 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Mining under Data scarcity
Jun 07, 2024



Multitude of deep learning models have been proposed for node classification in graphs. However, they tend to perform poorly under labeled-data scarcity. Although Few-shot learning for graphs has been introduced to overcome this problem, the existing models are not easily adaptable for generic graph learning frameworks like Graph Neural Networks (GNNs). Our work proposes an Uncertainty Estimator framework that can be applied on top of any generic GNN backbone network (which are typically designed for supervised/semi-supervised node classification) to improve the node classification performance. A neural network is used to model the Uncertainty Estimator as a probability distribution rather than probabilistic discrete scalar values. We train these models under the classic episodic learning paradigm in the $n$-way, $k$-shot fashion, in an end-to-end setting. Our work demonstrates that implementation of the uncertainty estimator on a GNN backbone network improves the classification accuracy under Few-shot setting without any meta-learning specific architecture. We conduct experiments on multiple datasets under different Few-shot settings and different GNN-based backbone networks. Our method outperforms the baselines, which demonstrates the efficacy of the Uncertainty Estimator for Few-shot node classification on graphs with a GNN.
Towards Cross-Domain Continual Learning
Feb 19, 2024



Continual learning is a process that involves training learning agents to sequentially master a stream of tasks or classes without revisiting past data. The challenge lies in leveraging previously acquired knowledge to learn new tasks efficiently, while avoiding catastrophic forgetting. Existing methods primarily focus on single domains, restricting their applicability to specific problems. In this work, we introduce a novel approach called Cross-Domain Continual Learning (CDCL) that addresses the limitations of being limited to single supervised domains. Our method combines inter- and intra-task cross-attention mechanisms within a compact convolutional network. This integration enables the model to maintain alignment with features from previous tasks, thereby delaying the data drift that may occur between tasks, while performing unsupervised cross-domain (UDA) between related domains. By leveraging an intra-task-specific pseudo-labeling method, we ensure accurate input pairs for both labeled and unlabeled samples, enhancing the learning process. To validate our approach, we conduct extensive experiments on public UDA datasets, showcasing its positive performance on cross-domain continual learning challenges. Additionally, our work introduces incremental ideas that contribute to the advancement of this field. We make our code and models available to encourage further exploration and reproduction of our results: \url{https://github.com/Ivsucram/CDCL}
Class-Incremental Learning via Knowledge Amalgamation
Sep 05, 2022

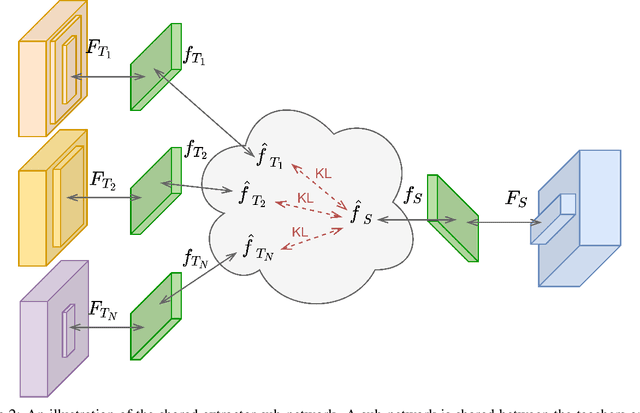
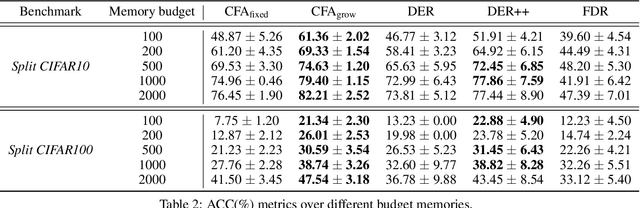
Catastrophic forgetting has been a significant problem hindering the deployment of deep learning algorithms in the continual learning setting. Numerous methods have been proposed to address the catastrophic forgetting problem where an agent loses its generalization power of old tasks while learning new tasks. We put forward an alternative strategy to handle the catastrophic forgetting with knowledge amalgamation (CFA), which learns a student network from multiple heterogeneous teacher models specializing in previous tasks and can be applied to current offline methods. The knowledge amalgamation process is carried out in a single-head manner with only a selected number of memorized samples and no annotations. The teachers and students do not need to share the same network structure, allowing heterogeneous tasks to be adapted to a compact or sparse data representation. We compare our method with competitive baselines from different strategies, demonstrating our approach's advantages.
ACDC: Online Unsupervised Cross-Domain Adaptation
Oct 04, 2021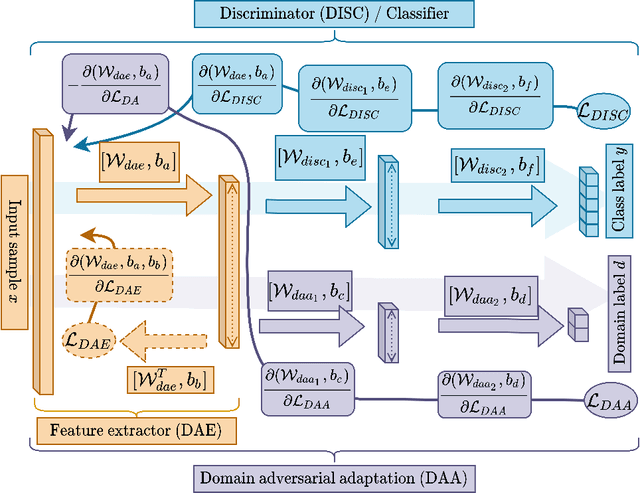
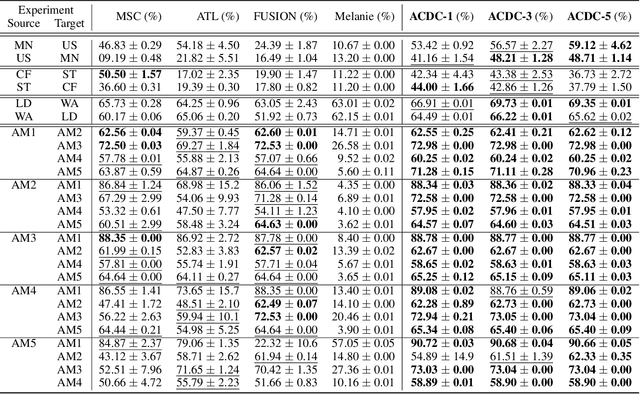
We consider the problem of online unsupervised cross-domain adaptation, where two independent but related data streams with different feature spaces -- a fully labeled source stream and an unlabeled target stream -- are learned together. Unique characteristics and challenges such as covariate shift, asynchronous concept drifts, and contrasting data throughput arises. We propose ACDC, an adversarial unsupervised domain adaptation framework that handles multiple data streams with a complete self-evolving neural network structure that reacts to these defiances. ACDC encapsulates three modules into a single model: A denoising autoencoder that extracts features, an adversarial module that performs domain conversion, and an estimator that learns the source stream and predicts the target stream. ACDC is a flexible and expandable framework with little hyper-parameter tunability. Our experimental results under the prequential test-then-train protocol indicate an improvement in target accuracy over the baseline methods, achieving more than a 10\% increase in some cases.
ATL: Autonomous Knowledge Transfer from Many Streaming Processes
Oct 19, 2019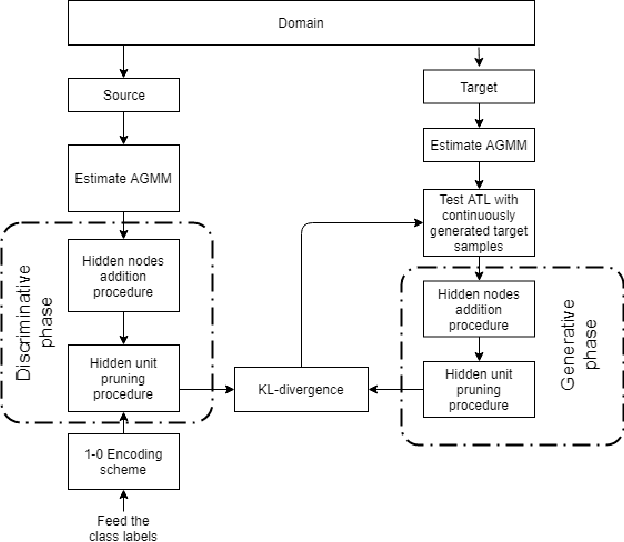
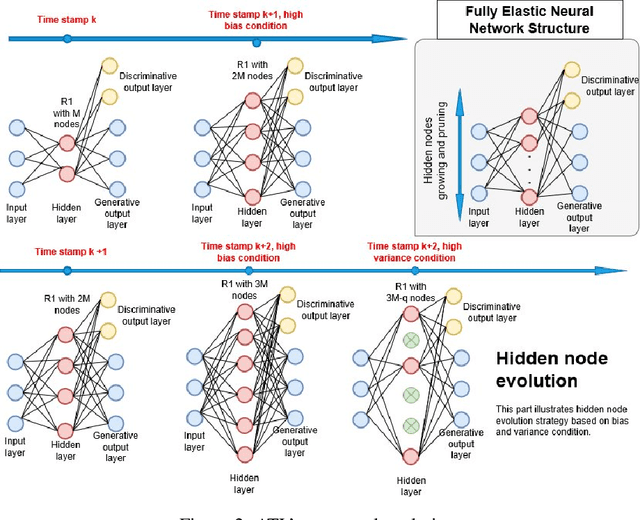
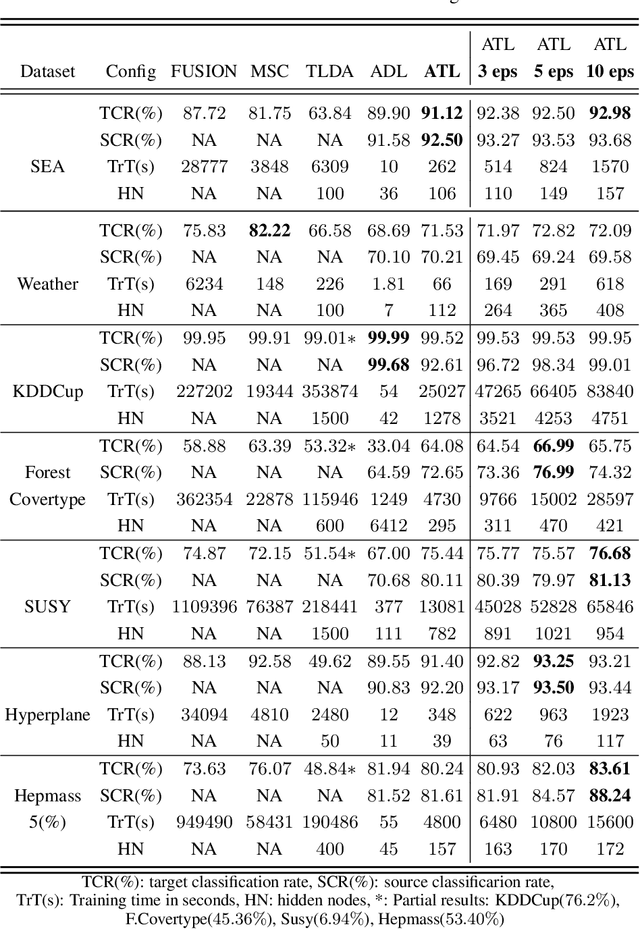
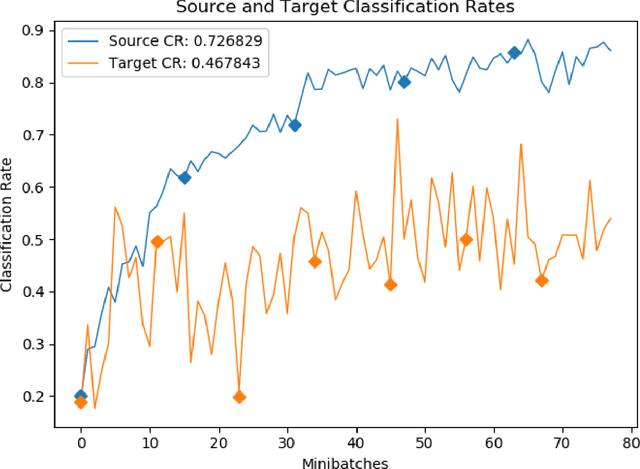
Transferring knowledge across many streaming processes remains an uncharted territory in the existing literature and features unique characteristics: no labelled instance of the target domain, covariate shift of source and target domain, different period of drifts in the source and target domains. Autonomous transfer learning (ATL) is proposed in this paper as a flexible deep learning approach for the online unsupervised transfer learning problem across many streaming processes. ATL offers an online domain adaptation strategy via the generative and discriminative phases coupled with the KL divergence based optimization strategy to produce a domain invariant network while putting forward an elastic network structure. It automatically evolves its network structure from scratch with/without the presence of ground truth to overcome independent concept drifts in the source and target domain. The rigorous numerical evaluation has been conducted along with a comparison against recently published works. ATL demonstrates improved performance while showing significantly faster training speed than its counterparts.