 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplications of Computer Vision in Autonomous Vehicles: Methods, Challenges and Future Directions
Nov 16, 2023Autonomous vehicle refers to a vehicle capable of perceiving its surrounding environment and driving with little or no human driver input. The perception system is a fundamental component which enables the autonomous vehicle to collect data and extract relevant information from the environment to drive safely. Benefit from the recent advances in computer vision, the perception task can be achieved by using sensors, such as camera, LiDAR, radar, and ultrasonic sensor. This paper reviews publications on computer vision and autonomous driving that are published during the last ten years. In particular, we first investigate the development of autonomous driving systems and summarize these systems that are developed by the major automotive manufacturers from different countries. Second, we investigate the sensors and benchmark data sets that are commonly utilized for autonomous driving. Then, a comprehensive overview of computer vision applications for autonomous driving such as depth estimation, object detection, lane detection, and traffic sign recognition are discussed. Additionally, we review public opinions and concerns on autonomous vehicles. Based on the discussion, we analyze the current technological challenges that autonomous vehicles meet with. Finally, we present our insights and point out some promising directions for future research. This paper will help the reader to understand autonomous vehicles from the perspectives of academia and industry.
Lightweight Monocular Depth Estimation with an Edge Guided Network
Sep 29, 2022
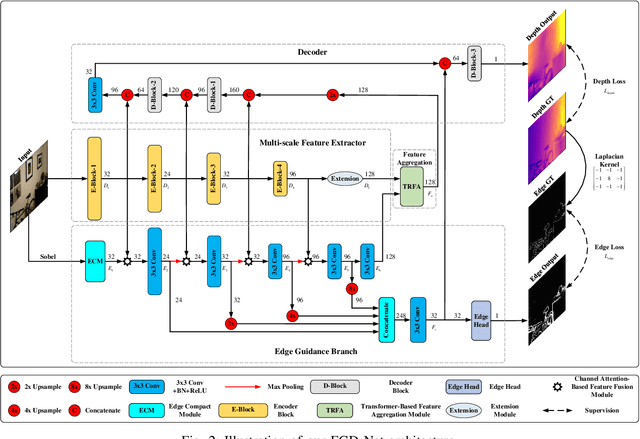
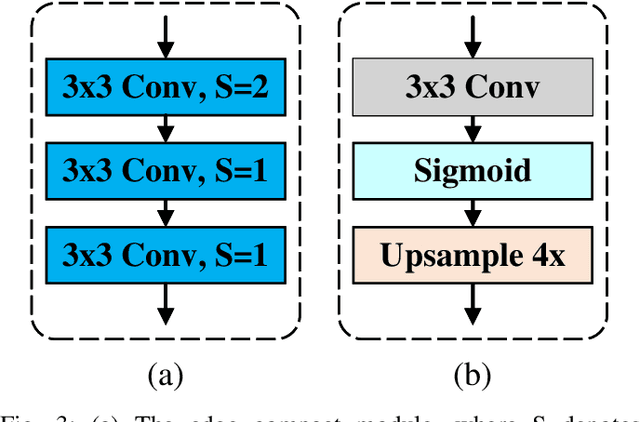
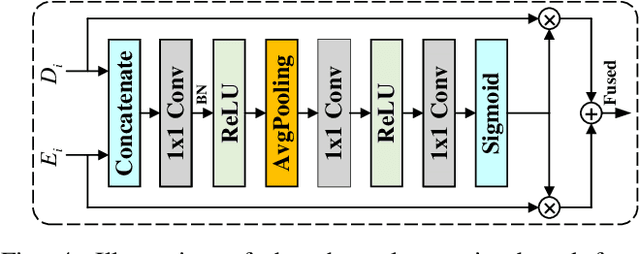
Monocular depth estimation is an important task that can be applied to many robotic applications. Existing methods focus on improving depth estimation accuracy via training increasingly deeper and wider networks, however these suffer from large computational complexity. Recent studies found that edge information are important cues for convolutional neural networks (CNNs) to estimate depth. Inspired by the above observations, we present a novel lightweight Edge Guided Depth Estimation Network (EGD-Net) in this study. In particular, we start out with a lightweight encoder-decoder architecture and embed an edge guidance branch which takes as input image gradients and multi-scale feature maps from the backbone to learn the edge attention features. In order to aggregate the context information and edge attention features, we design a transformer-based feature aggregation module (TRFA). TRFA captures the long-range dependencies between the context information and edge attention features through cross-attention mechanism. We perform extensive experiments on the NYU depth v2 dataset. Experimental results show that the proposed method runs about 96 fps on a Nvidia GTX 1080 GPU whilst achieving the state-of-the-art performance in terms of accuracy.
MobileXNet: An Efficient Convolutional Neural Network for Monocular Depth Estimation
Nov 24, 2021
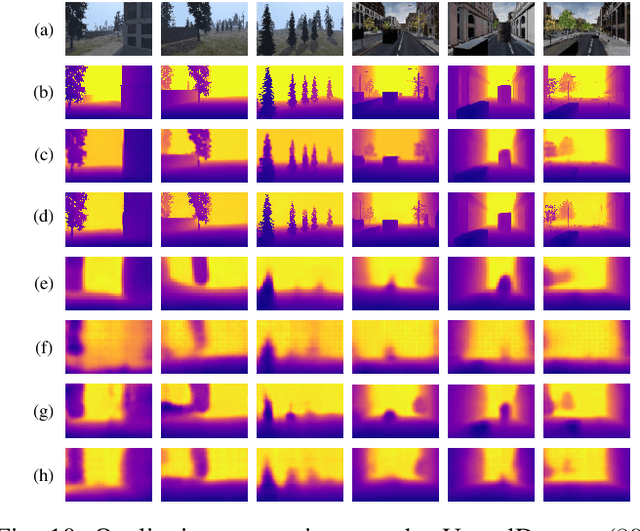
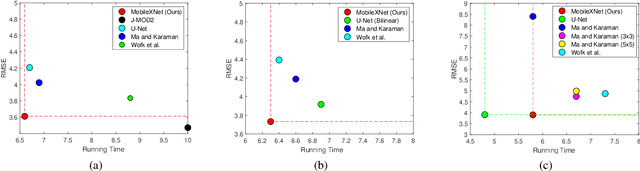
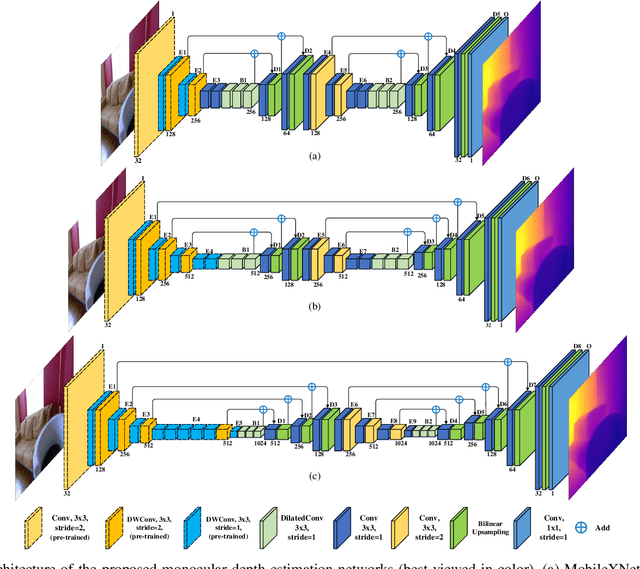
Depth is a vital piece of information for autonomous vehicles to perceive obstacles. Due to the relatively low price and small size of monocular cameras, depth estimation from a single RGB image has attracted great interest in the research community. In recent years, the application of Deep Neural Networks (DNNs) has significantly boosted the accuracy of monocular depth estimation (MDE). State-of-the-art methods are usually designed on top of complex and extremely deep network architectures, which require more computational resources and cannot run in real-time without using high-end GPUs. Although some researchers tried to accelerate the running speed, the accuracy of depth estimation is degraded because the compressed model does not represent images well. In addition, the inherent characteristic of the feature extractor used by the existing approaches results in severe spatial information loss in the produced feature maps, which also impairs the accuracy of depth estimation on small sized images. In this study, we are motivated to design a novel and efficient Convolutional Neural Network (CNN) that assembles two shallow encoder-decoder style subnetworks in succession to address these problems. In particular, we place our emphasis on the trade-off between the accuracy and speed of MDE. Extensive experiments have been conducted on the NYU depth v2, KITTI, Make3D and Unreal data sets. Compared with the state-of-the-art approaches which have an extremely deep and complex architecture, the proposed network not only achieves comparable performance but also runs at a much faster speed on a single, less powerful GPU.
Towards Real-Time Monocular Depth Estimation for Robotics: A Survey
Nov 16, 2021
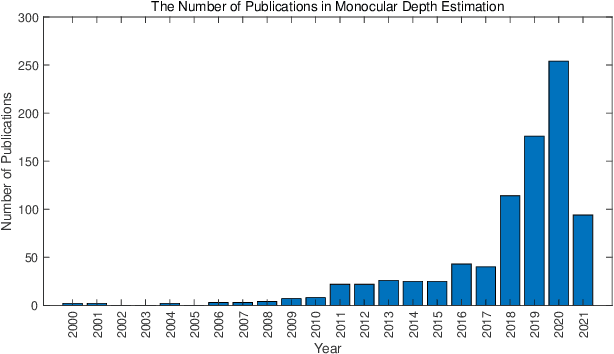


As an essential component for many autonomous driving and robotic activities such as ego-motion estimation, obstacle avoidance and scene understanding, monocular depth estimation (MDE) has attracted great attention from the computer vision and robotics communities. Over the past decades, a large number of methods have been developed. To the best of our knowledge, however, there is not a comprehensive survey of MDE. This paper aims to bridge this gap by reviewing 197 relevant articles published between 1970 and 2021. In particular, we provide a comprehensive survey of MDE covering various methods, introduce the popular performance evaluation metrics and summarize publically available datasets. We also summarize available open-source implementations of some representative methods and compare their performances. Furthermore, we review the application of MDE in some important robotic tasks. Finally, we conclude this paper by presenting some promising directions for future research. This survey is expected to assist readers to navigate this research field.