 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Continual Learning via Flat-to-Wide Approaches
Jul 14, 2023



Existing approaches on continual learning call for a lot of samples in their training processes. Such approaches are impractical for many real-world problems having limited samples because of the overfitting problem. This paper proposes a few-shot continual learning approach, termed FLat-tO-WidE AppRoach (FLOWER), where a flat-to-wide learning process finding the flat-wide minima is proposed to address the catastrophic forgetting problem. The issue of data scarcity is overcome with a data augmentation approach making use of a ball generator concept to restrict the sampling space into the smallest enclosing ball. Our numerical studies demonstrate the advantage of FLOWER achieving significantly improved performances over prior arts notably in the small base tasks. For further study, source codes of FLOWER, competitor algorithms and experimental logs are shared publicly in \url{https://github.com/anwarmaxsum/FLOWER}.
Assessor-Guided Learning for Continual Environments
Mar 21, 2023



This paper proposes an assessor-guided learning strategy for continual learning where an assessor guides the learning process of a base learner by controlling the direction and pace of the learning process thus allowing an efficient learning of new environments while protecting against the catastrophic interference problem. The assessor is trained in a meta-learning manner with a meta-objective to boost the learning process of the base learner. It performs a soft-weighting mechanism of every sample accepting positive samples while rejecting negative samples. The training objective of a base learner is to minimize a meta-weighted combination of the cross entropy loss function, the dark experience replay (DER) loss function and the knowledge distillation loss function whose interactions are controlled in such a way to attain an improved performance. A compensated over-sampling (COS) strategy is developed to overcome the class imbalanced problem of the episodic memory due to limited memory budgets. Our approach, Assessor-Guided Learning Approach (AGLA), has been evaluated in the class-incremental and task-incremental learning problems. AGLA achieves improved performances compared to its competitors while the theoretical analysis of the COS strategy is offered. Source codes of AGLA, baseline algorithms and experimental logs are shared publicly in \url{https://github.com/anwarmaxsum/AGLA} for further study.
Evolving Multi-Label Fuzzy Classifier
Mar 29, 2022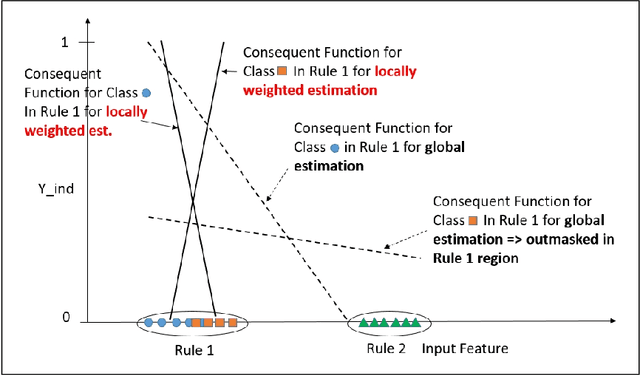


Multi-label classification has attracted much attention in the machine learning community to address the problem of assigning single samples to more than one class at the same time. We propose an evolving multi-label fuzzy classifier (EFC-ML) which is able to self-adapt and self-evolve its structure with new incoming multi-label samples in an incremental, single-pass manner. It is based on a multi-output Takagi-Sugeno type architecture, where for each class a separate consequent hyper-plane is defined. The learning procedure embeds a locally weighted incremental correlation-based algorithm combined with (conventional) recursive fuzzily weighted least squares and Lasso-based regularization. The correlation-based part ensures that the interrelations between class labels, a specific well-known property in multi-label classification for improved performance, are preserved properly; the Lasso-based regularization reduces the curse of dimensionality effects in the case of a higher number of inputs. Antecedent learning is achieved by product-space clustering and conducted for all class labels together, which yields a single rule base, allowing a compact knowledge view. Furthermore, our approach comes with an online active learning (AL) strategy for updating the classifier on just a number of selected samples, which in turn makes the approach applicable for scarcely labelled streams in applications, where the annotation effort is typically expensive. Our approach was evaluated on several data sets from the MULAN repository and showed significantly improved classification accuracy compared to (evolving) one-versus-rest or classifier chaining concepts. A significant result was that, due to the online AL method, a 90\% reduction in the number of samples used for classifier updates had little effect on the accumulated accuracy trend lines compared to a full update in most data set cases.
Unsupervised Continual Learning via Self-Adaptive Deep Clustering Approach
Jun 28, 2021
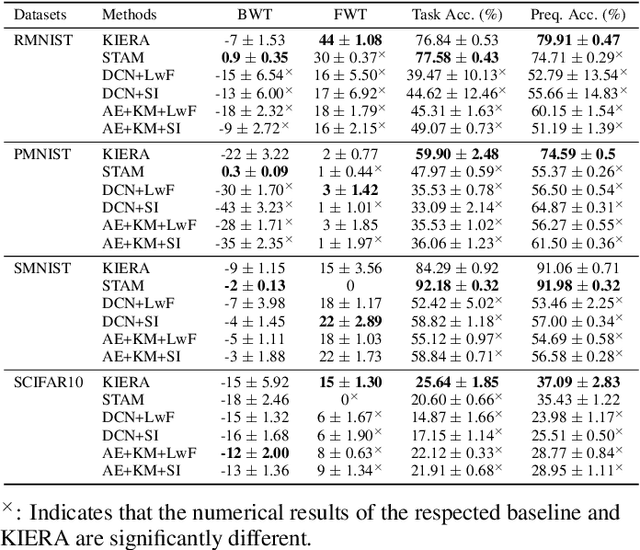
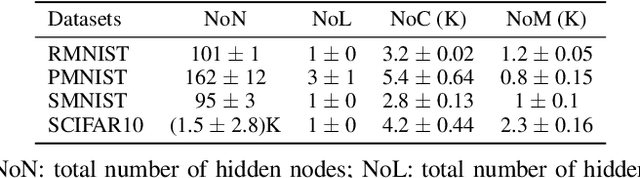
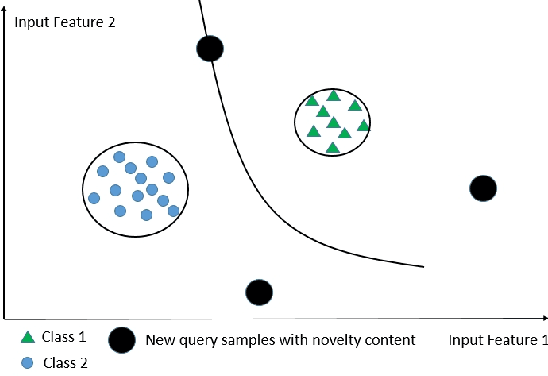
Unsupervised continual learning remains a relatively uncharted territory in the existing literature because the vast majority of existing works call for unlimited access of ground truth incurring expensive labelling cost. Another issue lies in the problem of task boundaries and task IDs which must be known for model's updates or model's predictions hindering feasibility for real-time deployment. Knowledge Retention in Self-Adaptive Deep Continual Learner, (KIERA), is proposed in this paper. KIERA is developed from the notion of flexible deep clustering approach possessing an elastic network structure to cope with changing environments in the timely manner. The centroid-based experience replay is put forward to overcome the catastrophic forgetting problem. KIERA does not exploit any labelled samples for model updates while featuring a task-agnostic merit. The advantage of KIERA has been numerically validated in popular continual learning problems where it shows highly competitive performance compared to state-of-the art approaches. Our implementation is available in \textit{\url{https://github.com/ContinualAL/KIERA}}.
Autonomous Deep Quality Monitoring in Streaming Environments
Jun 26, 2021



The common practice of quality monitoring in industry relies on manual inspection well-known to be slow, error-prone and operator-dependent. This issue raises strong demand for automated real-time quality monitoring developed from data-driven approaches thus alleviating from operator dependence and adapting to various process uncertainties. Nonetheless, current approaches do not take into account the streaming nature of sensory information while relying heavily on hand-crafted features making them application-specific. This paper proposes the online quality monitoring methodology developed from recently developed deep learning algorithms for data streams, Neural Networks with Dynamically Evolved Capacity (NADINE), namely NADINE++. It features the integration of 1-D and 2-D convolutional layers to extract natural features of time-series and visual data streams captured from sensors and cameras of the injection molding machines from our own project. Real-time experiments have been conducted where the online quality monitoring task is simulated on the fly under the prequential test-then-train fashion - the prominent data stream evaluation protocol. Comparison with the state-of-the-art techniques clearly exhibits the advantage of NADINE++ with 4.68\% improvement on average for the quality monitoring task in streaming environments. To support the reproducible research initiative, codes, results of NADINE++ along with supplementary materials and injection molding dataset are made available in \url{https://github.com/ContinualAL/NADINE-IJCNN2021}.
* This paper has been accepted for publication in IJCNN, 2021
Scalable Teacher Forcing Network for Semi-Supervised Large Scale Data Streams
Jun 26, 2021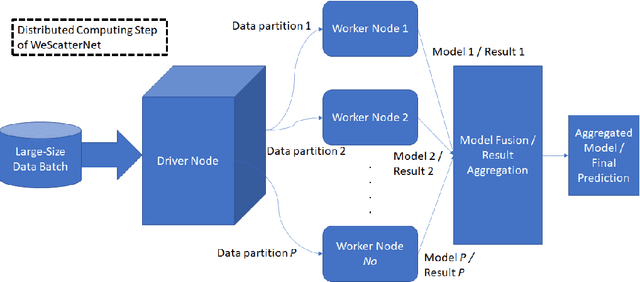
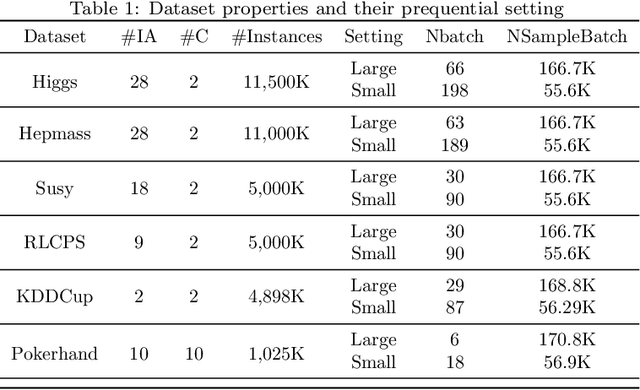
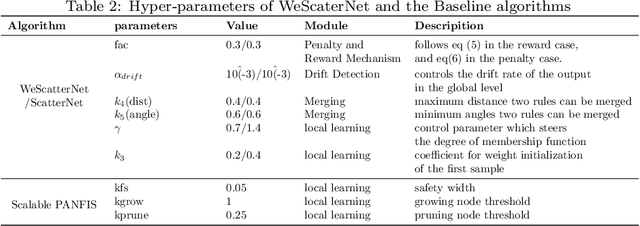
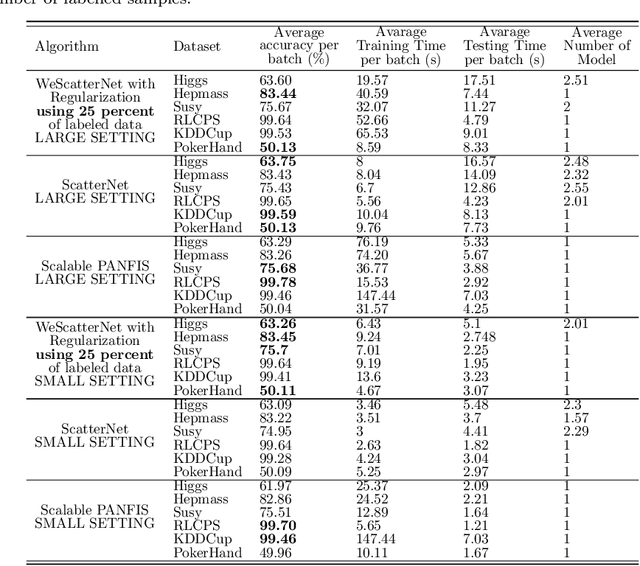
The large-scale data stream problem refers to high-speed information flow which cannot be processed in scalable manner under a traditional computing platform. This problem also imposes expensive labelling cost making the deployment of fully supervised algorithms unfeasible. On the other hand, the problem of semi-supervised large-scale data streams is little explored in the literature because most works are designed in the traditional single-node computing environments while also being fully supervised approaches. This paper offers Weakly Supervised Scalable Teacher Forcing Network (WeScatterNet) to cope with the scarcity of labelled samples and the large-scale data streams simultaneously. WeScatterNet is crafted under distributed computing platform of Apache Spark with a data-free model fusion strategy for model compression after parallel computing stage. It features an open network structure to address the global and local drift problems while integrating a data augmentation, annotation and auto-correction ($DA^3$) method for handling partially labelled data streams. The performance of WeScatterNet is numerically evaluated in the six large-scale data stream problems with only $25\%$ label proportions. It shows highly competitive performance even if compared with fully supervised learners with $100\%$ label proportions.
* This paper has been accepted for publication in Information Sciences
ATL: Autonomous Knowledge Transfer from Many Streaming Processes
Oct 19, 2019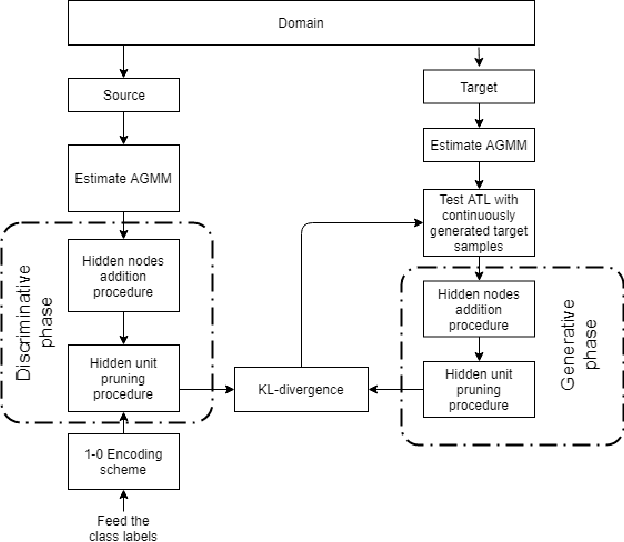
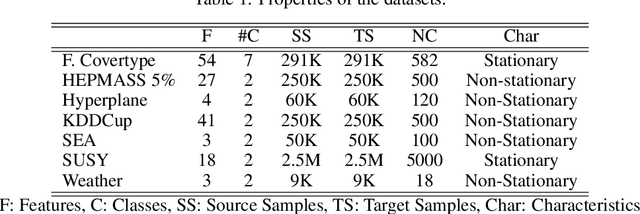
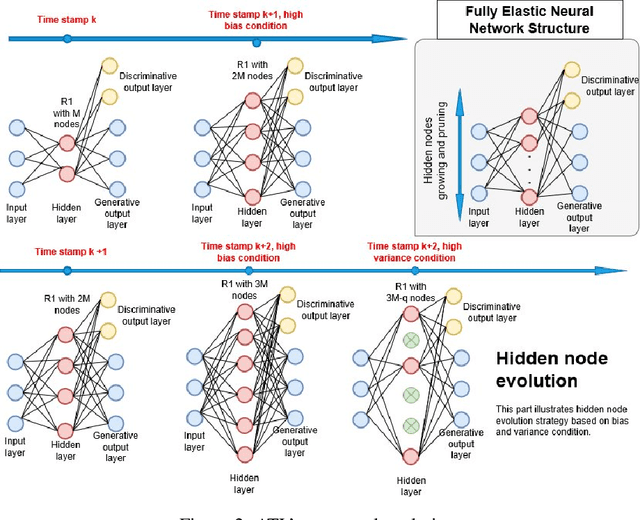
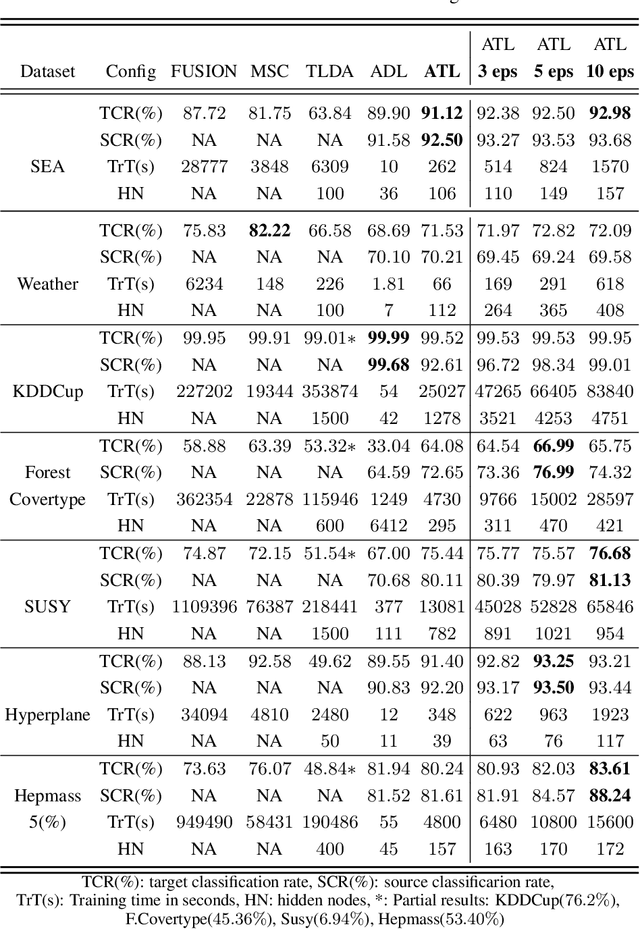
Transferring knowledge across many streaming processes remains an uncharted territory in the existing literature and features unique characteristics: no labelled instance of the target domain, covariate shift of source and target domain, different period of drifts in the source and target domains. Autonomous transfer learning (ATL) is proposed in this paper as a flexible deep learning approach for the online unsupervised transfer learning problem across many streaming processes. ATL offers an online domain adaptation strategy via the generative and discriminative phases coupled with the KL divergence based optimization strategy to produce a domain invariant network while putting forward an elastic network structure. It automatically evolves its network structure from scratch with/without the presence of ground truth to overcome independent concept drifts in the source and target domain. The rigorous numerical evaluation has been conducted along with a comparison against recently published works. ATL demonstrates improved performance while showing significantly faster training speed than its counterparts.
DEVDAN: Deep Evolving Denoising Autoencoder
Oct 08, 2019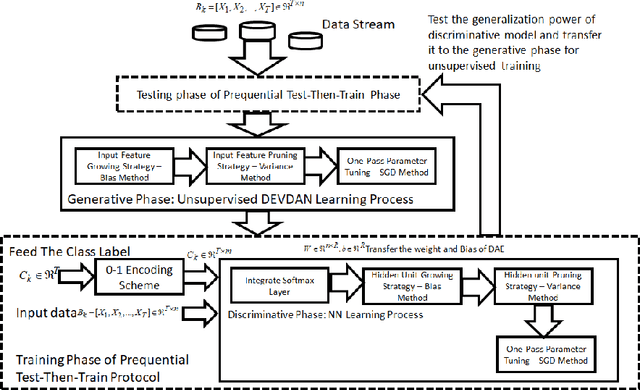

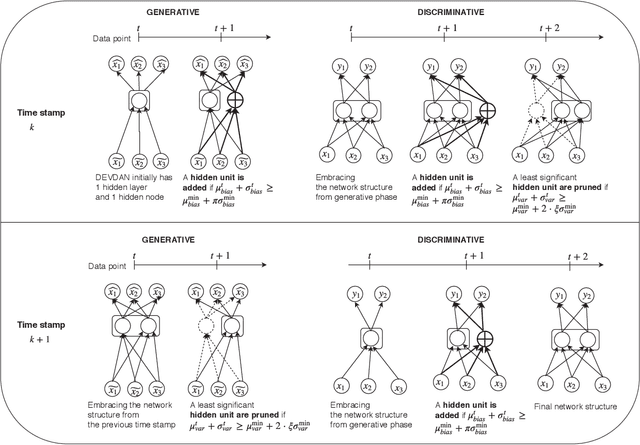
The Denoising Autoencoder (DAE) enhances the flexibility of the data stream method in exploiting unlabeled samples. Nonetheless, the feasibility of DAE for data stream analytic deserves an in-depth study because it characterizes a fixed network capacity that cannot adapt to rapidly changing environments. Deep evolving denoising autoencoder (DEVDAN), is proposed in this paper. It features an open structure in the generative phase and the discriminative phase where the hidden units can be automatically added and discarded on the fly. The generative phase refines the predictive performance of the discriminative model exploiting unlabeled data. Furthermore, DEVDAN is free of the problem-specific threshold and works fully in the single-pass learning fashion. We show that DEVDAN can find competitive network architecture compared with state-of-the-art methods on the classification task using ten prominent datasets simulated under the prequential test-then-train protocol.
PAC: A Novel Self-Adaptive Neuro-Fuzzy Controller for Micro Aerial Vehicles
Nov 09, 2018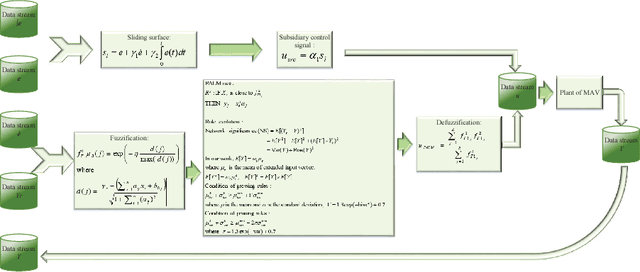
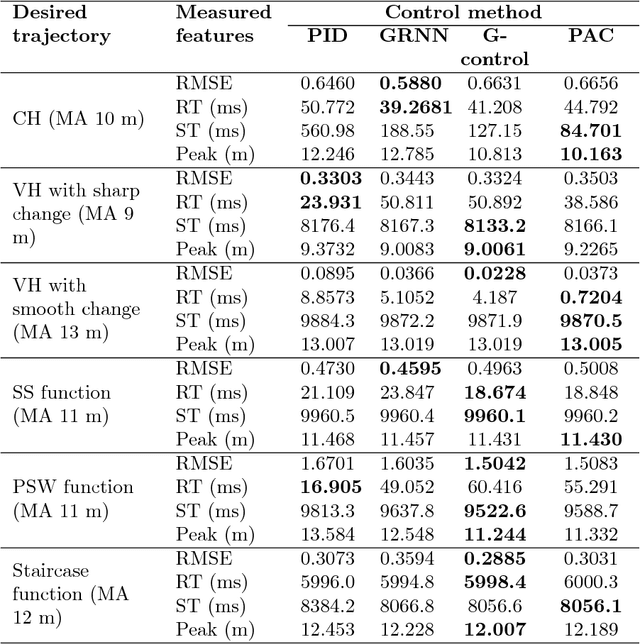
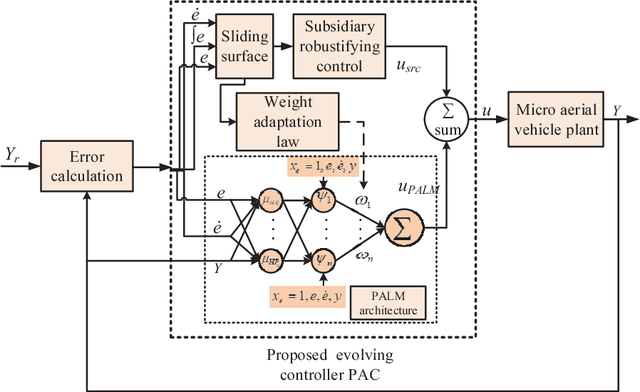
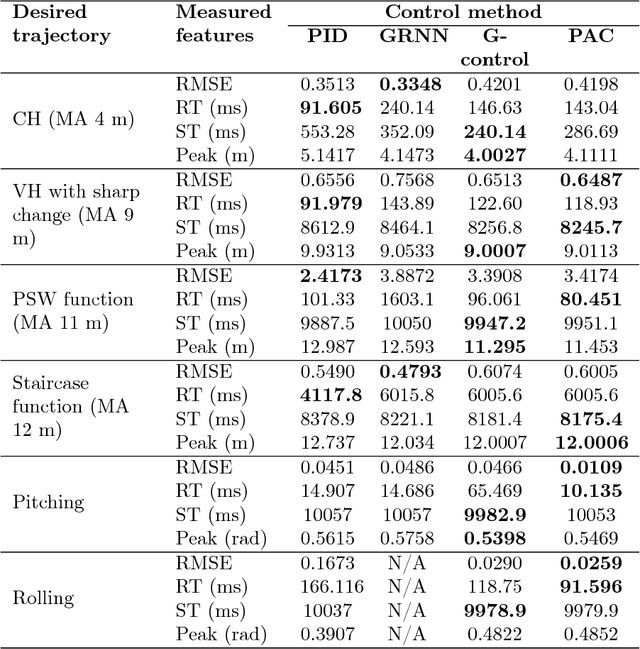
There exists an increasing demand of a flexible and computationally efficient controller for micro aerial vehicles (MAVs) due to a high degree of environmental perturbations. In this work, an evolving neuro-fuzzy controller namely Parsimonious Controller (PAC) is proposed and features less network parameters than conventional approaches due to the absence of rule premise parameters. PAC is built upon a recently developed evolving neuro-fuzzy system known as parsimonious learning machine (PALM) and adopts new rule growing and pruning modules derived from the approximation of bias and variance. These methods has no reliance on user-defined thresholds, thereby increasing its autonomy for the real-time deployment. PAC adapts the consequent parameters with the sliding mode control (SMC) theory in the single-pass fashion. The stability of our PAC is proven utilizing the Lyapunov stability analysis. Lastly, the controller's efficacy is evaluated by observing various trajectory tracking performance from a bio-inspired flapping wing micro aerial vehicle (BI-FWMAV) and a rotary wing micro aerial vehicle called hexacopter. Furthermore, it is compared against three distinctive controller. Our PAC outperforms the linear PID controller and generalized regression neural network (GRNN) based nonlinear adaptive controller. Compared to its predecessor, G-controller, the tracking accuracy is comparable but the PAC incurs significantly less parameters to attain similar or better performance than the G-controller.
Autonomous Deep Learning: Incremental Learning of Denoising Autoencoder for Evolving Data Streams
Sep 24, 2018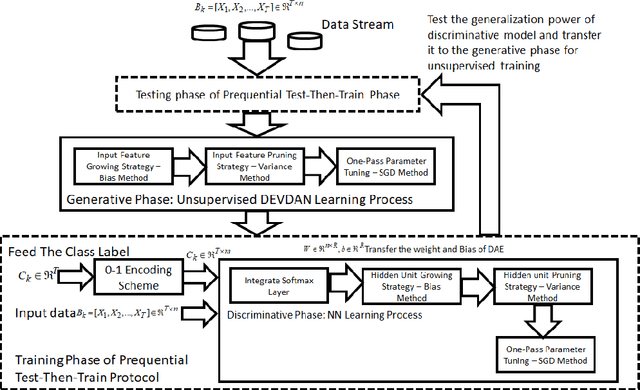
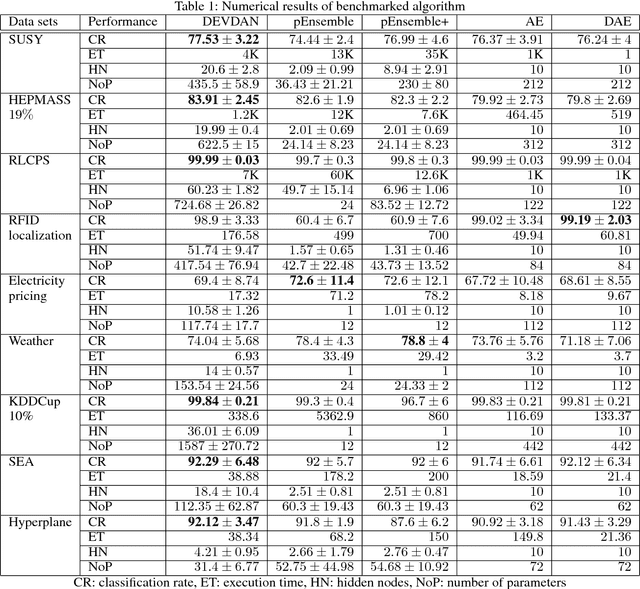
The generative learning phase of Autoencoder (AE) and its successor Denosing Autoencoder (DAE) enhances the flexibility of data stream method in exploiting unlabelled samples. Nonetheless, the feasibility of DAE for data stream analytic deserves in-depth study because it characterizes a fixed network capacity which cannot adapt to rapidly changing environments. An automated construction of a denoising autoeconder, namely deep evolving denoising autoencoder (DEVDAN), is proposed in this paper. DEVDAN features an open structure both in the generative phase and in the discriminative phase where input features can be automatically added and discarded on the fly. A network significance (NS) method is formulated in this paper and is derived from the bias-variance concept. This method is capable of estimating the statistical contribution of the network structure and its hidden units which precursors an ideal state to add or prune input features. Furthermore, DEVDAN is free of the problem- specific threshold and works fully in the single-pass learning fashion. The efficacy of DEVDAN is numerically validated using nine non-stationary data stream problems simulated under the prequential test-then-train protocol where DEVDAN is capable of delivering an improvement of classification accuracy to recently published online learning works while having flexibility in the automatic extraction of robust input features and in adapting to rapidly changing environments.