 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-Gen: A Multimodal Language-Conditioned Approach for Interpretable Keypoint-Guided Trajectory Generation
Mar 05, 2026Generating realistic and diverse trajectories is a critical challenge in autonomous driving simulation. While Large Language Models (LLMs) show promise, existing methods often rely on structured data like vectorized maps, which fail to capture the rich, unstructured visual context of a scene. To address this, we propose K-Gen, an interpretable keypoint-guided multimodal framework that leverages Multimodal Large Language Models (MLLMs) to unify rasterized BEV map inputs with textual scene descriptions. Instead of directly predicting full trajectories, K-Gen generates interpretable keypoints along with reasoning that reflects agent intentions, which are subsequently refined into accurate trajectories by a refinement module. To further enhance keypoint generation, we apply T-DAPO, a trajectory-aware reinforcement fine-tuning algorithm. Experiments on WOMD and nuPlan demonstrate that K-Gen outperforms existing baselines, highlighting the effectiveness of combining multimodal reasoning with keypoint-guided trajectory generation.
SaFeR: Safety-Critical Scenario Generation for Autonomous Driving Test via Feasibility-Constrained Token Resampling
Mar 04, 2026Safety-critical scenario generation is crucial for evaluating autonomous driving systems. However, existing approaches often struggle to balance three conflicting objectives: adversarial criticality, physical feasibility, and behavioral realism. To bridge this gap, we propose SaFeR: safety-critical scenario generation for autonomous driving test via feasibility-constrained token resampling. We first formulate traffic generation as a discrete next token prediction problem, employing a Transformer-based model as a realism prior to capture naturalistic driving distributions. To capture complex interactions while effectively mitigating attention noise, we propose a novel differential attention mechanism within the realism prior. Building on this prior, SaFeR implements a novel resampling strategy that induces adversarial behaviors within a high-probability trust region to maintain naturalism, while enforcing a feasibility constraint derived from the Largest Feasible Region (LFR). By approximating the LFR via offline reinforcement learning, SaFeR effectively prevents the generation of theoretically inevitable collisions. Closed-loop experiments on the Waymo Open Motion Dataset and nuPlan demonstrate that SaFeR significantly outperforms state-of-the-art baselines, achieving a higher solution rate and superior kinematic realism while maintaining strong adversarial effectiveness.
Dynamic Stashing Quantization for Efficient Transformer Training
Mar 09, 2023Large Language Models (LLMs) have demonstrated impressive performance on a range of Natural Language Processing (NLP) tasks. Unfortunately, the immense amount of computations and memory accesses required for LLM training makes them prohibitively expensive in terms of hardware cost, and thus challenging to deploy in use cases such as on-device learning. In this paper, motivated by the observation that LLM training is memory-bound, we propose a novel dynamic quantization strategy, termed Dynamic Stashing Quantization (DSQ), that puts a special focus on reducing the memory operations, but also enjoys the other benefits of low precision training, such as the reduced arithmetic cost. We conduct a thorough study on two translation tasks (trained-from-scratch) and three classification tasks (fine-tuning). DSQ reduces the amount of arithmetic operations by $20.95\times$ and the number of DRAM operations by $2.55\times$ on IWSLT17 compared to the standard 16-bit fixed-point, which is widely used in on-device learning.
Robust Continual Learning through a Comprehensively Progressive Bayesian Neural Network
Feb 27, 2022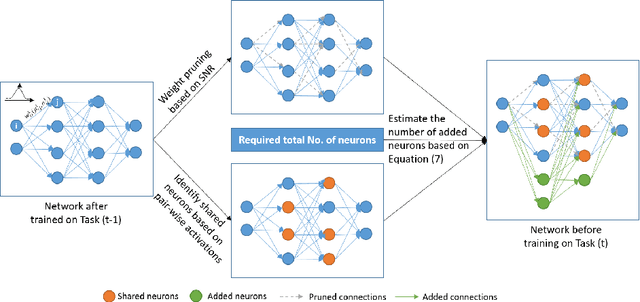
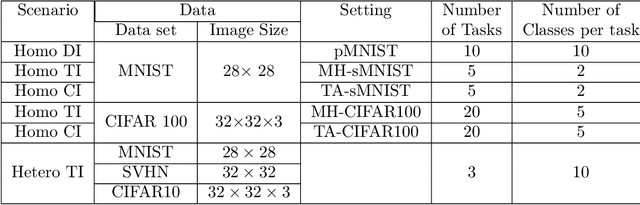
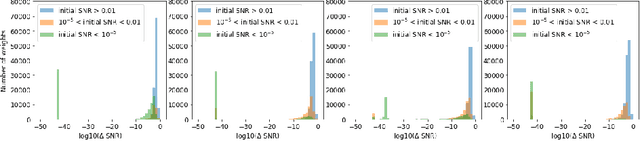
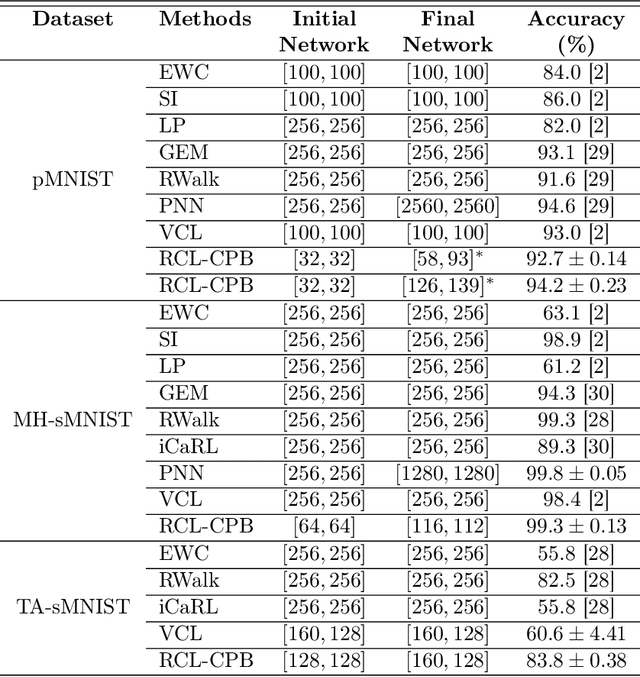
This work proposes a comprehensively progressive Bayesian neural network for robust continual learning of a sequence of tasks. A Bayesian neural network is progressively pruned and grown such that there are sufficient network resources to represent a sequence of tasks, while the network does not explode. It starts with the contention that similar tasks should have the same number of total network resources, to ensure fair representation of all tasks in a continual learning scenario. Thus, as the data for new task streams in, sufficient neurons are added to the network such that the total number of neurons in each layer of the network, including the shared representations with previous tasks and individual task related representation, are equal for all tasks. The weights that are redundant at the end of training each task are also pruned through re-initialization, in order to be efficiently utilized in the subsequent task. Thus, the network grows progressively, but ensures effective utilization of network resources. We refer to our proposed method as 'Robust Continual Learning through a Comprehensively Progressive Bayesian Neural Network (RCL-CPB)' and evaluate the proposed approach on the MNIST data set, under three different continual learning scenarios. Further to this, we evaluate the performance of RCL-CPB on a homogeneous sequence of tasks using split CIFAR100 (20 tasks of 5 classes each), and a heterogeneous sequence of tasks using MNIST, SVHN and CIFAR10 data sets. The demonstrations and the performance results show that the proposed strategies for progressive BNN enable robust continual learning.