 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAleph-Alpha-GermanWeb: Improving German-language LLM pre-training with model-based data curation and synthetic data generation
Apr 24, 2025Scaling data quantity is essential for large language models (LLMs), yet recent findings show that data quality can significantly boost performance and training efficiency. We introduce a German-language dataset curation pipeline that combines heuristic and model-based filtering techniques with synthetic data generation. We use our pipeline to create Aleph-Alpha-GermanWeb, a large-scale German pre-training dataset which draws from: (1) Common Crawl web data, (2) FineWeb2, and (3) synthetically-generated data conditioned on actual, organic web data. We evaluate our dataset by pre-training both a 1B Llama-style model and an 8B tokenizer-free hierarchical autoregressive transformer (HAT). A comparison on German-language benchmarks, including MMMLU, shows significant performance gains of Aleph-Alpha-GermanWeb over FineWeb2 alone. This advantage holds at the 8B scale even when FineWeb2 is enriched by human-curated high-quality data sources such as Wikipedia. Our findings support the growing body of evidence that model-based data curation and synthetic data generation can significantly enhance LLM pre-training datasets.
Designing Effective Human-Swarm Interaction Interfaces: Insights from a User Study on Task Performance
Apr 03, 2025In this paper, we present a systematic method of design for human-swarm interaction interfaces, combining theoretical insights with empirical evaluation. We first derive ten design principles from existing literature, apply them to key information dimensions identified through goal-directed task analysis and developed a tablet-based interface for a target search task. We then conducted a user study with 31 participants where humans were required to guide a robotic swarm to a target in the presence of three types of hazards that pose a risk to the robots: Distributed, Moving, and Spreading. Performance was measured based on the proximity of the robots to the target and the number of deactivated robots at the end of the task. Results indicate that at least one robot was bought closer to the target in 98% of tasks, demonstrating the interface's success fulfilling the primary objective of the task. Additionally, in nearly 67% of tasks, more than 50% of the robots reached the target. Moreover, particularly better performance was noted in moving hazards. Additionally, the interface appeared to help minimize robot deactivation, as evidenced by nearly 94% of tasks where participants managed to keep more than 50% of the robots active, ensuring that most of the swarm remained operational. However, its effectiveness varied across hazards, with robot deactivation being lowest in distributed hazard scenarios, suggesting that the interface provided the most support in these conditions.
A Study on Human-Swarm Interaction: A Framework for Assessing Situation Awareness and Task Performance
Mar 19, 2025This paper introduces a framework for human swarm interaction studies that measures situation awareness in dynamic environments. A tablet-based interface was developed for a user study by implementing the concepts introduced in the framework, where operators guided a robotic swarm in a single-target search task, marking hazardous cells unknown to the swarm. Both subjective and objective situation awareness measures were used, with task performance evaluated based on how close the robots were to the target. The framework enabled a structured investigation of the role of situation awareness in human swarm interaction, leading to key findings such as improved task performance across attempts, showing the interface was learnable, centroid active robot position proved to be a useful task performance metric for assessing situation awareness, perception and projection played a key role in task performance, highlighting their importance in interface design and both subjective and objective situation awareness influenced task performance, emphasizing the need for interfaces that support both. These findings validate our framework as a structured approach for integrating situation awareness concepts into human swarm interaction studies, offering a systematic way to assess situation awareness and task performance. The framework can be applied to other swarming studies to evaluate interface learnability, identify meaningful task performance metrics, and refine interface designs to enhance situation awareness, ultimately improving human swarm interaction in dynamic environments.
Continuous Deep Hierarchical Reinforcement Learning for Ground-Air Swarm Shepherding
Apr 27, 2020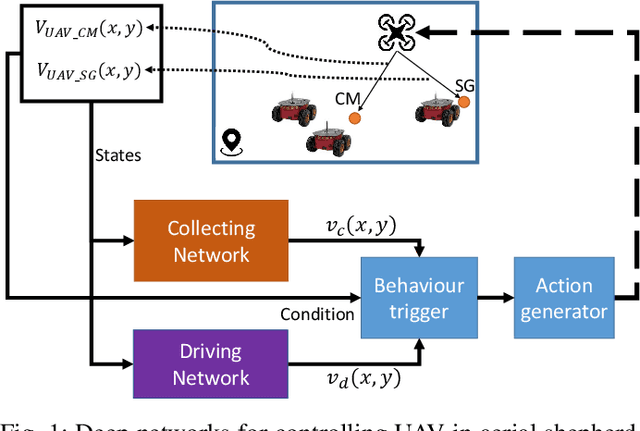
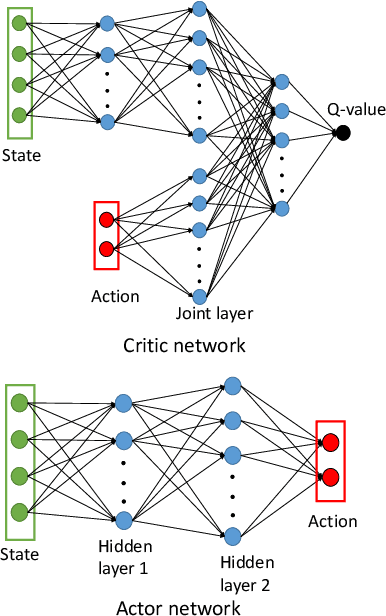


The control and guidance of multi-robots (swarm) is a non-trivial problem due to the complexity inherent in the coupled interaction among the group. Whether the swarm is cooperative or non cooperative, lessons could be learnt from sheepdogs herding sheep. Biomimicry of shepherding offers computational methods for swarm control with the potential to generalize and scale in different environments. However, learning to shepherd is complex due to the large search space that a machine learner is faced with. We present a deep hierarchical reinforcement learning approach for shepherding, whereby an unmanned aerial vehicle (UAV) learns to act as an Aerial sheepdog to control and guide a swarm of unmanned ground vehicles (UGVs). The approach extends our previous work on machine education to decompose the search space into hierarchically organized curriculum. Each lesson in the curriculum is learnt by a deep reinforcement learning model. The hierarchy is formed by fusing the outputs of the model. The approach is demonstrated first in a high-fidelity robotic-operating-system (ROS)-based simulation environment, then with physical UGVs and a UAV in an in-door testing facility. We investigate the ability of the method to generalize as the models move from simulation to the real-world and as the models move from one scale to another.
Apprenticeship Bootstrapping Via Deep Learning with a Safety Net for UAV-UGV Interaction
Oct 10, 2018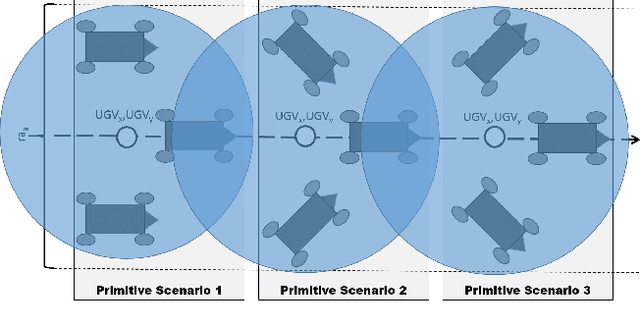

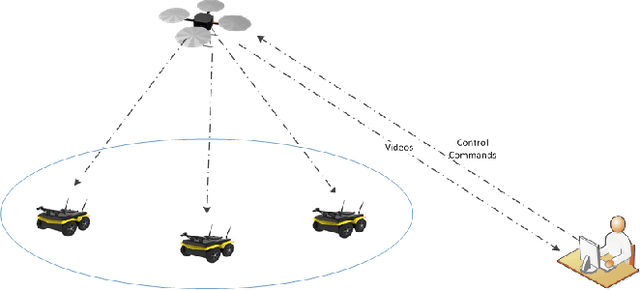

In apprenticeship learning (AL), agents learn by watching or acquiring human demonstrations on some tasks of interest. However, the lack of human demonstrations in novel tasks where they may not be a human expert yet, or when it is too expensive and/or time consuming to acquire human demonstrations motivated a new algorithm: Apprenticeship bootstrapping (ABS). The basic idea is to learn from demonstrations on sub-tasks then autonomously bootstrap a model on the main, more complex, task. The original ABS used inverse reinforcement learning (ABS-IRL). However, the approach is not suitable for continuous action spaces. In this paper, we propose ABS via Deep learning (ABS-DL). It is first validated in a simulation environment on an aerial and ground coordination scenario, where an Unmanned Aerial Vehicle (UAV) is required to maintain three Unmanned Ground Vehicles (UGVs) within a field of view of the UAV 's camera (FoV). Moving a machine learning algorithm from a simulation environment to an actual physical platform is challenging because `mistakes' made by the algorithm while learning could lead to the damage of the platform. We then take this extra step to test the algorithm in a physical environment. We propose a safety-net as a protection layer to ensure that the autonomy of the algorithm in learning does not compromise the safety of the platform. The tests of ABS-DL in the real environment can guarantee a damage-free, collision avoidance behaviour of autonomous bodies. The results show that performance of the proposed approach is comparable to that of a human, and competitive to the traditional approach using expert demonstrations performed on the composite task. The proposed safety-net approach demonstrates its advantages when it enables the UAV to operate more safely under the control of the ABS-DL algorithm.