 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileXNet: An Efficient Convolutional Neural Network for Monocular Depth Estimation
Paper and Code
Nov 24, 2021
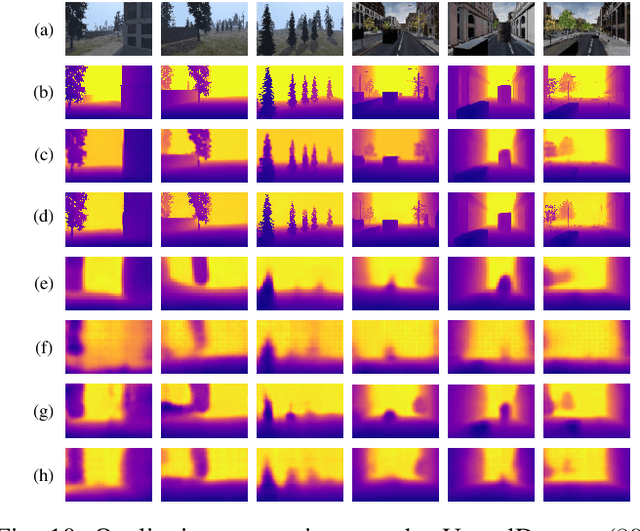
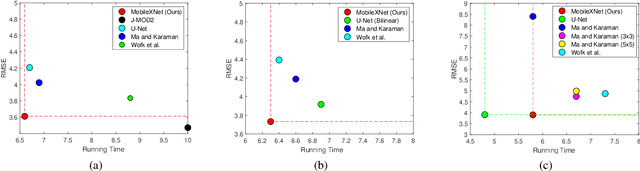
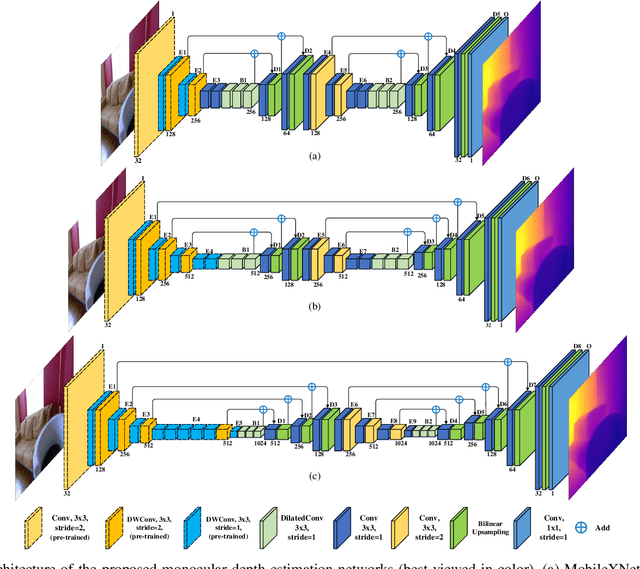
Depth is a vital piece of information for autonomous vehicles to perceive obstacles. Due to the relatively low price and small size of monocular cameras, depth estimation from a single RGB image has attracted great interest in the research community. In recent years, the application of Deep Neural Networks (DNNs) has significantly boosted the accuracy of monocular depth estimation (MDE). State-of-the-art methods are usually designed on top of complex and extremely deep network architectures, which require more computational resources and cannot run in real-time without using high-end GPUs. Although some researchers tried to accelerate the running speed, the accuracy of depth estimation is degraded because the compressed model does not represent images well. In addition, the inherent characteristic of the feature extractor used by the existing approaches results in severe spatial information loss in the produced feature maps, which also impairs the accuracy of depth estimation on small sized images. In this study, we are motivated to design a novel and efficient Convolutional Neural Network (CNN) that assembles two shallow encoder-decoder style subnetworks in succession to address these problems. In particular, we place our emphasis on the trade-off between the accuracy and speed of MDE. Extensive experiments have been conducted on the NYU depth v2, KITTI, Make3D and Unreal data sets. Compared with the state-of-the-art approaches which have an extremely deep and complex architecture, the proposed network not only achieves comparable performance but also runs at a much faster speed on a single, less powerful GPU.