 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Learning with Differential Entropy of Q-Tables
Jun 26, 2020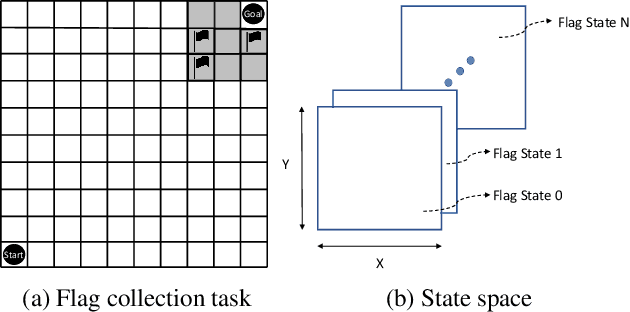

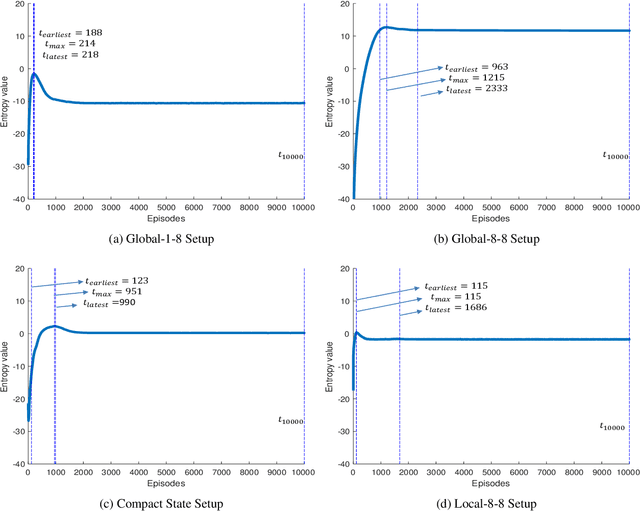
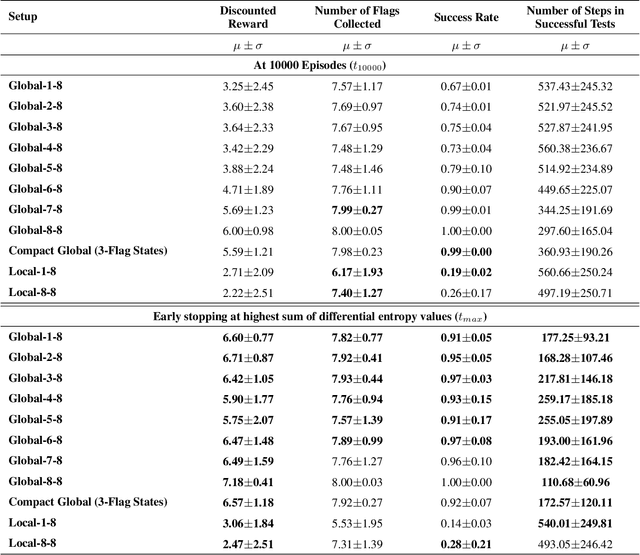
It is well-known that information loss can occur in the classic and simple Q-learning algorithm. Entropy-based policy search methods were introduced to replace Q-learning and to design algorithms that are more robust against information loss. We conjecture that the reduction in performance during prolonged training sessions of Q-learning is caused by a loss of information, which is non-transparent when only examining the cumulative reward without changing the Q-learning algorithm itself. We introduce Differential Entropy of Q-tables (DE-QT) as an external information loss detector to the Q-learning algorithm. The behaviour of DE-QT over training episodes is analyzed to find an appropriate stopping criterion during training. The results reveal that DE-QT can detect the most appropriate stopping point, where a balance between a high success rate and a high efficiency is met for classic Q-Learning algorithm.
Towards Interpretable Deep Neural Networks: An Exact Transformation to Multi-Class Multivariate Decision Trees
Mar 11, 2020
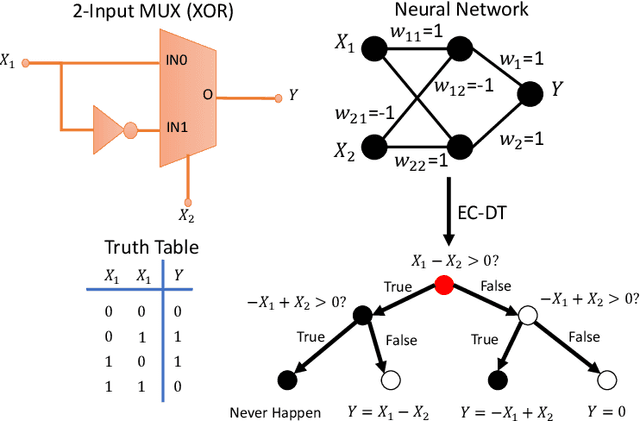

Deep neural networks (DNNs) are commonly labelled as black-boxes lacking interpretability; thus, hindering human's understanding of DNNs' behaviors. A need exists to generate a meaningful sequential logic for the production of a specific output. Decision trees exhibit better interpretability and expressive power due to their representation language and the existence of efficient algorithms to generate rules. Growing a decision tree based on the available data could produce larger than necessary trees or trees that do not generalise well. In this paper, we introduce two novel multivariate decision tree (MDT) algorithms for rule extraction from a DNN: an Exact-Convertible Decision Tree (EC-DT) and a Deep C-Net algorithm to transform a neural network with Rectified Linear Unit activation functions into a representative tree which can be used to extract multivariate rules for reasoning. While the EC-DT translates the DNN in a layer-wise manner to represent exactly the decision boundaries implicitly learned by the hidden layers of the network, the Deep C-Net inherits the decompositional approach from EC-DT and combines with a C5 tree learning algorithm to construct the decision rules. The results suggest that while EC-DT is superior in preserving the structure and the accuracy of DNN, C-Net generates the most compact and highly effective trees from DNN. Both proposed MDT algorithms generate rules including combinations of multiple attributes for precise interpretation of decision-making processes.