 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Continual Learning via CLAMP
May 12, 2024



Artificial neural networks, celebrated for their human-like cognitive learning abilities, often encounter the well-known catastrophic forgetting (CF) problem, where the neural networks lose the proficiency in previously acquired knowledge. Despite numerous efforts to mitigate CF, it remains the significant challenge particularly in complex changing environments. This challenge is even more pronounced in cross-domain adaptation following the continual learning (CL) setting, which is a more challenging and realistic scenario that is under-explored. To this end, this article proposes a cross-domain CL approach making possible to deploy a single model in such environments without additional labelling costs. Our approach, namely continual learning approach for many processes (CLAMP), integrates a class-aware adversarial domain adaptation strategy to align a source domain and a target domain. An assessor-guided learning process is put forward to navigate the learning process of a base model assigning a set of weights to every sample controlling the influence of every sample and the interactions of each loss function in such a way to balance the stability and plasticity dilemma thus preventing the CF problem. The first assessor focuses on the negative transfer problem rejecting irrelevant samples of the source domain while the second assessor prevents noisy pseudo labels of the target domain. Both assessors are trained in the meta-learning approach using random transformation techniques and similar samples of the source domain. Theoretical analysis and extensive numerical validations demonstrate that CLAMP significantly outperforms established baseline algorithms across all experiments by at least $10\%$ margin.
Metric-oriented Speech Enhancement using Diffusion Probabilistic Model
Feb 23, 2023Deep neural network based speech enhancement technique focuses on learning a noisy-to-clean transformation supervised by paired training data. However, the task-specific evaluation metric (e.g., PESQ) is usually non-differentiable and can not be directly constructed in the training criteria. This mismatch between the training objective and evaluation metric likely results in sub-optimal performance. To alleviate it, we propose a metric-oriented speech enhancement method (MOSE), which leverages the recent advances in the diffusion probabilistic model and integrates a metric-oriented training strategy into its reverse process. Specifically, we design an actor-critic based framework that considers the evaluation metric as a posterior reward, thus guiding the reverse process to the metric-increasing direction. The experimental results demonstrate that MOSE obviously benefits from metric-oriented training and surpasses the generative baselines in terms of all evaluation metrics.
Autonomous Cross Domain Adaptation under Extreme Label Scarcity
Sep 04, 2022
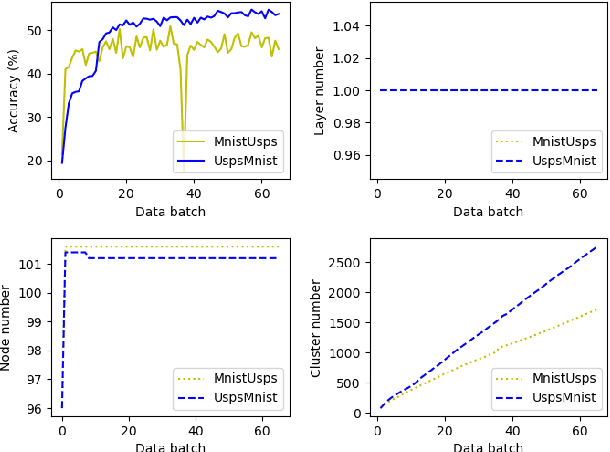
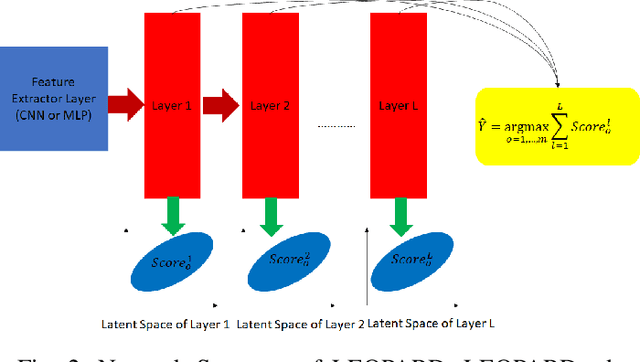
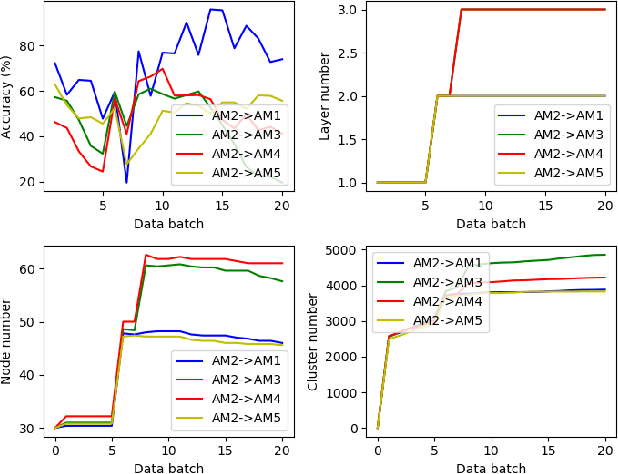
A cross domain multistream classification is a challenging problem calling for fast domain adaptations to handle different but related streams in never-ending and rapidly changing environments. Notwithstanding that existing multistream classifiers assume no labelled samples in the target stream, they still incur expensive labelling cost since they require fully labelled samples of the source stream. This paper aims to attack the problem of extreme label shortage in the cross domain multistream classification problems where only very few labelled samples of the source stream are provided before process runs. Our solution, namely Learning Streaming Process from Partial Ground Truth (LEOPARD), is built upon a flexible deep clustering network where its hidden nodes, layers and clusters are added and removed dynamically in respect to varying data distributions. A deep clustering strategy is underpinned by a simultaneous feature learning and clustering technique leading to clustering-friendly latent spaces. A domain adaptation strategy relies on the adversarial domain adaptation technique where a feature extractor is trained to fool a domain classifier classifying source and target streams. Our numerical study demonstrates the efficacy of LEOPARD where it delivers improved performances compared to prominent algorithms in 15 of 24 cases. Source codes of LEOPARD are shared in \url{https://github.com/wengweng001/LEOPARD.git} to enable further study.