 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Continual Learning via CLAMP
May 12, 2024Artificial neural networks, celebrated for their human-like cognitive learning abilities, often encounter the well-known catastrophic forgetting (CF) problem, where the neural networks lose the proficiency in previously acquired knowledge. Despite numerous efforts to mitigate CF, it remains the significant challenge particularly in complex changing environments. This challenge is even more pronounced in cross-domain adaptation following the continual learning (CL) setting, which is a more challenging and realistic scenario that is under-explored. To this end, this article proposes a cross-domain CL approach making possible to deploy a single model in such environments without additional labelling costs. Our approach, namely continual learning approach for many processes (CLAMP), integrates a class-aware adversarial domain adaptation strategy to align a source domain and a target domain. An assessor-guided learning process is put forward to navigate the learning process of a base model assigning a set of weights to every sample controlling the influence of every sample and the interactions of each loss function in such a way to balance the stability and plasticity dilemma thus preventing the CF problem. The first assessor focuses on the negative transfer problem rejecting irrelevant samples of the source domain while the second assessor prevents noisy pseudo labels of the target domain. Both assessors are trained in the meta-learning approach using random transformation techniques and similar samples of the source domain. Theoretical analysis and extensive numerical validations demonstrate that CLAMP significantly outperforms established baseline algorithms across all experiments by at least $10\%$ margin.
Class-incremental Learning for Time Series: Benchmark and Evaluation
Feb 19, 2024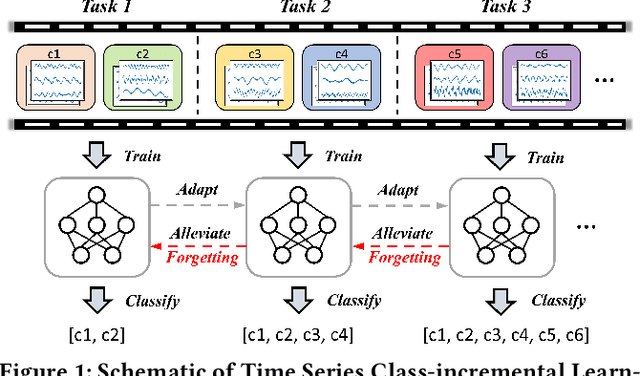
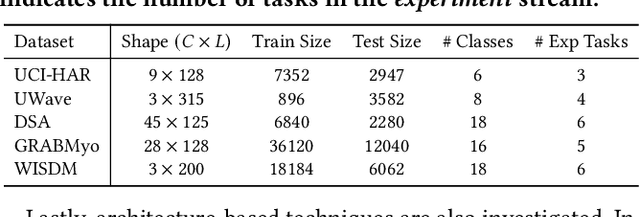
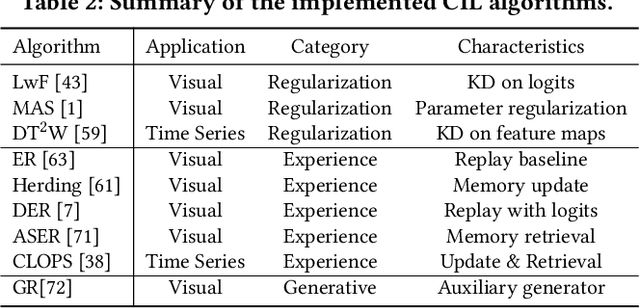
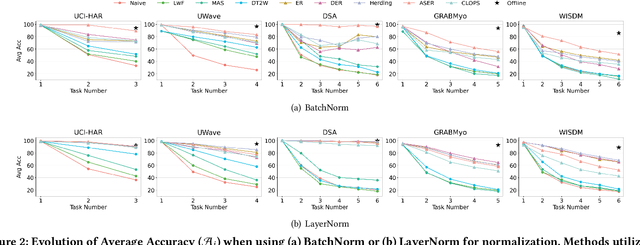
Real-world environments are inherently non-stationary, frequently introducing new classes over time. This is especially common in time series classification, such as the emergence of new disease classification in healthcare or the addition of new activities in human activity recognition. In such cases, a learning system is required to assimilate novel classes effectively while avoiding catastrophic forgetting of the old ones, which gives rise to the Class-incremental Learning (CIL) problem. However, despite the encouraging progress in the image and language domains, CIL for time series data remains relatively understudied. Existing studies suffer from inconsistent experimental designs, necessitating a comprehensive evaluation and benchmarking of methods across a wide range of datasets. To this end, we first present an overview of the Time Series Class-incremental Learning (TSCIL) problem, highlight its unique challenges, and cover the advanced methodologies. Further, based on standardized settings, we develop a unified experimental framework that supports the rapid development of new algorithms, easy integration of new datasets, and standardization of the evaluation process. Using this framework, we conduct a comprehensive evaluation of various generic and time-series-specific CIL methods in both standard and privacy-sensitive scenarios. Our extensive experiments not only provide a standard baseline to support future research but also shed light on the impact of various design factors such as normalization layers or memory budget thresholds. Codes are available at https://github.com/zqiao11/TSCIL.
Robust Continual Learning through a Comprehensively Progressive Bayesian Neural Network
Feb 27, 2022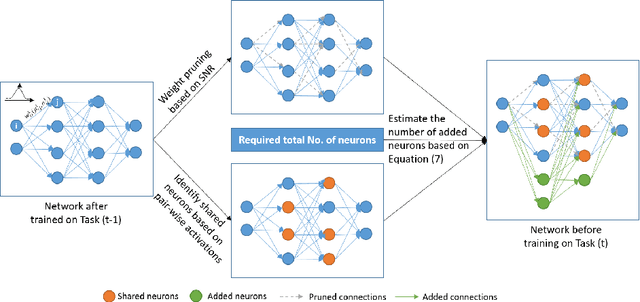
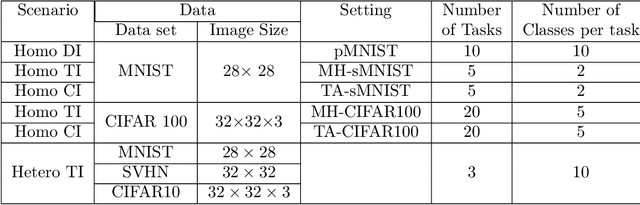
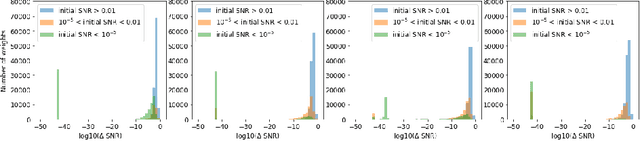
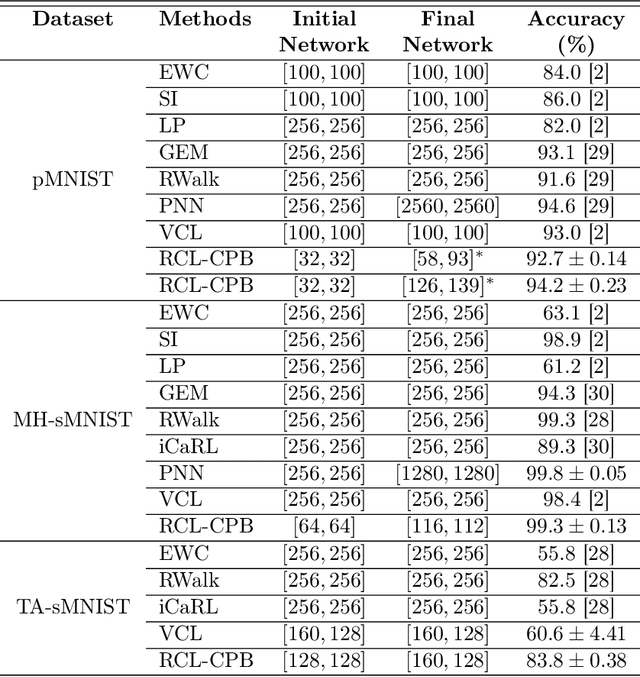
This work proposes a comprehensively progressive Bayesian neural network for robust continual learning of a sequence of tasks. A Bayesian neural network is progressively pruned and grown such that there are sufficient network resources to represent a sequence of tasks, while the network does not explode. It starts with the contention that similar tasks should have the same number of total network resources, to ensure fair representation of all tasks in a continual learning scenario. Thus, as the data for new task streams in, sufficient neurons are added to the network such that the total number of neurons in each layer of the network, including the shared representations with previous tasks and individual task related representation, are equal for all tasks. The weights that are redundant at the end of training each task are also pruned through re-initialization, in order to be efficiently utilized in the subsequent task. Thus, the network grows progressively, but ensures effective utilization of network resources. We refer to our proposed method as 'Robust Continual Learning through a Comprehensively Progressive Bayesian Neural Network (RCL-CPB)' and evaluate the proposed approach on the MNIST data set, under three different continual learning scenarios. Further to this, we evaluate the performance of RCL-CPB on a homogeneous sequence of tasks using split CIFAR100 (20 tasks of 5 classes each), and a heterogeneous sequence of tasks using MNIST, SVHN and CIFAR10 data sets. The demonstrations and the performance results show that the proposed strategies for progressive BNN enable robust continual learning.
Fast classification of small X-ray diffraction datasets using data augmentation and deep neural networks
Nov 20, 2018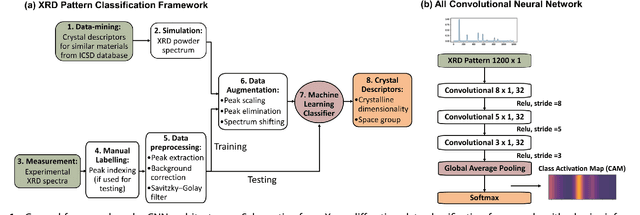
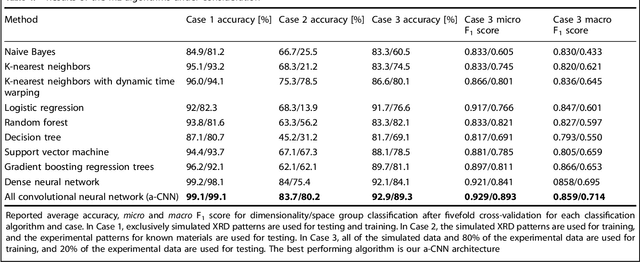
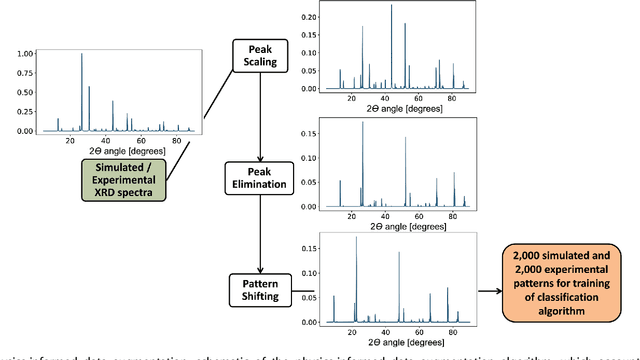
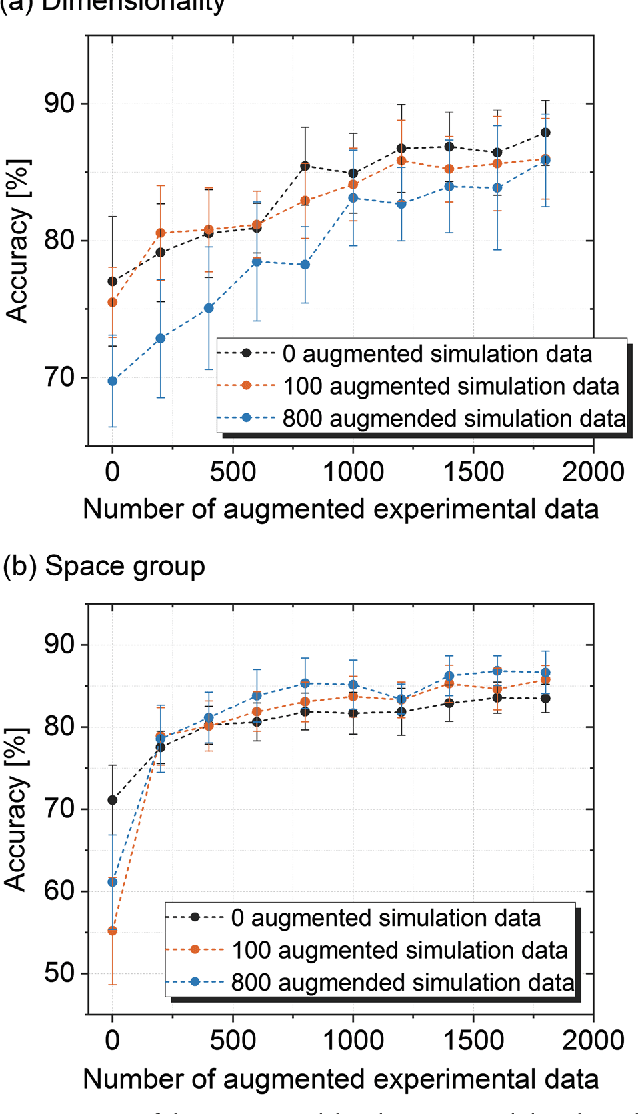
X-ray diffraction (XRD) for crystal structure characterization is among the most time-consuming and complex steps in the development cycle of novel materials. We propose a machine-learning-enabled approach to predict crystallographic dimensionality and space group from a limited number of experimental thin-film XRD patterns. We overcome the sparse-data problem intrinsic to novel materials development by coupling a supervised machine-learning approach with a physics-based data augmentation strategy . Using this approach, XRD spectrum acquisition and analysis occurs under 5.5 minutes, with accuracy comparable to human expert labeling. We simulate experimental powder diffraction patterns from crystallographic information contained in the Inorganic Crystal Structure Database (ICSD). We train a classification algorithm using a combination of labeled simulated and experimental augmented datasets, which account for thin-film characteristics and measurement noise. As a test case, 88 metal-halide thin films spanning 3 dimensionalities and 7 space-groups are synthesized and classified. The accuracies and throughputs of multiple machine-learning techniques are evaluated, along with the effect of augmented dataset size. The most accurate classification algorithm is found to be a feed-forward deep neural network. The calculated accuracies for dimensionality and space-group classification are comparable to ground-truth labelling by a human expert, approximately 90\% and 85\%, respectively. Additionally, we systematically evaluate the maximum XRD spectrum step size (data acquisition rate) before loss of predictive accuracy occurs, and determine it to be \ang{0.16} $2\theta $, which enables an XRD spectrum to be obtained and analyzed in 5 minutes or less.
Graph Convolutional Neural Networks for Polymers Property Prediction
Nov 15, 2018
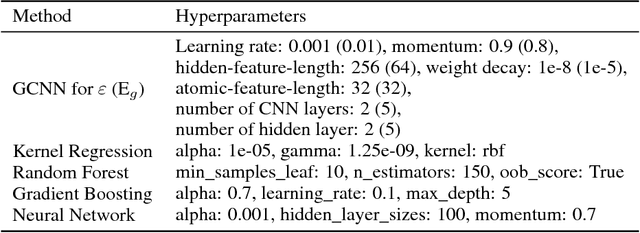


A fast and accurate predictive tool for polymer properties is demanding and will pave the way to iterative inverse design. In this work, we apply graph convolutional neural networks (GCNN) to predict the dielectric constant and energy bandgap of polymers. Using density functional theory (DFT) calculated properties as the ground truth, GCNN can achieve remarkable agreement with DFT results. Moreover, we show that GCNN outperforms other machine learning algorithms. Our work proves that GCNN relies only on morphological data of polymers and removes the requirement for complicated hand-crafted descriptors, while still offering accuracy in fast predictions.