 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROL : Rehearsal Free Continual Learning in Streaming Data via Prompt Online Learning
Jul 16, 2025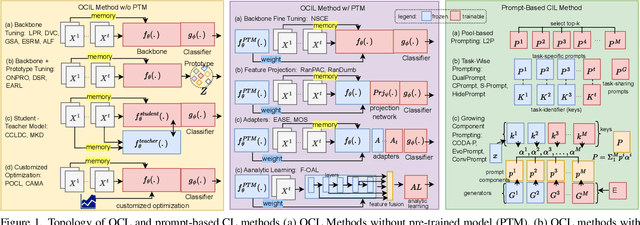
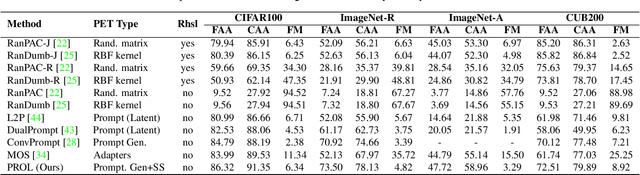
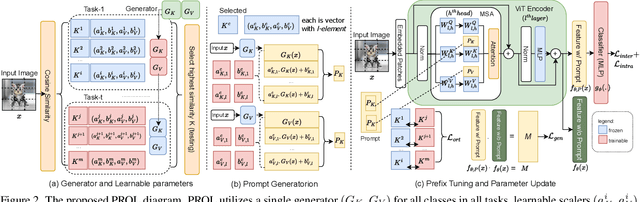
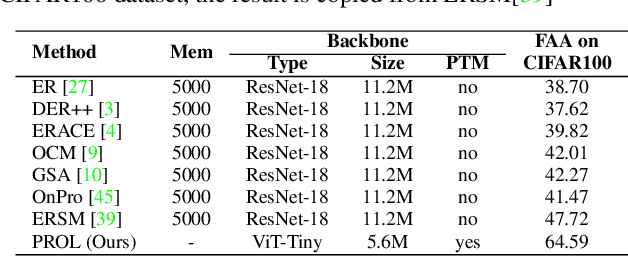
The data privacy constraint in online continual learning (OCL), where the data can be seen only once, complicates the catastrophic forgetting problem in streaming data. A common approach applied by the current SOTAs in OCL is with the use of memory saving exemplars or features from previous classes to be replayed in the current task. On the other hand, the prompt-based approach performs excellently in continual learning but with the cost of a growing number of trainable parameters. The first approach may not be applicable in practice due to data openness policy, while the second approach has the issue of throughput associated with the streaming data. In this study, we propose a novel prompt-based method for online continual learning that includes 4 main components: (1) single light-weight prompt generator as a general knowledge, (2) trainable scaler-and-shifter as specific knowledge, (3) pre-trained model (PTM) generalization preserving, and (4) hard-soft updates mechanism. Our proposed method achieves significantly higher performance than the current SOTAs in CIFAR100, ImageNet-R, ImageNet-A, and CUB dataset. Our complexity analysis shows that our method requires a relatively smaller number of parameters and achieves moderate training time, inference time, and throughput. For further study, the source code of our method is available at https://github.com/anwarmaxsum/PROL.
Onboard Optimization and Learning: A Survey
May 07, 2025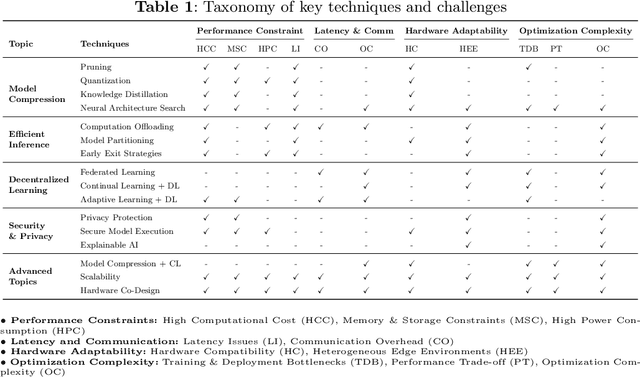
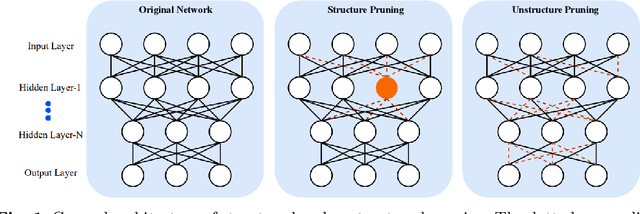
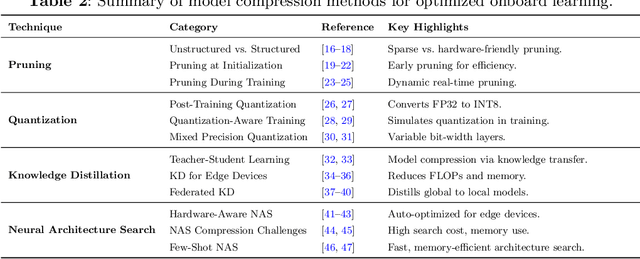
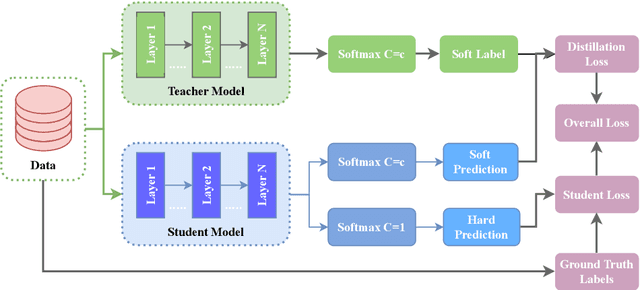
Onboard learning is a transformative approach in edge AI, enabling real-time data processing, decision-making, and adaptive model training directly on resource-constrained devices without relying on centralized servers. This paradigm is crucial for applications demanding low latency, enhanced privacy, and energy efficiency. However, onboard learning faces challenges such as limited computational resources, high inference costs, and security vulnerabilities. This survey explores a comprehensive range of methodologies that address these challenges, focusing on techniques that optimize model efficiency, accelerate inference, and support collaborative learning across distributed devices. Approaches for reducing model complexity, improving inference speed, and ensuring privacy-preserving computation are examined alongside emerging strategies that enhance scalability and adaptability in dynamic environments. By bridging advancements in hardware-software co-design, model compression, and decentralized learning, this survey provides insights into the current state of onboard learning to enable robust, efficient, and secure AI deployment at the edge.
PIP: Prototypes-Injected Prompt for Federated Class Incremental Learning
Jul 30, 2024



Federated Class Incremental Learning (FCIL) is a new direction in continual learning (CL) for addressing catastrophic forgetting and non-IID data distribution simultaneously. Existing FCIL methods call for high communication costs and exemplars from previous classes. We propose a novel rehearsal-free method for FCIL named prototypes-injected prompt (PIP) that involves 3 main ideas: a) prototype injection on prompt learning, b) prototype augmentation, and c) weighted Gaussian aggregation on the server side. Our experiment result shows that the proposed method outperforms the current state of the arts (SOTAs) with a significant improvement (up to 33%) in CIFAR100, MiniImageNet and TinyImageNet datasets. Our extensive analysis demonstrates the robustness of PIP in different task sizes, and the advantage of requiring smaller participating local clients, and smaller global rounds. For further study, source codes of PIP, baseline, and experimental logs are shared publicly in https://github.com/anwarmaxsum/PIP.
Dynamic Long-Term Time-Series Forecasting via Meta Transformer Networks
Jan 25, 2024



A reliable long-term time-series forecaster is highly demanded in practice but comes across many challenges such as low computational and memory footprints as well as robustness against dynamic learning environments. This paper proposes Meta-Transformer Networks (MANTRA) to deal with the dynamic long-term time-series forecasting tasks. MANTRA relies on the concept of fast and slow learners where a collection of fast learners learns different aspects of data distributions while adapting quickly to changes. A slow learner tailors suitable representations to fast learners. Fast adaptations to dynamic environments are achieved using the universal representation transformer layers producing task-adapted representations with a small number of parameters. Our experiments using four datasets with different prediction lengths demonstrate the advantage of our approach with at least $3\%$ improvements over the baseline algorithms for both multivariate and univariate settings. Source codes of MANTRA are publicly available in \url{https://github.com/anwarmaxsum/MANTRA}.
Few-Shot Continual Learning via Flat-to-Wide Approaches
Jul 14, 2023



Existing approaches on continual learning call for a lot of samples in their training processes. Such approaches are impractical for many real-world problems having limited samples because of the overfitting problem. This paper proposes a few-shot continual learning approach, termed FLat-tO-WidE AppRoach (FLOWER), where a flat-to-wide learning process finding the flat-wide minima is proposed to address the catastrophic forgetting problem. The issue of data scarcity is overcome with a data augmentation approach making use of a ball generator concept to restrict the sampling space into the smallest enclosing ball. Our numerical studies demonstrate the advantage of FLOWER achieving significantly improved performances over prior arts notably in the small base tasks. For further study, source codes of FLOWER, competitor algorithms and experimental logs are shared publicly in \url{https://github.com/anwarmaxsum/FLOWER}.
On Quantified Linguistic Approximation
Jan 23, 2013
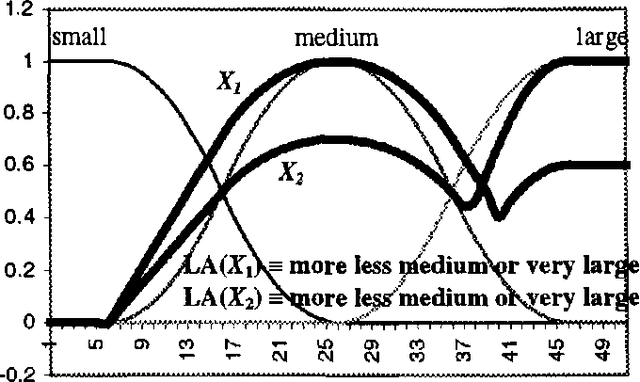

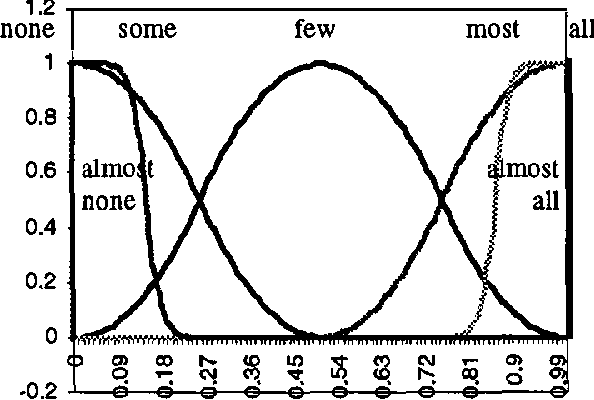
Most fuzzy systems including fuzzy decision support and fuzzy control systems provide out-puts in the form of fuzzy sets that represent the inferred conclusions. Linguistic interpretation of such outputs often involves the use of linguistic approximation that assigns a linguistic label to a fuzzy set based on the predefined primary terms, linguistic modifiers and linguistic connectives. More generally, linguistic approximation can be formalized in the terms of the re-translation rules that correspond to the translation rules in ex-plicitation (e.g. simple, modifier, composite, quantification and qualification rules) in com-puting with words [Zadeh 1996]. However most existing methods of linguistic approximation use the simple, modifier and composite re-translation rules only. Although these methods can provide a sufficient approximation of simple fuzzy sets the approximation of more complex ones that are typical in many practical applications of fuzzy systems may be less satisfactory. Therefore the question arises why not use in linguistic ap-proximation also other re-translation rules corre-sponding to the translation rules in explicitation to advantage. In particular linguistic quantifica-tion may be desirable in situations where the conclusions interpreted as quantified linguistic propositions can be more informative and natu-ral. This paper presents some aspects of linguis-tic approximation in the context of the re-translation rules and proposes an approach to linguistic approximation with the use of quantifi-cation rules, i.e. quantified linguistic approxima-tion. Two methods of the quantified linguistic approximation are considered with the use of lin-guistic quantifiers based on the concepts of the non-fuzzy and fuzzy cardinalities of fuzzy sets. A number of examples are provided to illustrate the proposed approach.
Efficient algorithm for estimation of qualitative expected utility in possibilistic case-based reasoning
Jul 04, 2012

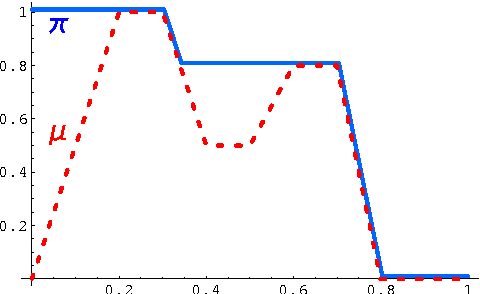

We propose an efficient algorithm for estimation of possibility based qualitative expected utility. It is useful for decision making mechanisms where each possible decision is assigned a multi-attribute possibility distribution. The computational complexity of ordinary methods calculating the expected utility based on discretization is growing exponentially with the number of attributes, and may become infeasible with a high number of these attributes. We present series of theorems and lemmas proving the correctness of our algorithm that exibits a linear computational complexity. Our algorithm has been applied in the context of selecting the most prospective partners in multi-party multi-attribute negotiation, and can also be used in making decisions about potential offers during the negotiation as other similar problems.
An Efficient Protocol for Negotiation over Combinatorial Domains with Incomplete Information
Feb 14, 2012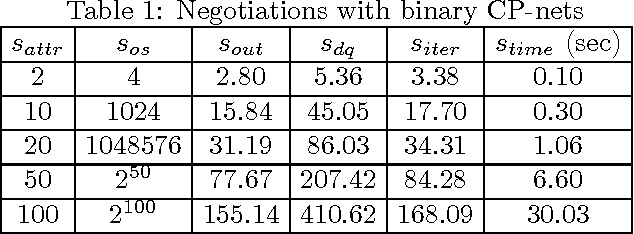
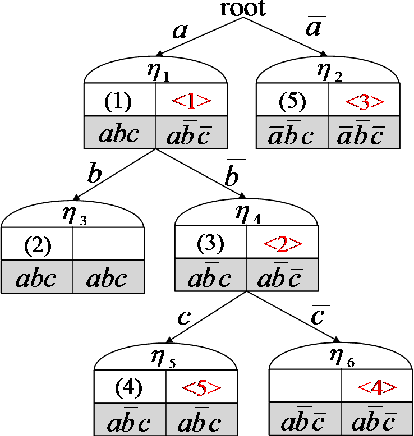
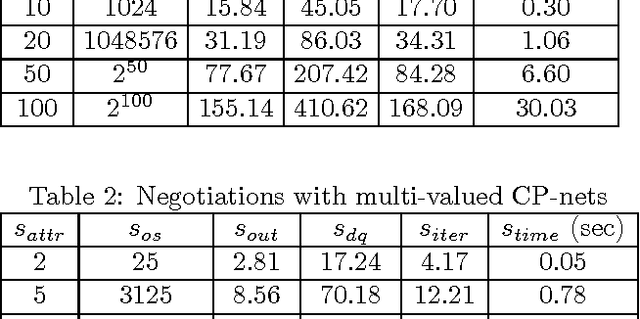

We study the problem of agent-based negotiation in combinatorial domains. It is difficult to reach optimal agreements in bilateral or multi-lateral negotiations when the agents' preferences for the possible alternatives are not common knowledge. Self-interested agents often end up negotiating inefficient agreements in such situations. In this paper, we present a protocol for negotiation in combinatorial domains which can lead rational agents to reach optimal agreements under incomplete information setting. Our proposed protocol enables the negotiating agents to identify efficient solutions using distributed search that visits only a small subspace of the whole outcome space. Moreover, the proposed protocol is sufficiently general that it is applicable to most preference representation models in combinatorial domains. We also present results of experiments that demonstrate the feasibility and computational efficiency of our approach.