 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Monocular Depth Estimation with an Edge Guided Network
Sep 29, 2022
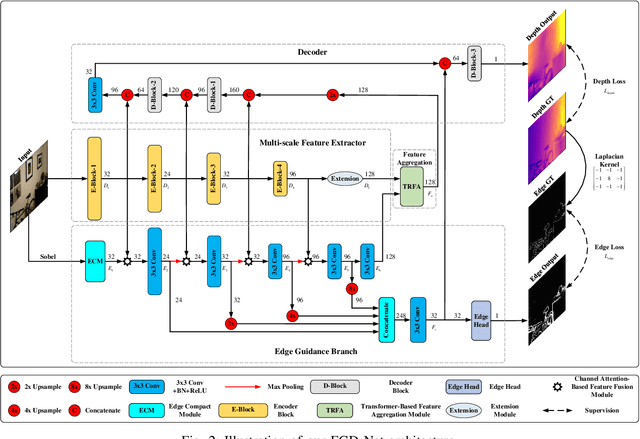
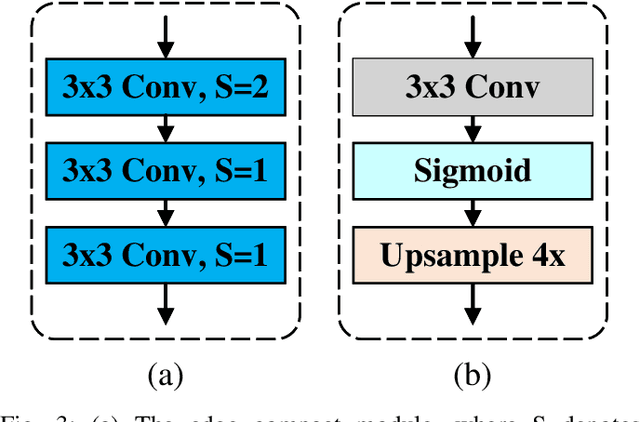
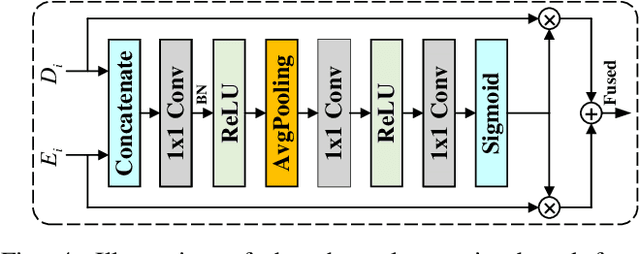
Monocular depth estimation is an important task that can be applied to many robotic applications. Existing methods focus on improving depth estimation accuracy via training increasingly deeper and wider networks, however these suffer from large computational complexity. Recent studies found that edge information are important cues for convolutional neural networks (CNNs) to estimate depth. Inspired by the above observations, we present a novel lightweight Edge Guided Depth Estimation Network (EGD-Net) in this study. In particular, we start out with a lightweight encoder-decoder architecture and embed an edge guidance branch which takes as input image gradients and multi-scale feature maps from the backbone to learn the edge attention features. In order to aggregate the context information and edge attention features, we design a transformer-based feature aggregation module (TRFA). TRFA captures the long-range dependencies between the context information and edge attention features through cross-attention mechanism. We perform extensive experiments on the NYU depth v2 dataset. Experimental results show that the proposed method runs about 96 fps on a Nvidia GTX 1080 GPU whilst achieving the state-of-the-art performance in terms of accuracy.
Latent Preserving Generative Adversarial Network for Imbalance classification
Sep 04, 2022
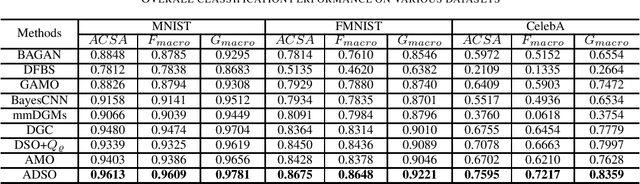
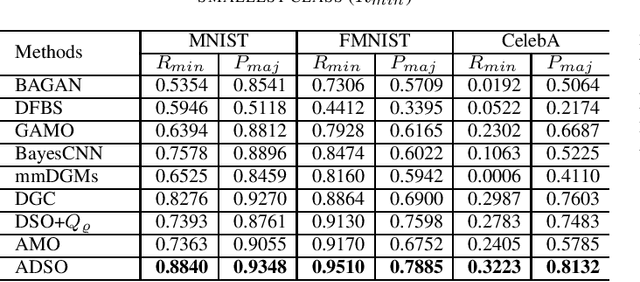
Many real-world classification problems have imbalanced frequency of class labels; a well-known issue known as the "class imbalance" problem. Classic classification algorithms tend to be biased towards the majority class, leaving the classifier vulnerable to misclassification of the minority class. While the literature is rich with methods to fix this problem, as the dimensionality of the problem increases, many of these methods do not scale-up and the cost of running them become prohibitive. In this paper, we present an end-to-end deep generative classifier. We propose a domain-constraint autoencoder to preserve the latent-space as prior for a generator, which is then used to play an adversarial game with two other deep networks, a discriminator and a classifier. Extensive experiments are carried out on three different multi-class imbalanced problems and a comparison with state-of-the-art methods. Experimental results confirmed the superiority of our method over popular algorithms in handling high-dimensional imbalanced classification problems. Our code is available on https://github.com/TanmDL/SLPPL-GAN.
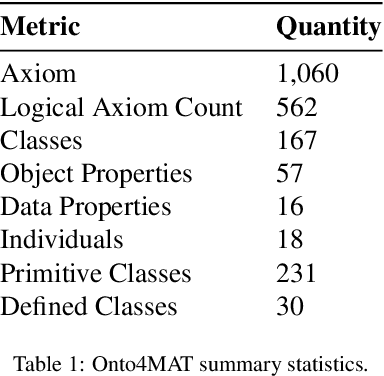
Onto4MAT: A Swarm Shepherding Ontology for Generalised Multi-Agent Teaming
Mar 24, 2022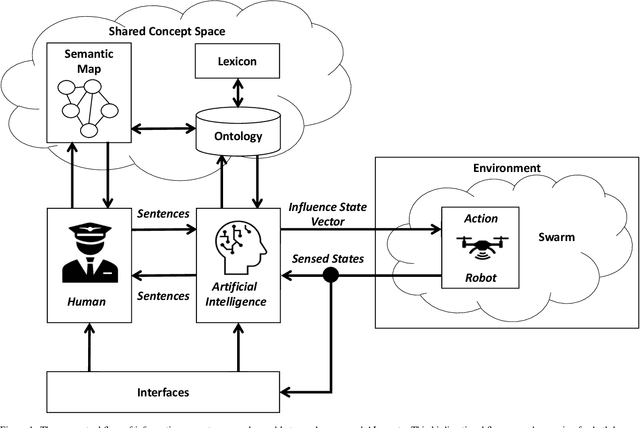
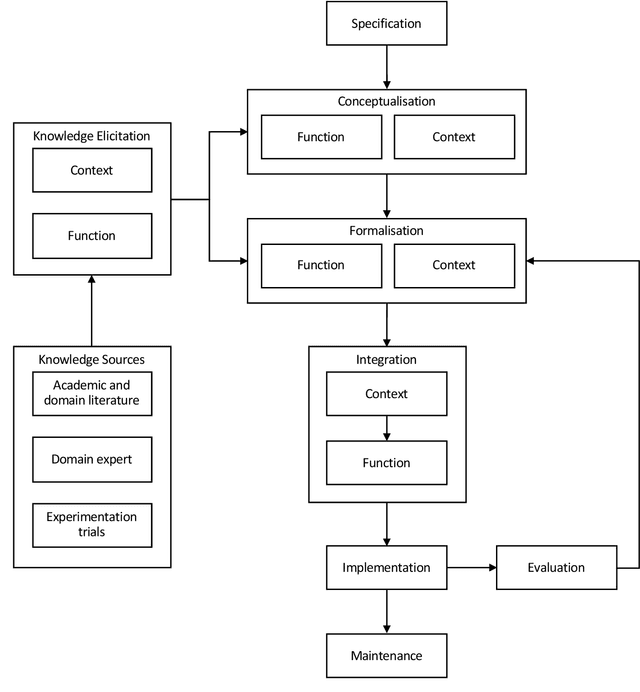
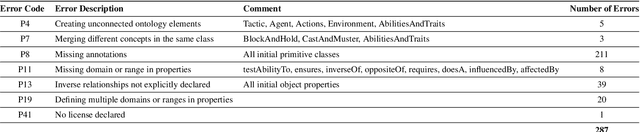
Research in multi-agent teaming has increased substantially over recent years, with knowledge-based systems to support teaming processes typically focused on delivering functional (communicative) solutions for a team to act meaningfully in response to direction. Enabling humans to effectively interact and team with a swarm of autonomous cognitive agents is an open research challenge in Human-Swarm Teaming research, partially due to the focus on developing the enabling architectures to support these systems. Typically, bi-directional transparency and shared semantic understanding between agents has not prioritised a designed mechanism in Human-Swarm Teaming, potentially limiting how a human and a swarm team can share understanding and information\textemdash data through concepts and contexts\textemdash to achieve a goal. To address this, we provide a formal knowledge representation design that enables the swarm Artificial Intelligence to reason about its environment and system, ultimately achieving a shared goal. We propose the Ontology for Generalised Multi-Agent Teaming, Onto4MAT, to enable more effective teaming between humans and teams through the biologically-inspired approach of shepherding.
MobileXNet: An Efficient Convolutional Neural Network for Monocular Depth Estimation
Nov 24, 2021
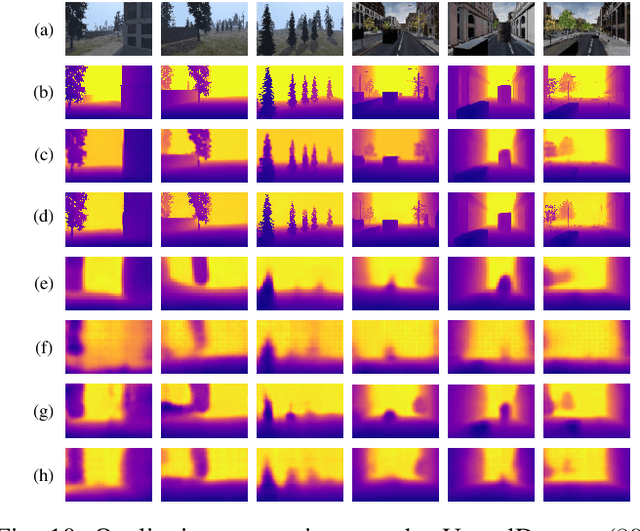
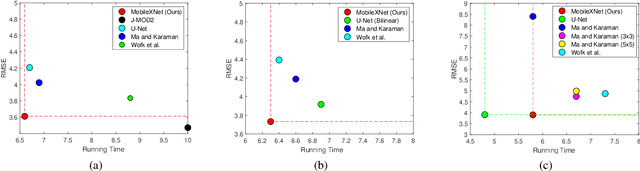
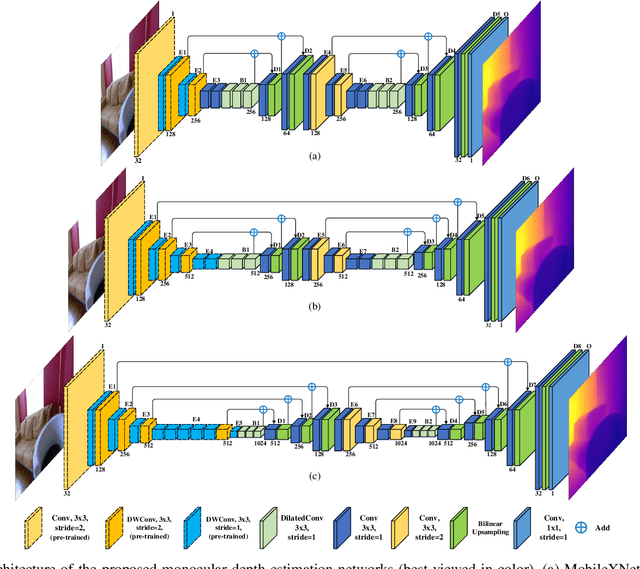
Depth is a vital piece of information for autonomous vehicles to perceive obstacles. Due to the relatively low price and small size of monocular cameras, depth estimation from a single RGB image has attracted great interest in the research community. In recent years, the application of Deep Neural Networks (DNNs) has significantly boosted the accuracy of monocular depth estimation (MDE). State-of-the-art methods are usually designed on top of complex and extremely deep network architectures, which require more computational resources and cannot run in real-time without using high-end GPUs. Although some researchers tried to accelerate the running speed, the accuracy of depth estimation is degraded because the compressed model does not represent images well. In addition, the inherent characteristic of the feature extractor used by the existing approaches results in severe spatial information loss in the produced feature maps, which also impairs the accuracy of depth estimation on small sized images. In this study, we are motivated to design a novel and efficient Convolutional Neural Network (CNN) that assembles two shallow encoder-decoder style subnetworks in succession to address these problems. In particular, we place our emphasis on the trade-off between the accuracy and speed of MDE. Extensive experiments have been conducted on the NYU depth v2, KITTI, Make3D and Unreal data sets. Compared with the state-of-the-art approaches which have an extremely deep and complex architecture, the proposed network not only achieves comparable performance but also runs at a much faster speed on a single, less powerful GPU.
Towards Real-Time Monocular Depth Estimation for Robotics: A Survey
Nov 16, 2021
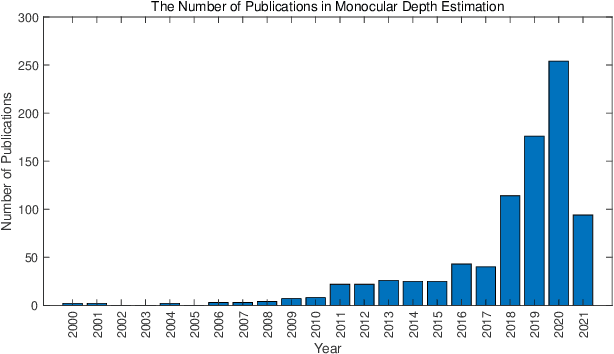


As an essential component for many autonomous driving and robotic activities such as ego-motion estimation, obstacle avoidance and scene understanding, monocular depth estimation (MDE) has attracted great attention from the computer vision and robotics communities. Over the past decades, a large number of methods have been developed. To the best of our knowledge, however, there is not a comprehensive survey of MDE. This paper aims to bridge this gap by reviewing 197 relevant articles published between 1970 and 2021. In particular, we provide a comprehensive survey of MDE covering various methods, introduce the popular performance evaluation metrics and summarize publically available datasets. We also summarize available open-source implementations of some representative methods and compare their performances. Furthermore, we review the application of MDE in some important robotic tasks. Finally, we conclude this paper by presenting some promising directions for future research. This survey is expected to assist readers to navigate this research field.
Multi-Fake Evolutionary Generative Adversarial Networks for Imbalance Hyperspectral Image Classification
Nov 07, 2021
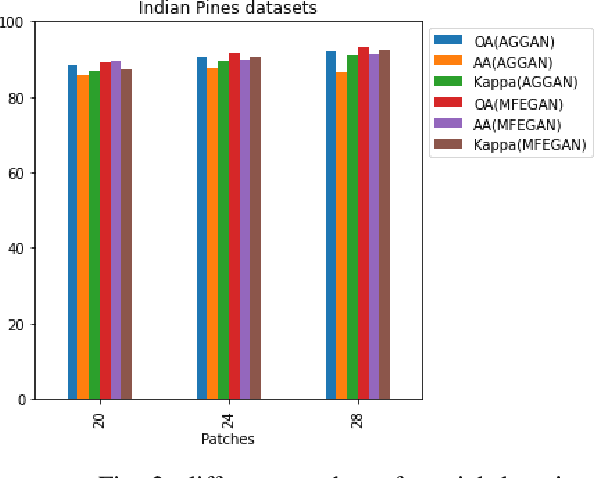
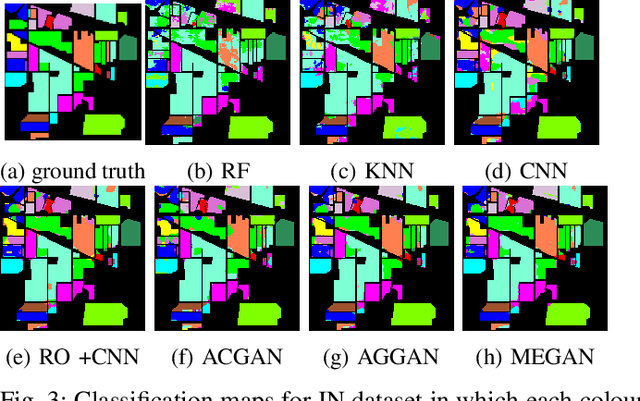
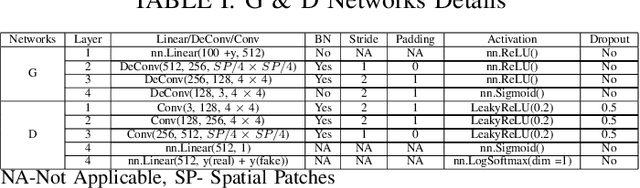
This paper presents a novel multi-fake evolutionary generative adversarial network(MFEGAN) for handling imbalance hyperspectral image classification. It is an end-to-end approach in which different generative objective losses are considered in the generator network to improve the classification performance of the discriminator network. Thus, the same discriminator network has been used as a standard classifier by embedding the classifier network on top of the discriminating function. The effectiveness of the proposed method has been validated through two hyperspectral spatial-spectral data sets. The same generative and discriminator architectures have been utilized with two different GAN objectives for a fair performance comparison with the proposed method. It is observed from the experimental validations that the proposed method outperforms the state-of-the-art methods with better classification performance.
Does Adversarial Oversampling Help us?
Aug 20, 2021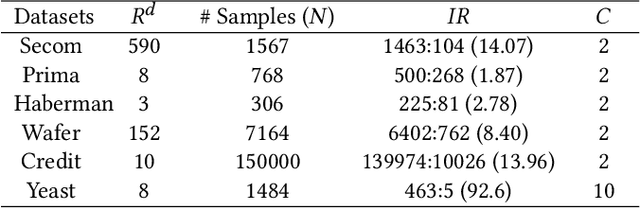
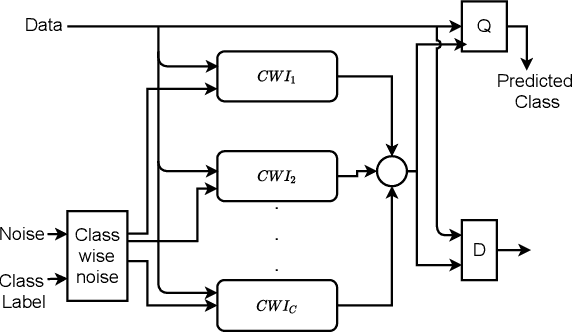

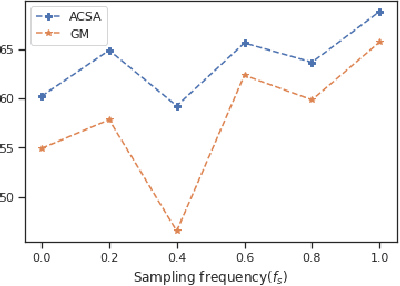
Traditional oversampling methods are generally employed to handle class imbalance in datasets. This oversampling approach is independent of the classifier; thus, it does not offer an end-to-end solution. To overcome this, we propose a three-player adversarial game-based end-to-end method, where a domain-constraints mixture of generators, a discriminator, and a multi-class classifier are used. Rather than adversarial minority oversampling, we propose an adversarial oversampling (AO) and a data-space oversampling (DO) approach. In AO, the generator updates by fooling both the classifier and discriminator, however, in DO, it updates by favoring the classifier and fooling the discriminator. While updating the classifier, it considers both the real and synthetically generated samples in AO. But, in DO, it favors the real samples and fools the subset class-specific generated samples. To mitigate the biases of a classifier towards the majority class, minority samples are over-sampled at a fractional rate. Such implementation is shown to provide more robust classification boundaries. The effectiveness of our proposed method has been validated with high-dimensional, highly imbalanced and large-scale multi-class tabular datasets. The results as measured by average class specific accuracy (ACSA) clearly indicate that the proposed method provides better classification accuracy (improvement in the range of 0.7% to 49.27%) as compared to the baseline classifier.
Improving ClusterGAN Using Self-AugmentedInformation Maximization of Disentangling LatentSpaces
Jul 27, 2021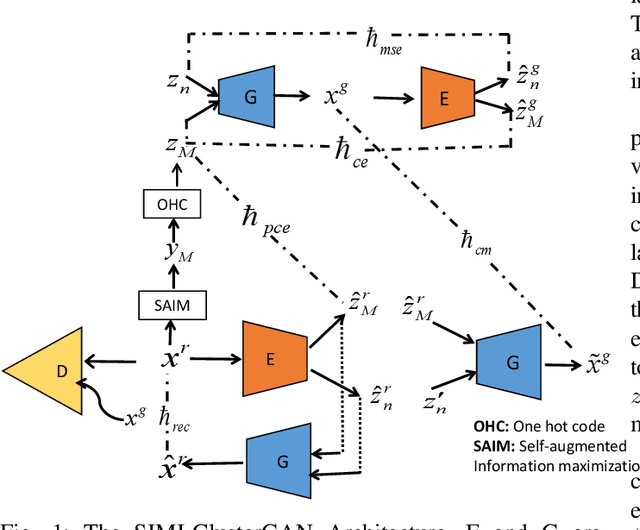



The Latent Space Clustering in Generative adversarial networks (ClusterGAN) method has been successful with high-dimensional data. However, the method assumes uniformlydistributed priors during the generation of modes, which isa restrictive assumption in real-world data and cause loss ofdiversity in the generated modes. In this paper, we proposeself-augmentation information maximization improved Clus-terGAN (SIMI-ClusterGAN) to learn the distinctive priorsfrom the data. The proposed SIMI-ClusterGAN consists offour deep neural networks: self-augmentation prior network,generator, discriminator and clustering inference autoencoder.The proposed method has been validated using seven bench-mark data sets and has shown improved performance overstate-of-the art methods. To demonstrate the superiority ofSIMI-ClusterGAN performance on imbalanced dataset, wehave discussed two imbalanced conditions on MNIST datasetswith one-class imbalance and three classes imbalanced cases.The results highlight the advantages of SIMI-ClusterGAN.
Q-Learning with Differential Entropy of Q-Tables
Jun 26, 2020

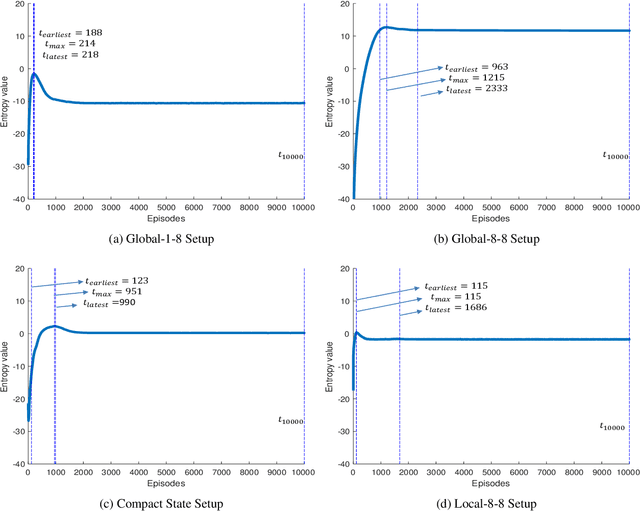
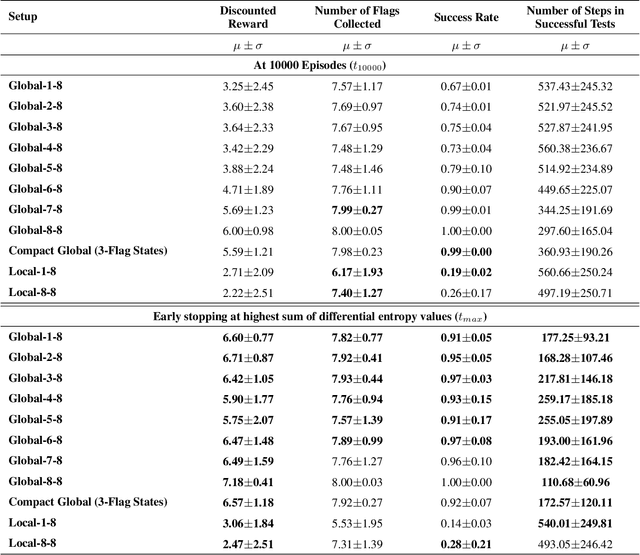
It is well-known that information loss can occur in the classic and simple Q-learning algorithm. Entropy-based policy search methods were introduced to replace Q-learning and to design algorithms that are more robust against information loss. We conjecture that the reduction in performance during prolonged training sessions of Q-learning is caused by a loss of information, which is non-transparent when only examining the cumulative reward without changing the Q-learning algorithm itself. We introduce Differential Entropy of Q-tables (DE-QT) as an external information loss detector to the Q-learning algorithm. The behaviour of DE-QT over training episodes is analyzed to find an appropriate stopping criterion during training. The results reveal that DE-QT can detect the most appropriate stopping point, where a balance between a high success rate and a high efficiency is met for classic Q-Learning algorithm.
Continuous Deep Hierarchical Reinforcement Learning for Ground-Air Swarm Shepherding
Apr 27, 2020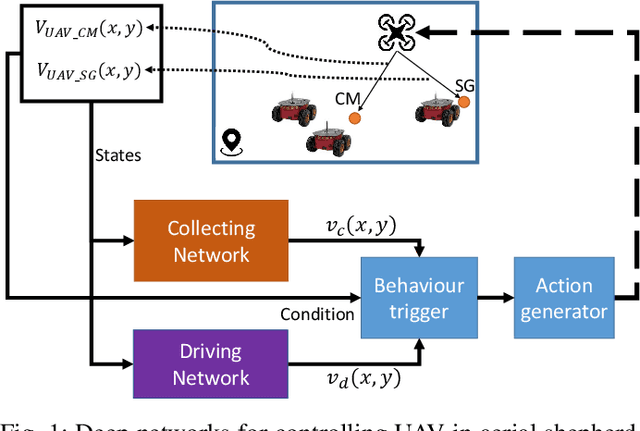
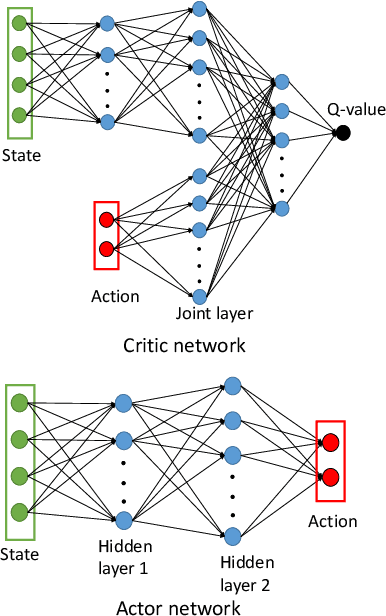


The control and guidance of multi-robots (swarm) is a non-trivial problem due to the complexity inherent in the coupled interaction among the group. Whether the swarm is cooperative or non cooperative, lessons could be learnt from sheepdogs herding sheep. Biomimicry of shepherding offers computational methods for swarm control with the potential to generalize and scale in different environments. However, learning to shepherd is complex due to the large search space that a machine learner is faced with. We present a deep hierarchical reinforcement learning approach for shepherding, whereby an unmanned aerial vehicle (UAV) learns to act as an Aerial sheepdog to control and guide a swarm of unmanned ground vehicles (UGVs). The approach extends our previous work on machine education to decompose the search space into hierarchically organized curriculum. Each lesson in the curriculum is learnt by a deep reinforcement learning model. The hierarchy is formed by fusing the outputs of the model. The approach is demonstrated first in a high-fidelity robotic-operating-system (ROS)-based simulation environment, then with physical UGVs and a UAV in an in-door testing facility. We investigate the ability of the method to generalize as the models move from simulation to the real-world and as the models move from one scale to another.