 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Cross Domain Adaptation under Extreme Label Scarcity
Sep 04, 2022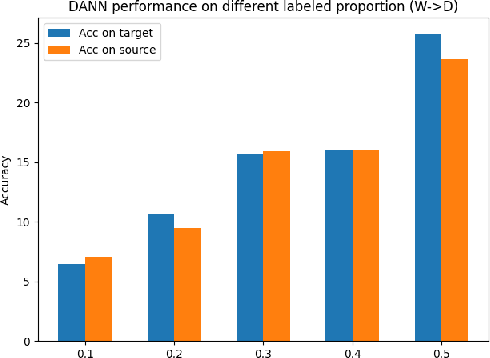
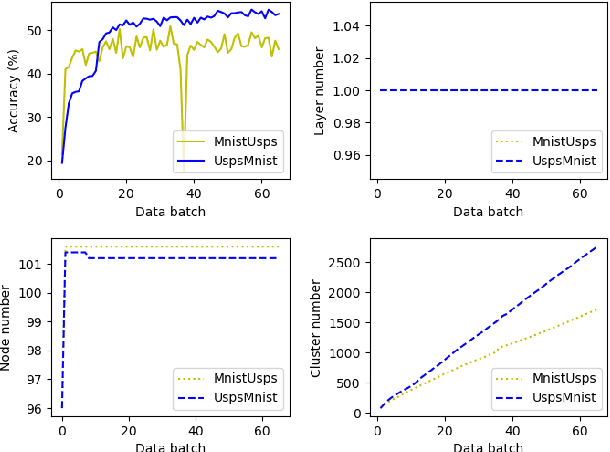
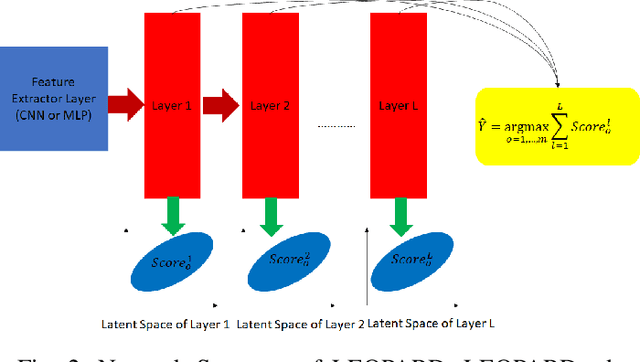
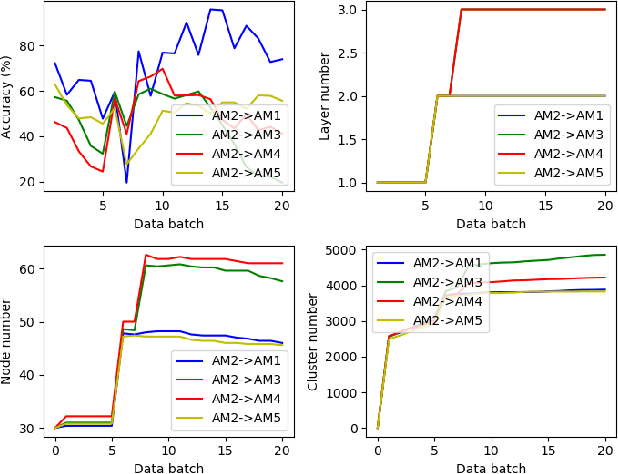
A cross domain multistream classification is a challenging problem calling for fast domain adaptations to handle different but related streams in never-ending and rapidly changing environments. Notwithstanding that existing multistream classifiers assume no labelled samples in the target stream, they still incur expensive labelling cost since they require fully labelled samples of the source stream. This paper aims to attack the problem of extreme label shortage in the cross domain multistream classification problems where only very few labelled samples of the source stream are provided before process runs. Our solution, namely Learning Streaming Process from Partial Ground Truth (LEOPARD), is built upon a flexible deep clustering network where its hidden nodes, layers and clusters are added and removed dynamically in respect to varying data distributions. A deep clustering strategy is underpinned by a simultaneous feature learning and clustering technique leading to clustering-friendly latent spaces. A domain adaptation strategy relies on the adversarial domain adaptation technique where a feature extractor is trained to fool a domain classifier classifying source and target streams. Our numerical study demonstrates the efficacy of LEOPARD where it delivers improved performances compared to prominent algorithms in 15 of 24 cases. Source codes of LEOPARD are shared in \url{https://github.com/wengweng001/LEOPARD.git} to enable further study.