 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Cross-Domain Continual Learning
Feb 19, 2024



Continual learning is a process that involves training learning agents to sequentially master a stream of tasks or classes without revisiting past data. The challenge lies in leveraging previously acquired knowledge to learn new tasks efficiently, while avoiding catastrophic forgetting. Existing methods primarily focus on single domains, restricting their applicability to specific problems. In this work, we introduce a novel approach called Cross-Domain Continual Learning (CDCL) that addresses the limitations of being limited to single supervised domains. Our method combines inter- and intra-task cross-attention mechanisms within a compact convolutional network. This integration enables the model to maintain alignment with features from previous tasks, thereby delaying the data drift that may occur between tasks, while performing unsupervised cross-domain (UDA) between related domains. By leveraging an intra-task-specific pseudo-labeling method, we ensure accurate input pairs for both labeled and unlabeled samples, enhancing the learning process. To validate our approach, we conduct extensive experiments on public UDA datasets, showcasing its positive performance on cross-domain continual learning challenges. Additionally, our work introduces incremental ideas that contribute to the advancement of this field. We make our code and models available to encourage further exploration and reproduction of our results: \url{https://github.com/Ivsucram/CDCL}
ACDC: Online Unsupervised Cross-Domain Adaptation
Oct 04, 2021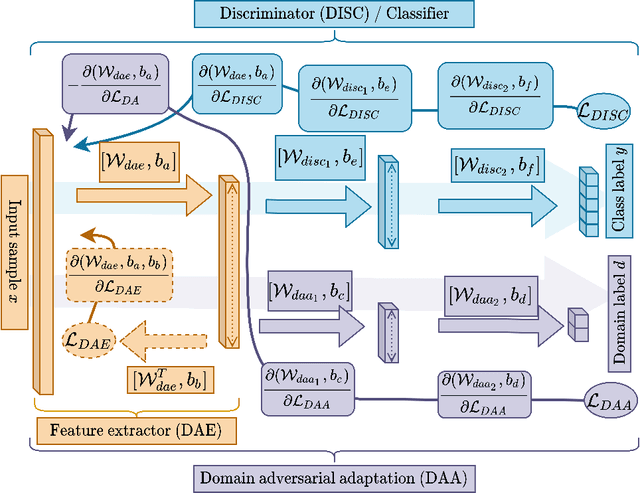
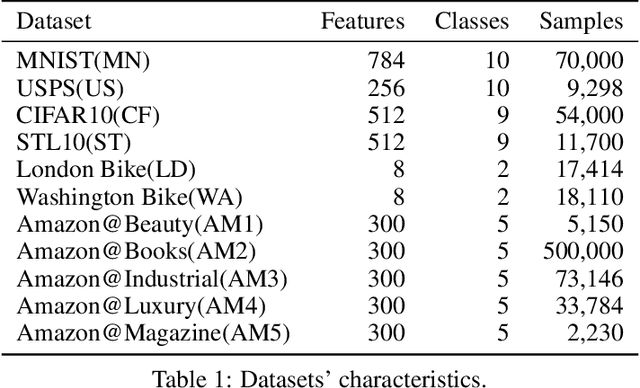
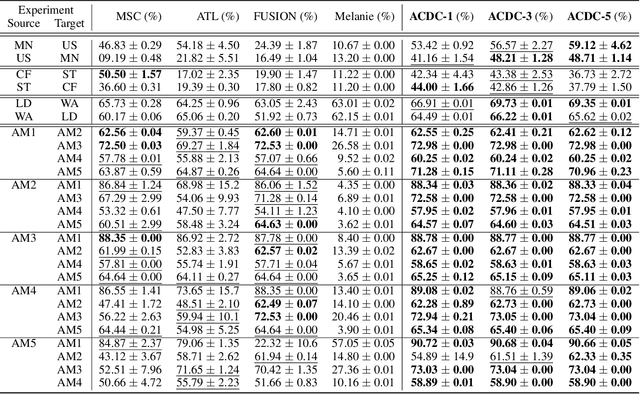
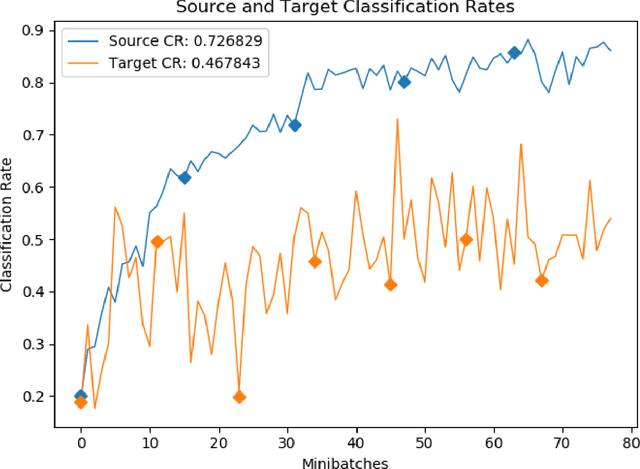
We consider the problem of online unsupervised cross-domain adaptation, where two independent but related data streams with different feature spaces -- a fully labeled source stream and an unlabeled target stream -- are learned together. Unique characteristics and challenges such as covariate shift, asynchronous concept drifts, and contrasting data throughput arises. We propose ACDC, an adversarial unsupervised domain adaptation framework that handles multiple data streams with a complete self-evolving neural network structure that reacts to these defiances. ACDC encapsulates three modules into a single model: A denoising autoencoder that extracts features, an adversarial module that performs domain conversion, and an estimator that learns the source stream and predicts the target stream. ACDC is a flexible and expandable framework with little hyper-parameter tunability. Our experimental results under the prequential test-then-train protocol indicate an improvement in target accuracy over the baseline methods, achieving more than a 10\% increase in some cases.