 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to train your draGAN: A task oriented solution to imbalanced classification
Nov 18, 2022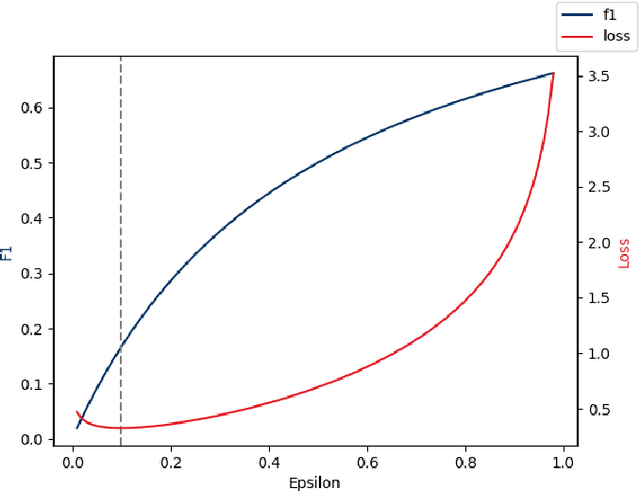
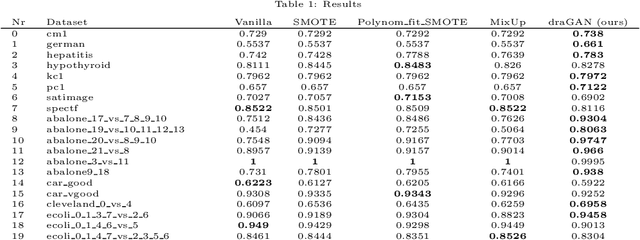
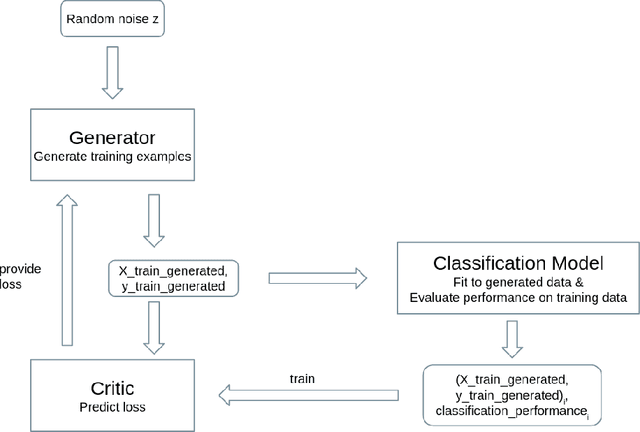
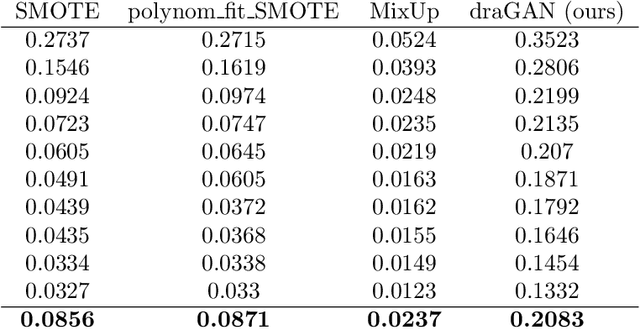
The long-standing challenge of building effective classification models for small and imbalanced datasets has seen little improvement since the creation of the Synthetic Minority Over-sampling Technique (SMOTE) over 20 years ago. Though GAN based models seem promising, there has been a lack of purpose built architectures for solving the aforementioned problem, as most previous studies focus on applying already existing models. This paper proposes a unique, performance-oriented, data-generating strategy that utilizes a new architecture, coined draGAN, to generate both minority and majority samples. The samples are generated with the objective of optimizing the classification model's performance, rather than similarity to the real data. We benchmark our approach against state-of-the-art methods from the SMOTE family and competitive GAN based approaches on 94 tabular datasets with varying degrees of imbalance and linearity. Empirically we show the superiority of draGAN, but also highlight some of its shortcomings. All code is available on: https://github.com/LeonGuertler/draGAN.
Autonomous Cross Domain Adaptation under Extreme Label Scarcity
Sep 04, 2022
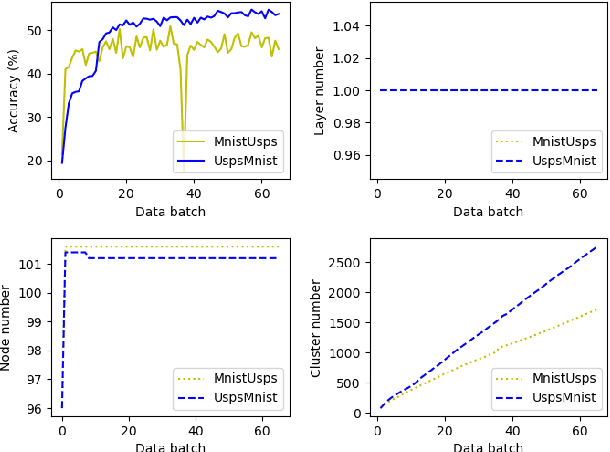
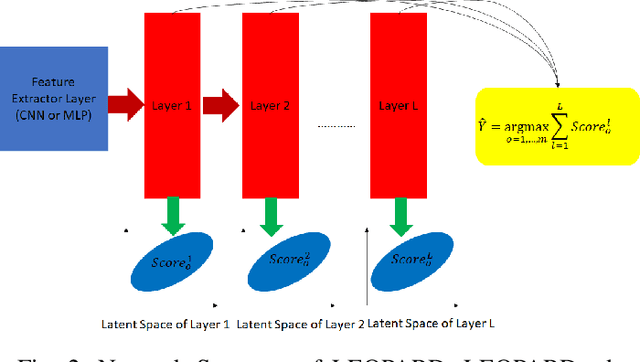
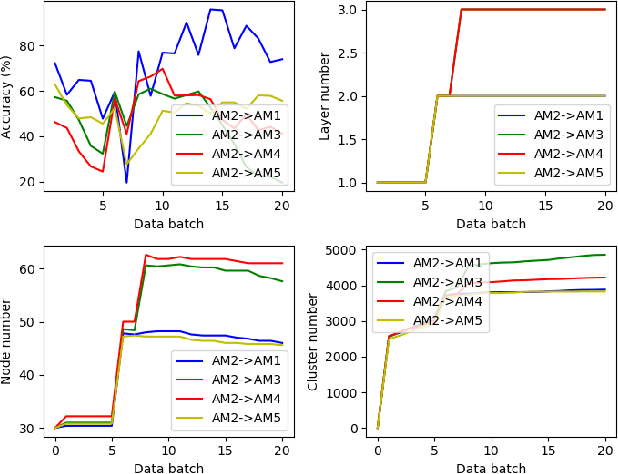
A cross domain multistream classification is a challenging problem calling for fast domain adaptations to handle different but related streams in never-ending and rapidly changing environments. Notwithstanding that existing multistream classifiers assume no labelled samples in the target stream, they still incur expensive labelling cost since they require fully labelled samples of the source stream. This paper aims to attack the problem of extreme label shortage in the cross domain multistream classification problems where only very few labelled samples of the source stream are provided before process runs. Our solution, namely Learning Streaming Process from Partial Ground Truth (LEOPARD), is built upon a flexible deep clustering network where its hidden nodes, layers and clusters are added and removed dynamically in respect to varying data distributions. A deep clustering strategy is underpinned by a simultaneous feature learning and clustering technique leading to clustering-friendly latent spaces. A domain adaptation strategy relies on the adversarial domain adaptation technique where a feature extractor is trained to fool a domain classifier classifying source and target streams. Our numerical study demonstrates the efficacy of LEOPARD where it delivers improved performances compared to prominent algorithms in 15 of 24 cases. Source codes of LEOPARD are shared in \url{https://github.com/wengweng001/LEOPARD.git} to enable further study.
Unsupervised Continual Learning in Streaming Environments
Sep 20, 2021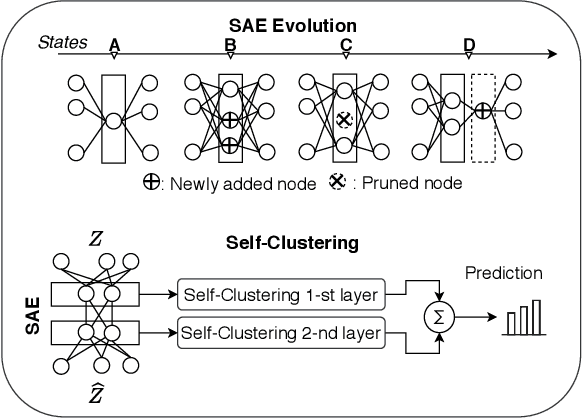
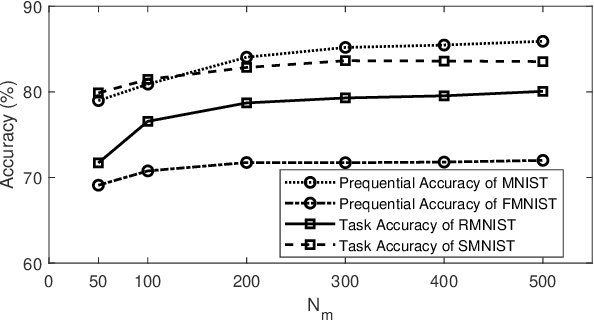
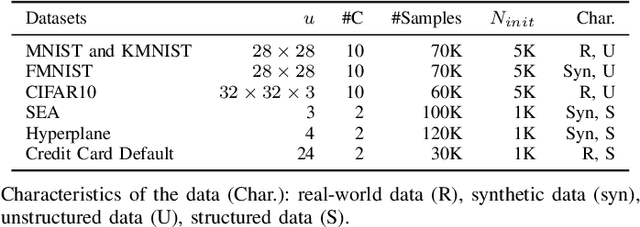
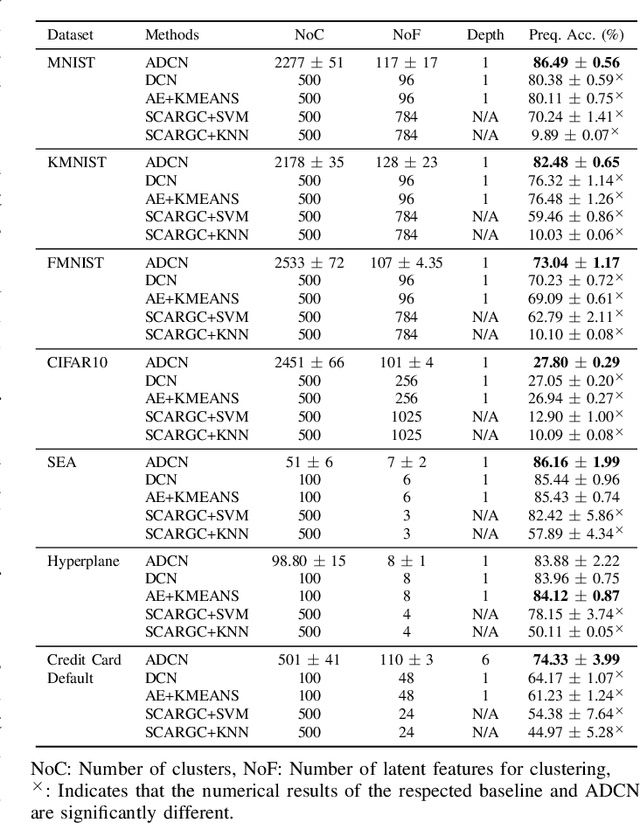
A deep clustering network is desired for data streams because of its aptitude in extracting natural features thus bypassing the laborious feature engineering step. While automatic construction of the deep networks in streaming environments remains an open issue, it is also hindered by the expensive labeling cost of data streams rendering the increasing demand for unsupervised approaches. This paper presents an unsupervised approach of deep clustering network construction on the fly via simultaneous deep learning and clustering termed Autonomous Deep Clustering Network (ADCN). It combines the feature extraction layer and autonomous fully connected layer in which both network width and depth are self-evolved from data streams based on the bias-variance decomposition of reconstruction loss. The self-clustering mechanism is performed in the deep embedding space of every fully connected layer while the final output is inferred via the summation of cluster prediction score. Further, a latent-based regularization is incorporated to resolve the catastrophic forgetting issue. A rigorous numerical study has shown that ADCN produces better performance compared to its counterparts while offering fully autonomous construction of ADCN structure in streaming environments with the absence of any labeled samples for model updates. To support the reproducible research initiative, codes, supplementary material, and raw results of ADCN are made available in \url{https://tinyurl.com/AutonomousDCN}.
Unsupervised Continual Learning via Self-Adaptive Deep Clustering Approach
Jun 28, 2021
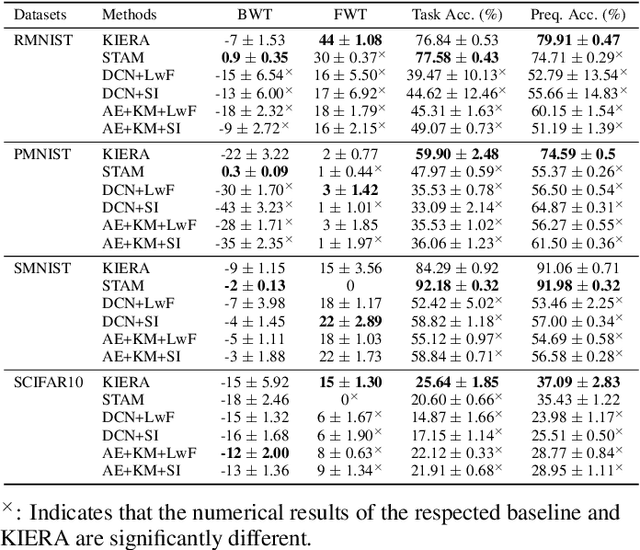
Unsupervised continual learning remains a relatively uncharted territory in the existing literature because the vast majority of existing works call for unlimited access of ground truth incurring expensive labelling cost. Another issue lies in the problem of task boundaries and task IDs which must be known for model's updates or model's predictions hindering feasibility for real-time deployment. Knowledge Retention in Self-Adaptive Deep Continual Learner, (KIERA), is proposed in this paper. KIERA is developed from the notion of flexible deep clustering approach possessing an elastic network structure to cope with changing environments in the timely manner. The centroid-based experience replay is put forward to overcome the catastrophic forgetting problem. KIERA does not exploit any labelled samples for model updates while featuring a task-agnostic merit. The advantage of KIERA has been numerically validated in popular continual learning problems where it shows highly competitive performance compared to state-of-the art approaches. Our implementation is available in \textit{\url{https://github.com/ContinualAL/KIERA}}.
Autonomous Deep Quality Monitoring in Streaming Environments
Jun 26, 2021



The common practice of quality monitoring in industry relies on manual inspection well-known to be slow, error-prone and operator-dependent. This issue raises strong demand for automated real-time quality monitoring developed from data-driven approaches thus alleviating from operator dependence and adapting to various process uncertainties. Nonetheless, current approaches do not take into account the streaming nature of sensory information while relying heavily on hand-crafted features making them application-specific. This paper proposes the online quality monitoring methodology developed from recently developed deep learning algorithms for data streams, Neural Networks with Dynamically Evolved Capacity (NADINE), namely NADINE++. It features the integration of 1-D and 2-D convolutional layers to extract natural features of time-series and visual data streams captured from sensors and cameras of the injection molding machines from our own project. Real-time experiments have been conducted where the online quality monitoring task is simulated on the fly under the prequential test-then-train fashion - the prominent data stream evaluation protocol. Comparison with the state-of-the-art techniques clearly exhibits the advantage of NADINE++ with 4.68\% improvement on average for the quality monitoring task in streaming environments. To support the reproducible research initiative, codes, results of NADINE++ along with supplementary materials and injection molding dataset are made available in \url{https://github.com/ContinualAL/NADINE-IJCNN2021}.
* This paper has been accepted for publication in IJCNN, 2021
Weakly Supervised Deep Learning Approach in Streaming Environments
Nov 14, 2019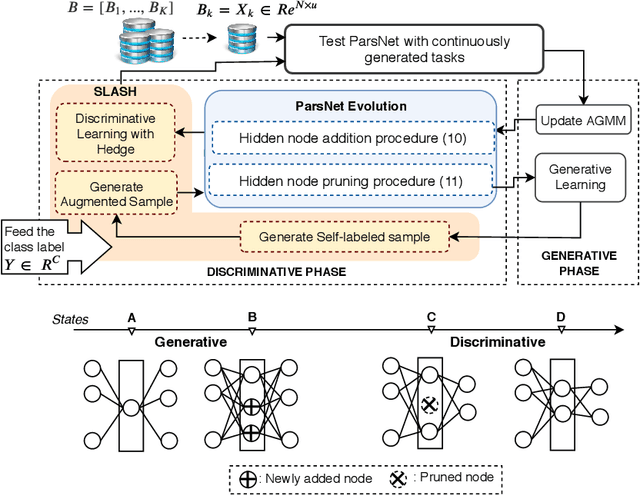
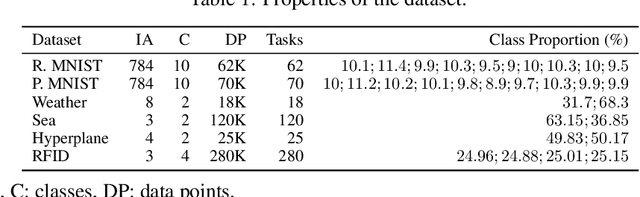
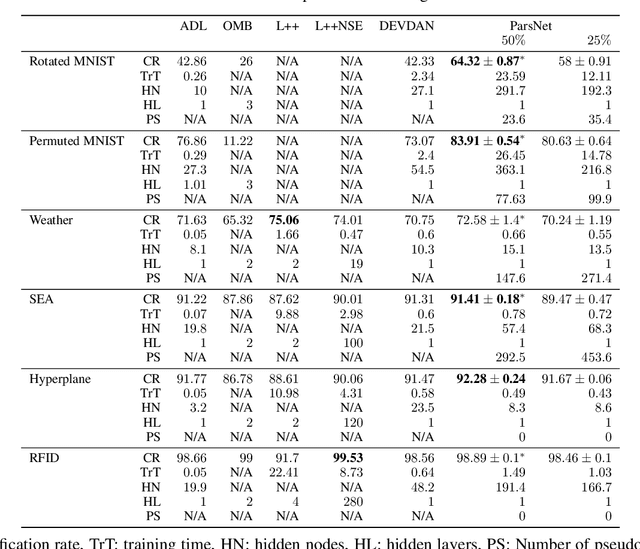

The feasibility of existing data stream algorithms is often hindered by the weakly supervised condition of data streams. A self-evolving deep neural network, namely Parsimonious Network (ParsNet), is proposed as a solution to various weakly-supervised data stream problems. A self-labelling strategy with hedge (SLASH) is proposed in which its auto-correction mechanism copes with \textit{the accumulation of mistakes} significantly affecting the model's generalization. ParsNet is developed from a closed-loop configuration of the self-evolving generative and discriminative training processes exploiting shared parameters in which its structure flexibly grows and shrinks to overcome the issue of concept drift with/without labels. The numerical evaluation has been performed under two challenging problems, namely sporadic access to ground truth and infinitely delayed access to the ground truth. Our numerical study shows the advantage of ParsNet with a substantial margin from its counterparts in the high-dimensional data streams and infinite delay simulation protocol. To support the reproducible research initiative, the source code of ParsNet along with supplementary materials are made available at https://bit.ly/2qNW7p4.
DEVDAN: Deep Evolving Denoising Autoencoder
Oct 08, 2019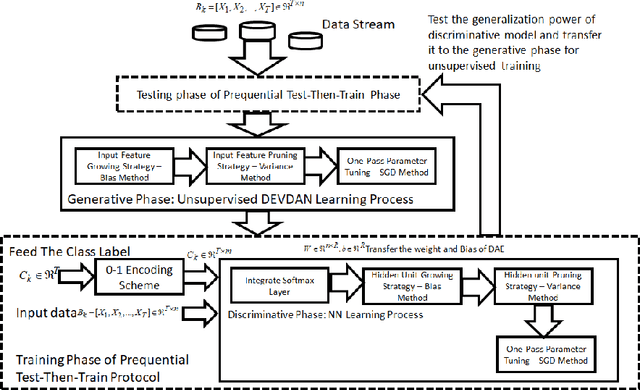

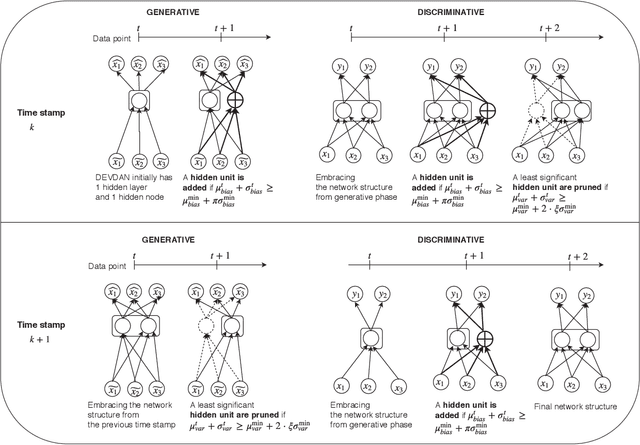
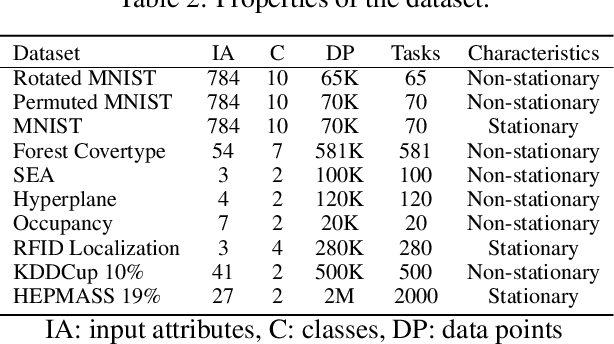
The Denoising Autoencoder (DAE) enhances the flexibility of the data stream method in exploiting unlabeled samples. Nonetheless, the feasibility of DAE for data stream analytic deserves an in-depth study because it characterizes a fixed network capacity that cannot adapt to rapidly changing environments. Deep evolving denoising autoencoder (DEVDAN), is proposed in this paper. It features an open structure in the generative phase and the discriminative phase where the hidden units can be automatically added and discarded on the fly. The generative phase refines the predictive performance of the discriminative model exploiting unlabeled data. Furthermore, DEVDAN is free of the problem-specific threshold and works fully in the single-pass learning fashion. We show that DEVDAN can find competitive network architecture compared with state-of-the-art methods on the classification task using ten prominent datasets simulated under the prequential test-then-train protocol.
Automatic Construction of Multi-layer Perceptron Network from Streaming Examples
Oct 08, 2019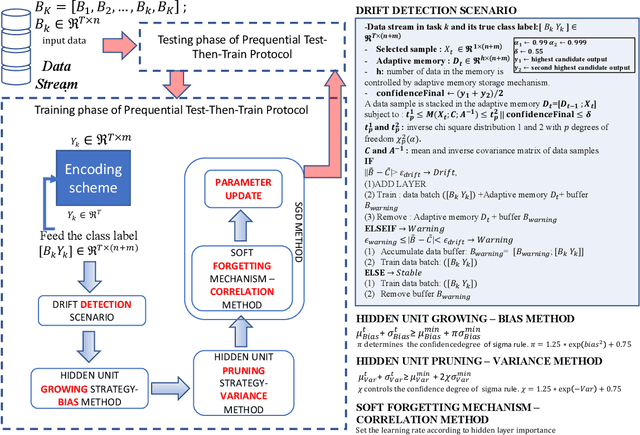
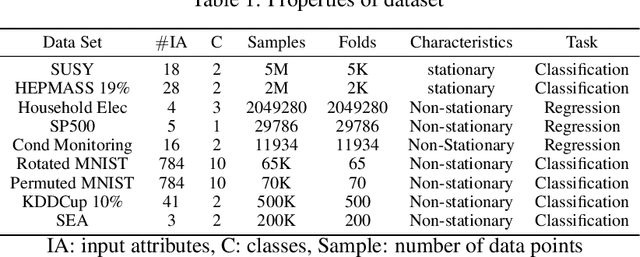
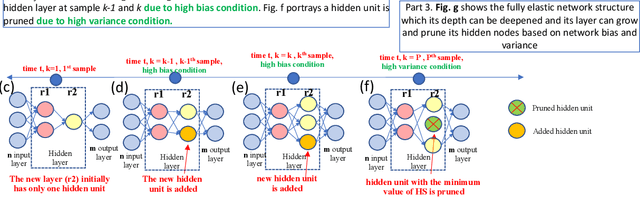
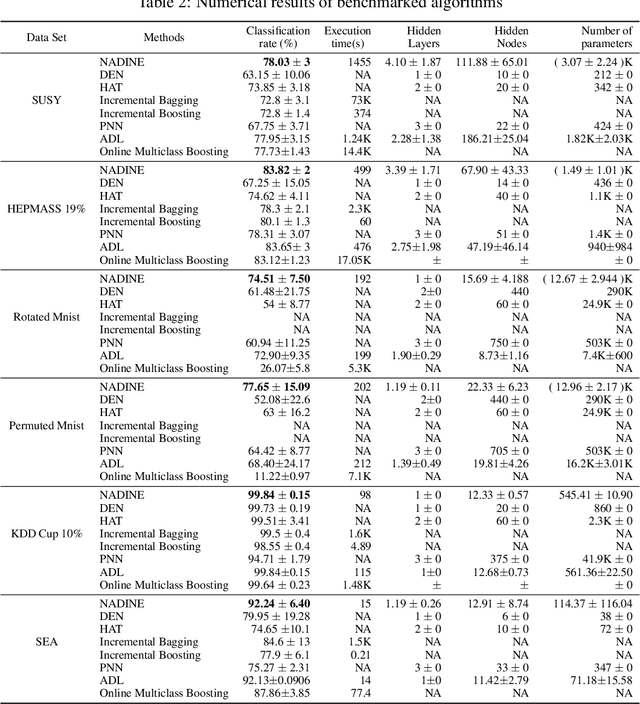
Autonomous construction of deep neural network (DNNs) is desired for data streams because it potentially offers two advantages: proper model's capacity and quick reaction to drift and shift. While the self-organizing mechanism of DNNs remains an open issue, this task is even more challenging to be developed for standard multi-layer DNNs than that using the different-depth structures, because the addition of a new layer results in information loss of previously trained knowledge. A Neural Network with Dynamically Evolved Capacity (NADINE) is proposed in this paper. NADINE features a fully open structure where its network structure, depth and width, can be automatically evolved from scratch in an online manner and without the use of problem-specific thresholds. NADINE is structured under a standard MLP architecture and the catastrophic forgetting issue during the hidden layer addition phase is resolved using the proposal of soft-forgetting and adaptive memory methods. The advantage of NADINE, namely elastic structure and online learning trait, is numerically validated using nine data stream classification and regression problems where it demonstrates performance improvement over prominent algorithms in all problems. In addition, it is capable of dealing with data stream regression and classification problems equally well.
Autonomous Deep Learning: Continual Learning Approach for Dynamic Environments
Oct 17, 2018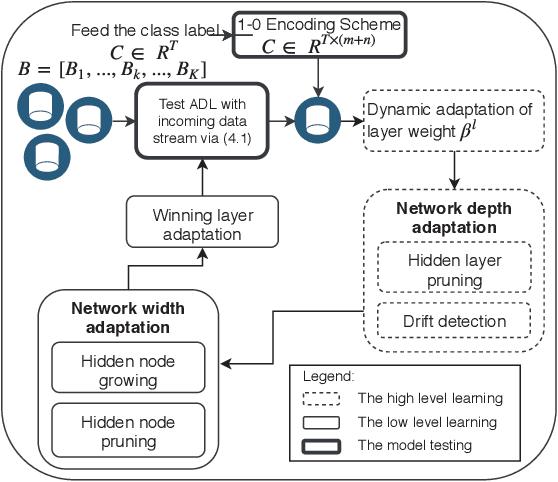
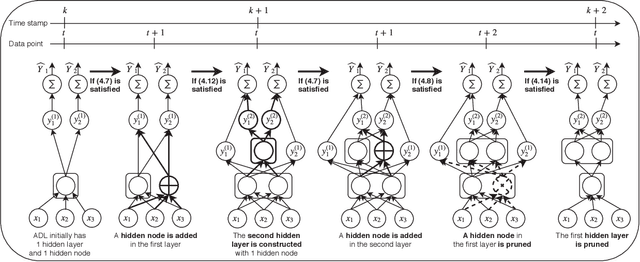
The feasibility of deep neural networks (DNNs) to address data stream problems still requires intensive study because of the static and offline nature of conventional deep learning approaches. A deep continual learning algorithm, namely autonomous deep learning (ADL), is proposed in this paper. Unlike traditional deep learning methods, ADL features a flexible structure where its network structure can be constructed from scratch with the absence of initial network structure via the self-constructing network structure. ADL specifically addresses catastrophic forgetting by having a different-depth structure which is capable of achieving a trade-off between plasticity and stability. Network significance (NS) formula is proposed to drive the hidden nodes growing and pruning mechanism. Drift detection scenario (DDS) is put forward to signal distributional changes in data streams which induce the creation of a new hidden layer. Maximum information compression index (MICI) method plays an important role as a complexity reduction module eliminating redundant layers. The efficacy of ADL is numerically validated under the prequential test-then-train procedure in lifelong environments using nine popular data stream problems. The numerical results demonstrate that ADL consistently outperforms recent continual learning methods while characterizing the automatic construction of network structures.
Autonomous Deep Learning: Incremental Learning of Denoising Autoencoder for Evolving Data Streams
Sep 24, 2018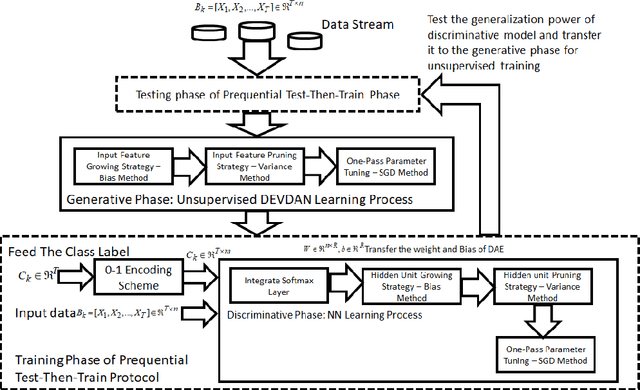
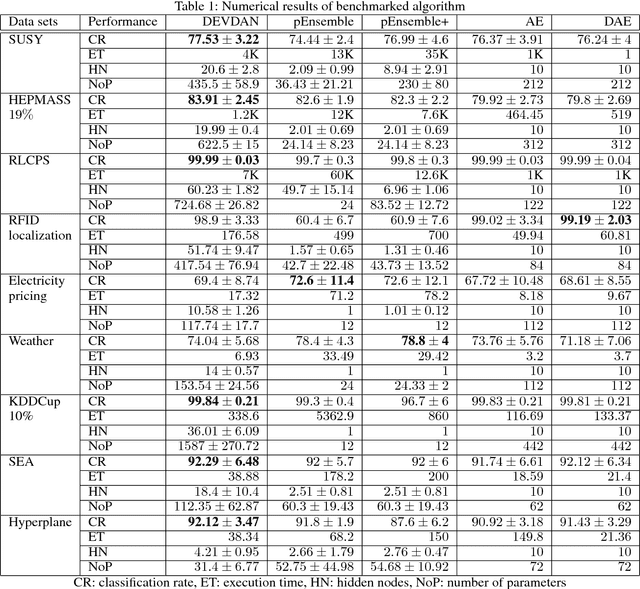
The generative learning phase of Autoencoder (AE) and its successor Denosing Autoencoder (DAE) enhances the flexibility of data stream method in exploiting unlabelled samples. Nonetheless, the feasibility of DAE for data stream analytic deserves in-depth study because it characterizes a fixed network capacity which cannot adapt to rapidly changing environments. An automated construction of a denoising autoeconder, namely deep evolving denoising autoencoder (DEVDAN), is proposed in this paper. DEVDAN features an open structure both in the generative phase and in the discriminative phase where input features can be automatically added and discarded on the fly. A network significance (NS) method is formulated in this paper and is derived from the bias-variance concept. This method is capable of estimating the statistical contribution of the network structure and its hidden units which precursors an ideal state to add or prune input features. Furthermore, DEVDAN is free of the problem- specific threshold and works fully in the single-pass learning fashion. The efficacy of DEVDAN is numerically validated using nine non-stationary data stream problems simulated under the prequential test-then-train protocol where DEVDAN is capable of delivering an improvement of classification accuracy to recently published online learning works while having flexibility in the automatic extraction of robust input features and in adapting to rapidly changing environments.