specific networks and discriminators. It also goes through an iterative training process which does not fit for online (one-epoch) continual learning problems. This paper proposes a scalable adversarial continual learning (SCALE) method putting forward a parameter generator transforming common features into task-specific features and a single discriminator in the adversarial game to induce common features. The training process is carried out in meta-learning fashions using a new combination of three loss functions. SCALE outperforms prominent baselines with noticeable margins in both accuracy and execution time.
Continuous Deep Hierarchical Reinforcement Learning for Ground-Air Swarm Shepherding
Apr 27, 2020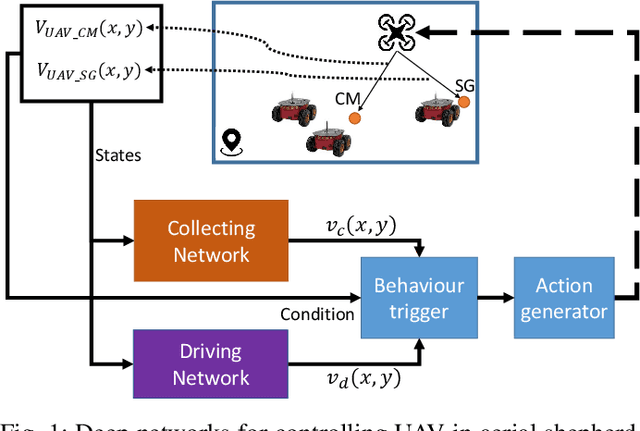
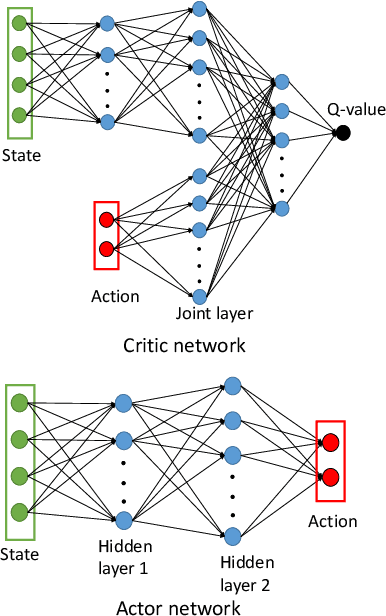


The control and guidance of multi-robots (swarm) is a non-trivial problem due to the complexity inherent in the coupled interaction among the group. Whether the swarm is cooperative or non cooperative, lessons could be learnt from sheepdogs herding sheep. Biomimicry of shepherding offers computational methods for swarm control with the potential to generalize and scale in different environments. However, learning to shepherd is complex due to the large search space that a machine learner is faced with. We present a deep hierarchical reinforcement learning approach for shepherding, whereby an unmanned aerial vehicle (UAV) learns to act as an Aerial sheepdog to control and guide a swarm of unmanned ground vehicles (UGVs). The approach extends our previous work on machine education to decompose the search space into hierarchically organized curriculum. Each lesson in the curriculum is learnt by a deep reinforcement learning model. The hierarchy is formed by fusing the outputs of the model. The approach is demonstrated first in a high-fidelity robotic-operating-system (ROS)-based simulation environment, then with physical UGVs and a UAV in an in-door testing facility. We investigate the ability of the method to generalize as the models move from simulation to the real-world and as the models move from one scale to another.
Crossing the Reality Gap with Evolved Plastic Neurocontrollers
Feb 23, 2020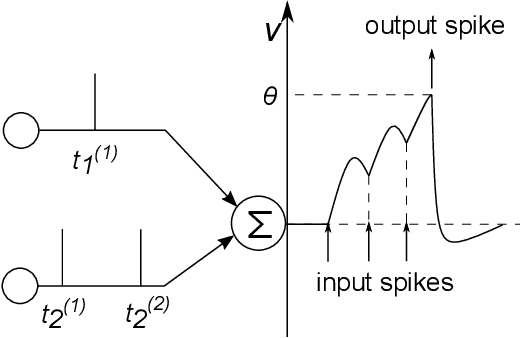

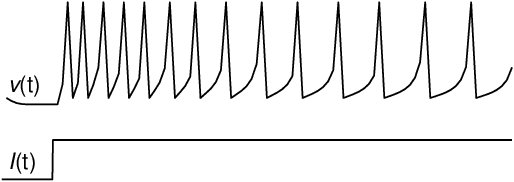
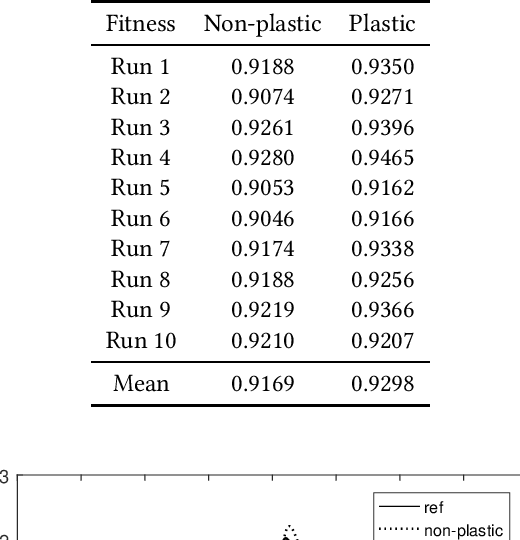
A critical issue in evolutionary robotics is the transfer of controllers learned in simulation to reality. This is especially the case for small Unmanned Aerial Vehicles (UAVs), as the platforms are highly dynamic and susceptible to breakage. Previous approaches often require simulation models with a high level of accuracy, otherwise significant errors may arise when the well-designed controller is being deployed onto the targeted platform. Here we try to overcome the transfer problem from a different perspective, by designing a spiking neurocontroller which uses synaptic plasticity to cross the reality gap via online adaptation. Through a set of experiments we show that the evolved plastic spiking controller can maintain its functionality by self-adapting to model changes that take place after evolutionary training, and consequently exhibit better performance than its non-plastic counterpart.
Evolving Spiking Neural Networks for Nonlinear Control Problems
Mar 04, 2019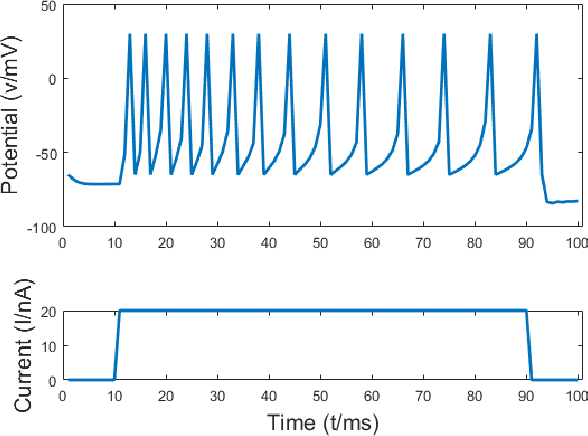
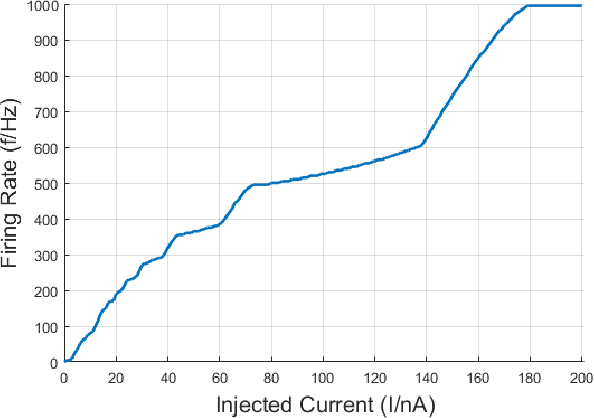
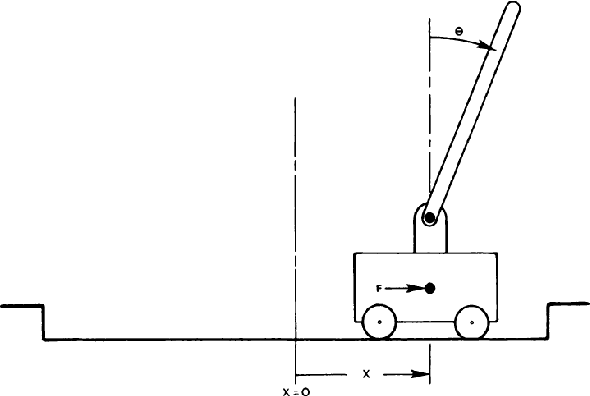
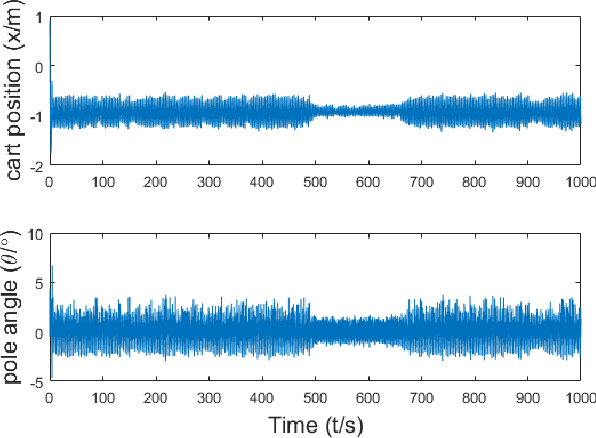
Spiking Neural Networks are powerful computational modelling tools that have attracted much interest because of the bioinspired modelling of synaptic interactions between neurons. Most of the research employing spiking neurons has been non-behavioural and discontinuous. Comparatively, this paper presents a recurrent spiking controller that is capable of solving nonlinear control problems in continuous domains using a popular topology evolution algorithm as the learning mechanism. We propose two mechanisms necessary to the decoding of continuous signals from discrete spike transmission: (i) a background current component to maintain frequency sufficiency for spike rate decoding, and (ii) a general network structure that derives strength from topology evolution. We demonstrate that the proposed spiking controller can learn significantly faster to discover functional solutions than sigmoidal neural networks in solving a classic nonlinear control problem.
Apprenticeship Bootstrapping Via Deep Learning with a Safety Net for UAV-UGV Interaction
Oct 10, 2018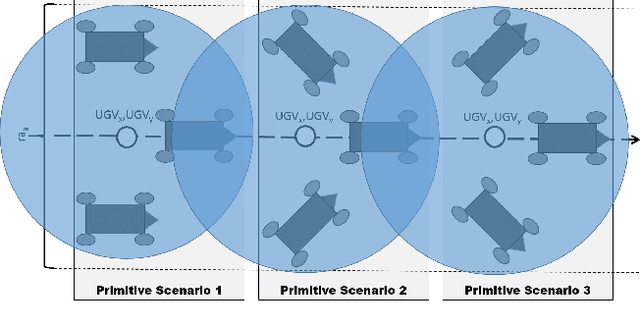

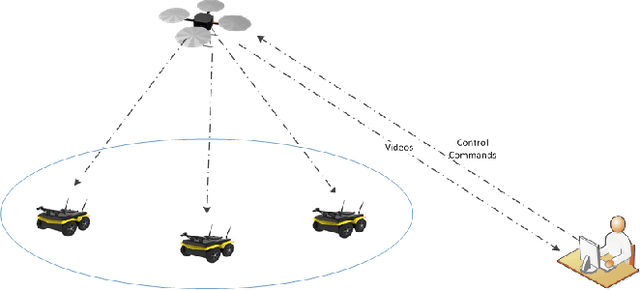

In apprenticeship learning (AL), agents learn by watching or acquiring human demonstrations on some tasks of interest. However, the lack of human demonstrations in novel tasks where they may not be a human expert yet, or when it is too expensive and/or time consuming to acquire human demonstrations motivated a new algorithm: Apprenticeship bootstrapping (ABS). The basic idea is to learn from demonstrations on sub-tasks then autonomously bootstrap a model on the main, more complex, task. The original ABS used inverse reinforcement learning (ABS-IRL). However, the approach is not suitable for continuous action spaces. In this paper, we propose ABS via Deep learning (ABS-DL). It is first validated in a simulation environment on an aerial and ground coordination scenario, where an Unmanned Aerial Vehicle (UAV) is required to maintain three Unmanned Ground Vehicles (UGVs) within a field of view of the UAV 's camera (FoV). Moving a machine learning algorithm from a simulation environment to an actual physical platform is challenging because `mistakes' made by the algorithm while learning could lead to the damage of the platform. We then take this extra step to test the algorithm in a physical environment. We propose a safety-net as a protection layer to ensure that the autonomy of the algorithm in learning does not compromise the safety of the platform. The tests of ABS-DL in the real environment can guarantee a damage-free, collision avoidance behaviour of autonomous bodies. The results show that performance of the proposed approach is comparable to that of a human, and competitive to the traditional approach using expert demonstrations performed on the composite task. The proposed safety-net approach demonstrates its advantages when it enables the UAV to operate more safely under the control of the ABS-DL algorithm.