 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Sensing Strategy: Multi-Modal, Multi-Robot Source Localization and Mapping in Real-World Settings with Fixed One-Way Switching
Jul 01, 2024This paper introduces a state-machine model for a multi-modal, multi-robot environmental sensing algorithm tailored to dynamic real-world settings. The algorithm uniquely combines two exploration strategies for gas source localization and mapping: (1) an initial exploration phase using multi-robot coverage path planning with variable formations for early gas field indication; and (2) a subsequent active sensing phase employing multi-robot swarms for precise field estimation. The state machine governs the transition between these two phases. During exploration, a coverage path maximizes the visited area while measuring gas concentration and estimating the initial gas field at predefined sample times. In the active sensing phase, mobile robots in a swarm collaborate to select the next measurement point, ensuring coordinated and efficient sensing. System validation involves hardware-in-the-loop experiments and real-time tests with a radio source emulating a gas field. The approach is benchmarked against state-of-the-art single-mode active sensing and gas source localization techniques. Evaluation highlights the multi-modal switching approach's ability to expedite convergence, navigate obstacles in dynamic environments, and significantly enhance gas source location accuracy. The findings show a 43% reduction in turnaround time, a 50% increase in estimation accuracy, and improved robustness of multi-robot environmental sensing in cluttered scenarios without collisions, surpassing the performance of conventional active sensing strategies.
Lightweight Monocular Depth Estimation with an Edge Guided Network
Sep 29, 2022
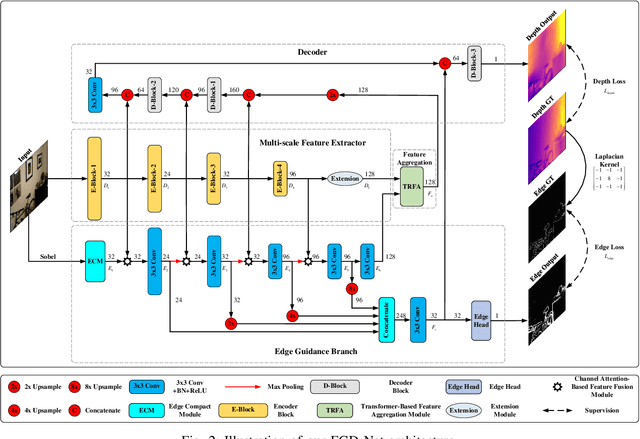
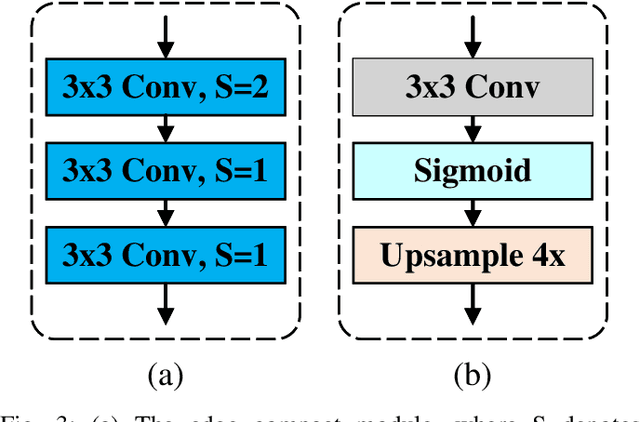
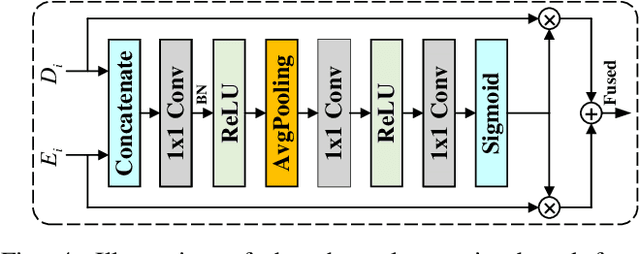
Monocular depth estimation is an important task that can be applied to many robotic applications. Existing methods focus on improving depth estimation accuracy via training increasingly deeper and wider networks, however these suffer from large computational complexity. Recent studies found that edge information are important cues for convolutional neural networks (CNNs) to estimate depth. Inspired by the above observations, we present a novel lightweight Edge Guided Depth Estimation Network (EGD-Net) in this study. In particular, we start out with a lightweight encoder-decoder architecture and embed an edge guidance branch which takes as input image gradients and multi-scale feature maps from the backbone to learn the edge attention features. In order to aggregate the context information and edge attention features, we design a transformer-based feature aggregation module (TRFA). TRFA captures the long-range dependencies between the context information and edge attention features through cross-attention mechanism. We perform extensive experiments on the NYU depth v2 dataset. Experimental results show that the proposed method runs about 96 fps on a Nvidia GTX 1080 GPU whilst achieving the state-of-the-art performance in terms of accuracy.
Improving Self-supervised Learning for Out-of-distribution Task via Auxiliary Classifier
Sep 07, 2022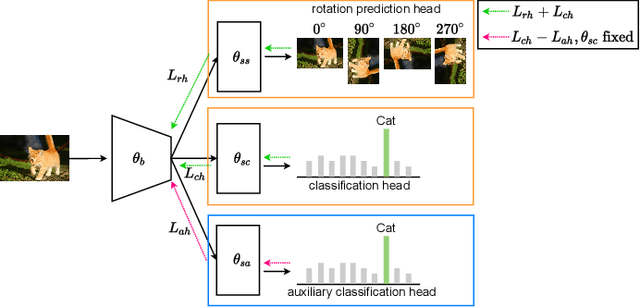
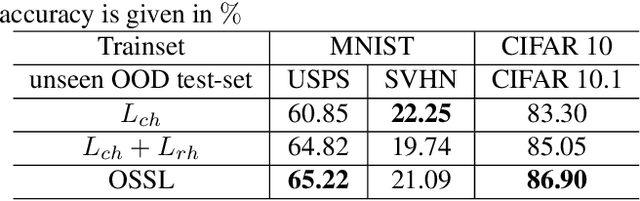

In real world scenarios, out-of-distribution (OOD) datasets may have a large distributional shift from training datasets. This phenomena generally occurs when a trained classifier is deployed on varying dynamic environments, which causes a significant drop in performance. To tackle this issue, we are proposing an end-to-end deep multi-task network in this work. Observing a strong relationship between rotation prediction (self-supervised) accuracy and semantic classification accuracy on OOD tasks, we introduce an additional auxiliary classification head in our multi-task network along with semantic classification and rotation prediction head. To observe the influence of this addition classifier in improving the rotation prediction head, our proposed learning method is framed into bi-level optimisation problem where the upper-level is trained to update the parameters for semantic classification and rotation prediction head. In the lower-level optimisation, only the auxiliary classification head is updated through semantic classification head by fixing the parameters of the semantic classification head. The proposed method has been validated through three unseen OOD datasets where it exhibits a clear improvement in semantic classification accuracy than other two baseline methods. Our code is available on GitHub \url{https://github.com/harshita-555/OSSL}
Latent Preserving Generative Adversarial Network for Imbalance classification
Sep 04, 2022
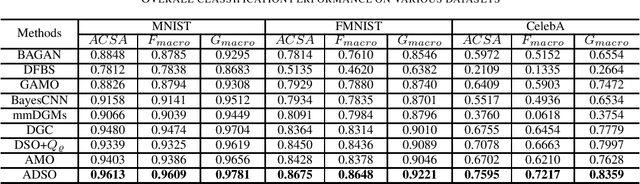
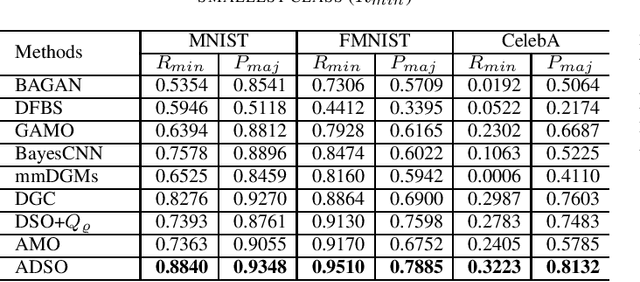
Many real-world classification problems have imbalanced frequency of class labels; a well-known issue known as the "class imbalance" problem. Classic classification algorithms tend to be biased towards the majority class, leaving the classifier vulnerable to misclassification of the minority class. While the literature is rich with methods to fix this problem, as the dimensionality of the problem increases, many of these methods do not scale-up and the cost of running them become prohibitive. In this paper, we present an end-to-end deep generative classifier. We propose a domain-constraint autoencoder to preserve the latent-space as prior for a generator, which is then used to play an adversarial game with two other deep networks, a discriminator and a classifier. Extensive experiments are carried out on three different multi-class imbalanced problems and a comparison with state-of-the-art methods. Experimental results confirmed the superiority of our method over popular algorithms in handling high-dimensional imbalanced classification problems. Our code is available on https://github.com/TanmDL/SLPPL-GAN.
Robust Fuzzy Q-Learning-Based Strictly Negative Imaginary Tracking Controllers for the Uncertain Quadrotor Systems
Mar 26, 2022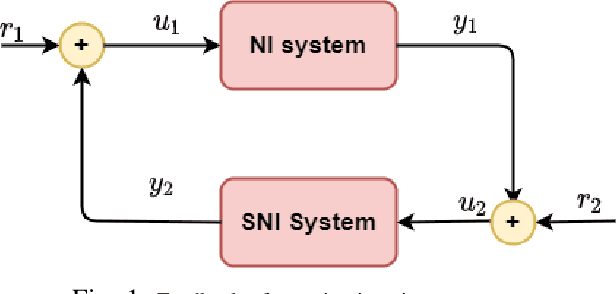
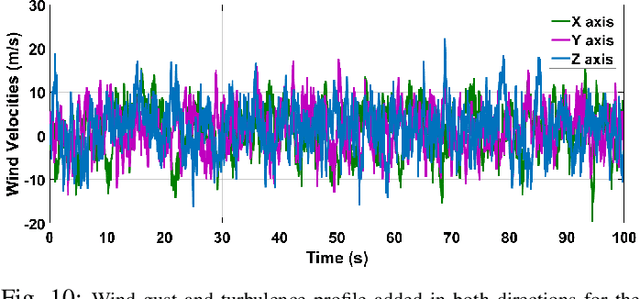
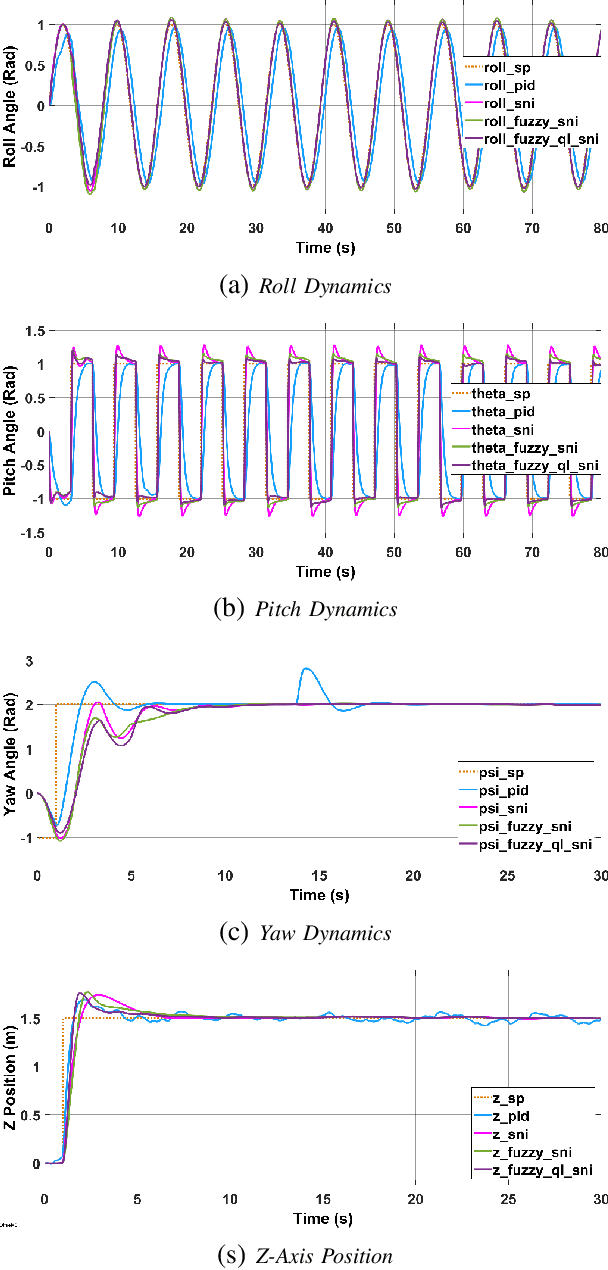
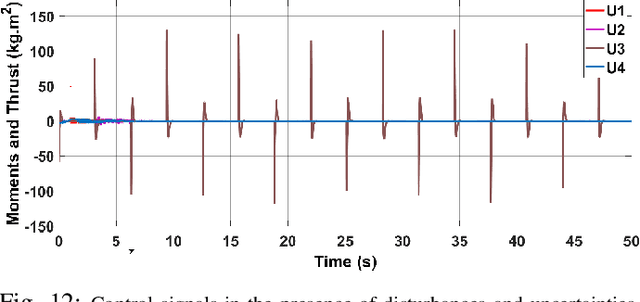
Quadrotors are one of the popular unmanned aerial vehicles (UAVs) due to their versatility and simple design. However, the tuning of gains for quadrotor flight controllers can be laborious, and accurately stable control of trajectories can be difficult to maintain under exogenous disturbances and uncertain system parameters. This paper introduces a novel robust and adaptive control synthesis methodology for a quadrotor robot's attitude and altitude stabilization. The developed method is based on the fuzzy reinforcement learning and Strictly Negative Imaginary (SNI) property. The first stage of our control approach is to transform a nonlinear quadrotor system into an equivalent Negative-Imaginary (NI) linear model by means of the feedback linearization (FL) technique. The second phase is to design a control scheme that adapts online the Strictly Negative Imaginary (SNI) controller gains via fuzzy Q-learning, inspired by biological learning. The proposed controller does not require any prior training. The performance of the designed controller is compared with that of a fixed-gain SNI controller, a fuzzy-SNI controller, and a conventional PID controller in a series of numerical simulations. Furthermore, the stability of the proposed controller and the adaptive laws are proofed using the NI theorem.
Robust Multi-Robot Coverage of Unknown Environments using a Distributed Robot Swarm
Nov 29, 2021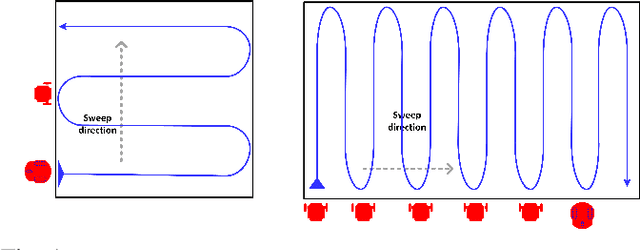
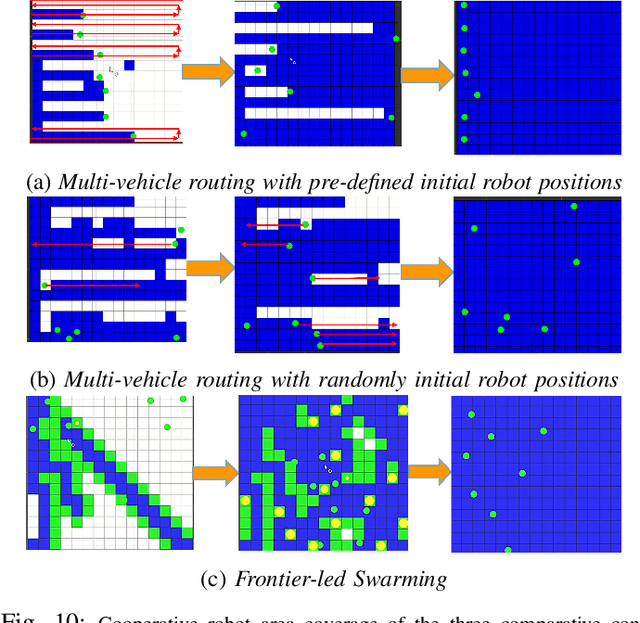
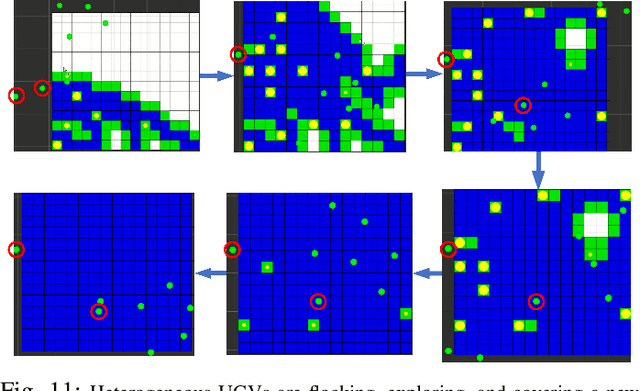

In mobile robotics, area exploration and coverage are critical capabilities. In most of the available research, a common assumption is global, long-range communication and centralised cooperation. This paper proposes a novel swarm-based coverage control algorithm that relaxes these assumptions. The algorithm combines two elements: swarm rules and frontier search algorithms. Inspired by natural systems in which large numbers of simple agents (e.g., schooling fish, flocking birds, swarming insects) perform complicated collective behaviors, the first element uses three simple rules to maintain a swarm formation in a distributed manner. The second element provides means to select promising regions to explore (and cover) using the minimization of a cost function involving the agent's relative position to the frontier cells and the frontier's size. We tested our approach's performance on both heterogeneous and homogeneous groups of mobile robots in different environments. We measure both coverage performance and swarm formation statistics that permit the group to maintain communication. Through a series of comparison experiments, we demonstrate the proposed strategy has superior performance over recently presented map coverage methodologies and the conventional artificial potential field based on a percentage of cell-coverage, turnaround, and safe paths while maintaining a formation that permits short-range communication.
MobileXNet: An Efficient Convolutional Neural Network for Monocular Depth Estimation
Nov 24, 2021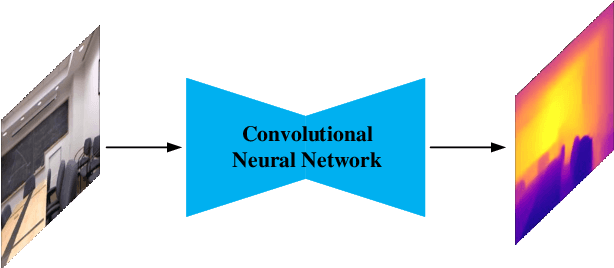
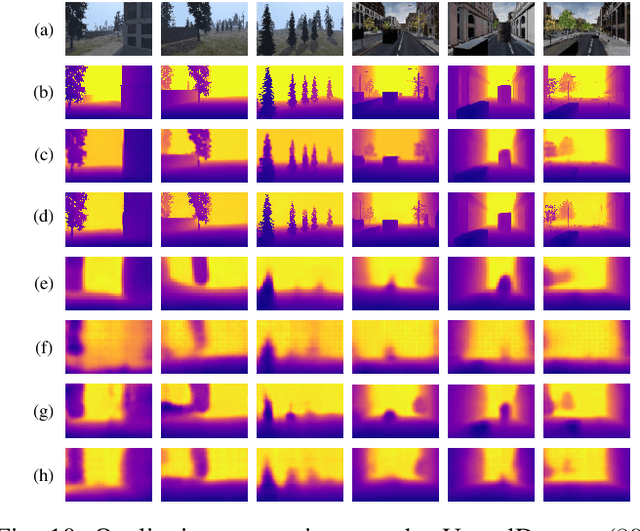
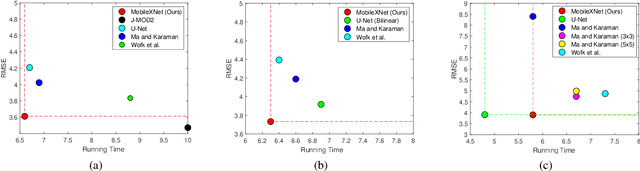
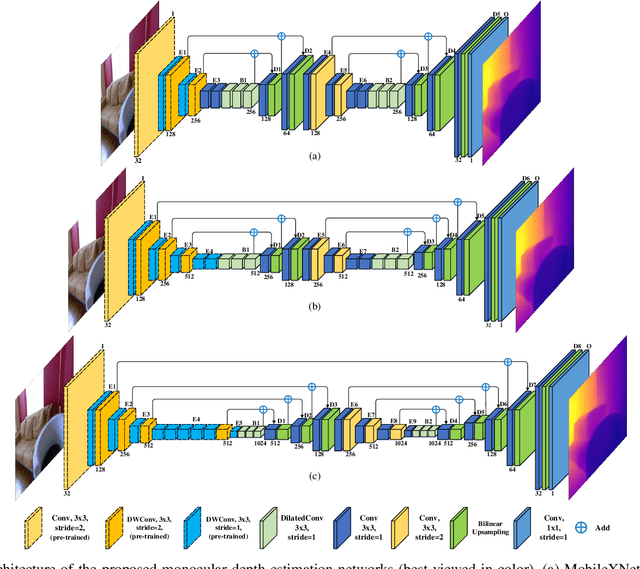
Depth is a vital piece of information for autonomous vehicles to perceive obstacles. Due to the relatively low price and small size of monocular cameras, depth estimation from a single RGB image has attracted great interest in the research community. In recent years, the application of Deep Neural Networks (DNNs) has significantly boosted the accuracy of monocular depth estimation (MDE). State-of-the-art methods are usually designed on top of complex and extremely deep network architectures, which require more computational resources and cannot run in real-time without using high-end GPUs. Although some researchers tried to accelerate the running speed, the accuracy of depth estimation is degraded because the compressed model does not represent images well. In addition, the inherent characteristic of the feature extractor used by the existing approaches results in severe spatial information loss in the produced feature maps, which also impairs the accuracy of depth estimation on small sized images. In this study, we are motivated to design a novel and efficient Convolutional Neural Network (CNN) that assembles two shallow encoder-decoder style subnetworks in succession to address these problems. In particular, we place our emphasis on the trade-off between the accuracy and speed of MDE. Extensive experiments have been conducted on the NYU depth v2, KITTI, Make3D and Unreal data sets. Compared with the state-of-the-art approaches which have an extremely deep and complex architecture, the proposed network not only achieves comparable performance but also runs at a much faster speed on a single, less powerful GPU.
Towards Real-Time Monocular Depth Estimation for Robotics: A Survey
Nov 16, 2021
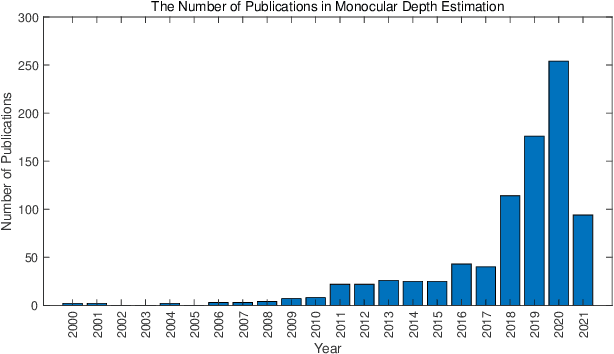


As an essential component for many autonomous driving and robotic activities such as ego-motion estimation, obstacle avoidance and scene understanding, monocular depth estimation (MDE) has attracted great attention from the computer vision and robotics communities. Over the past decades, a large number of methods have been developed. To the best of our knowledge, however, there is not a comprehensive survey of MDE. This paper aims to bridge this gap by reviewing 197 relevant articles published between 1970 and 2021. In particular, we provide a comprehensive survey of MDE covering various methods, introduce the popular performance evaluation metrics and summarize publically available datasets. We also summarize available open-source implementations of some representative methods and compare their performances. Furthermore, we review the application of MDE in some important robotic tasks. Finally, we conclude this paper by presenting some promising directions for future research. This survey is expected to assist readers to navigate this research field.
Multi-Fake Evolutionary Generative Adversarial Networks for Imbalance Hyperspectral Image Classification
Nov 07, 2021
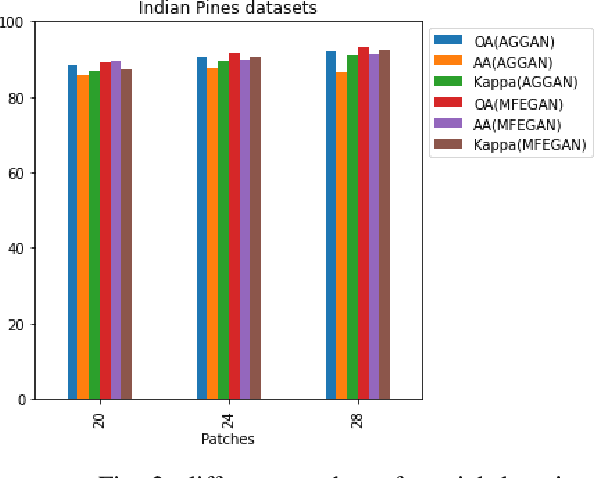
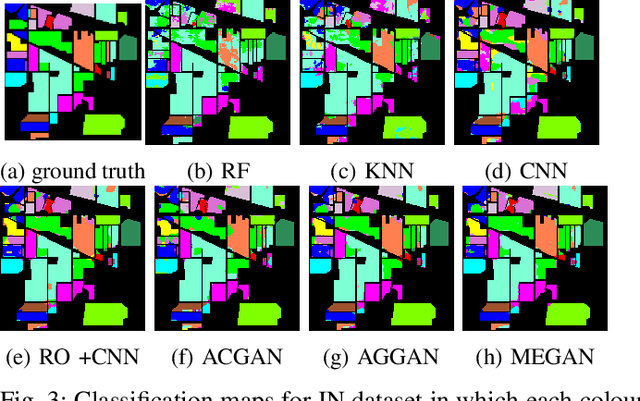
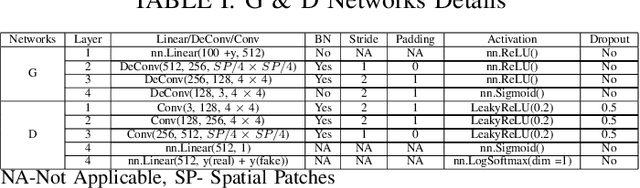
This paper presents a novel multi-fake evolutionary generative adversarial network(MFEGAN) for handling imbalance hyperspectral image classification. It is an end-to-end approach in which different generative objective losses are considered in the generator network to improve the classification performance of the discriminator network. Thus, the same discriminator network has been used as a standard classifier by embedding the classifier network on top of the discriminating function. The effectiveness of the proposed method has been validated through two hyperspectral spatial-spectral data sets. The same generative and discriminator architectures have been utilized with two different GAN objectives for a fair performance comparison with the proposed method. It is observed from the experimental validations that the proposed method outperforms the state-of-the-art methods with better classification performance.
Does Adversarial Oversampling Help us?
Aug 20, 2021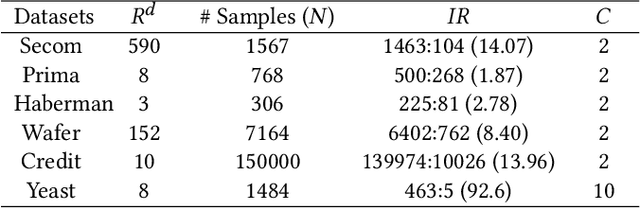
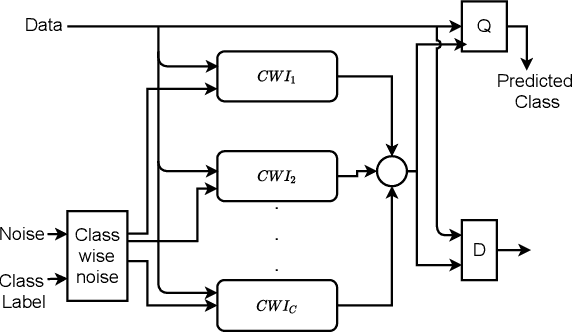

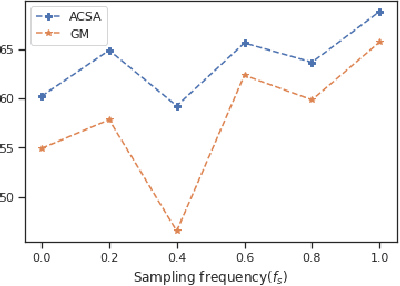
Traditional oversampling methods are generally employed to handle class imbalance in datasets. This oversampling approach is independent of the classifier; thus, it does not offer an end-to-end solution. To overcome this, we propose a three-player adversarial game-based end-to-end method, where a domain-constraints mixture of generators, a discriminator, and a multi-class classifier are used. Rather than adversarial minority oversampling, we propose an adversarial oversampling (AO) and a data-space oversampling (DO) approach. In AO, the generator updates by fooling both the classifier and discriminator, however, in DO, it updates by favoring the classifier and fooling the discriminator. While updating the classifier, it considers both the real and synthetically generated samples in AO. But, in DO, it favors the real samples and fools the subset class-specific generated samples. To mitigate the biases of a classifier towards the majority class, minority samples are over-sampled at a fractional rate. Such implementation is shown to provide more robust classification boundaries. The effectiveness of our proposed method has been validated with high-dimensional, highly imbalanced and large-scale multi-class tabular datasets. The results as measured by average class specific accuracy (ACSA) clearly indicate that the proposed method provides better classification accuracy (improvement in the range of 0.7% to 49.27%) as compared to the baseline classifier.