 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHADT: A Heterogeneous Multi-Agent Differential Transformer for Autonomous Earth Observation Satellite Cluster
May 29, 2026This work addresses the problem of autonomous resource management in heterogeneous satellite cluster conducting Earth Observation (EO) missions including optical and Synthetic Aperture Radar (SAR) satellites. In autonomous operation mode, satellites are equipped with intelligent capabilities enabling real-time decision-making based on the latest conditions, while requiring minimal interaction with ground operators. Traditional scheduling approaches typically rely on mathematical models to represent satellite mission and resource management. Then, this problem is solved by using optimization algorithms. However, such solutions become less effective when the underlying models are not available, over complex, and inaccurate due to dynamic changes and uncertainties inherent in the space mission environment. A promising alternative is to reformulate the problem as a sequential decision-making process and apply model-free reinforcement learning techniques to enable adaptive and real-time resource management. To this end, we propose a novel transformer-based architecture tailored for heterogeneous satellite cluster autonomous EO Mission with relational observations-actions tokenization and differential attention mechanism. Our experimental results demonstrate significant performance improvements compared to the available baselines. Moreover, the proposed architecture exhibits strong adaptability and transferability with respect to varying numbers of satellite clusters.
KD-MARL: Resource-Aware Knowledge Distillation in Multi-Agent Reinforcement Learning
Apr 08, 2026Real world deployment of multi agent reinforcement learning MARL systems is fundamentally constrained by limited compute memory and inference time. While expert policies achieve high performance they rely on costly decision cycles and large scale models that are impractical for edge devices or embedded platforms. Knowledge distillation KD offers a promising path toward resource aware execution but existing KD methods in MARL focus narrowly on action imitation often neglecting coordination structure and assuming uniform agent capabilities. We propose resource aware Knowledge Distillation for Multi Agent Reinforcement Learning KD MARL a two stage framework that transfers coordinated behavior from a centralized expert to lightweight decentralized student agents. The student policies are trained without a critic relying instead on distilled advantage signals and structured policy supervision to preserve coordination under heterogeneous and limited observations. Our approach transfers both action level behavior and structural coordination patterns from expert policies while supporting heterogeneous student architectures allowing each agent model capacity to match its observation complexity which is crucial for efficient execution under partial or limited observability and limited onboard resources. Extensive experiments on SMAC and MPE benchmarks demonstrate that KD MARL achieves high performance retention while substantially reducing computational cost. Across standard multi agent benchmarks KD MARL retains over 90 percent of expert performance while reducing computational cost by up to 28.6 times FLOPs. The proposed approach achieves expert level coordination and preserves it through structured distillation enabling practical MARL deployment across resource constrained onboard platforms.
Onboard Optimization and Learning: A Survey
May 07, 2025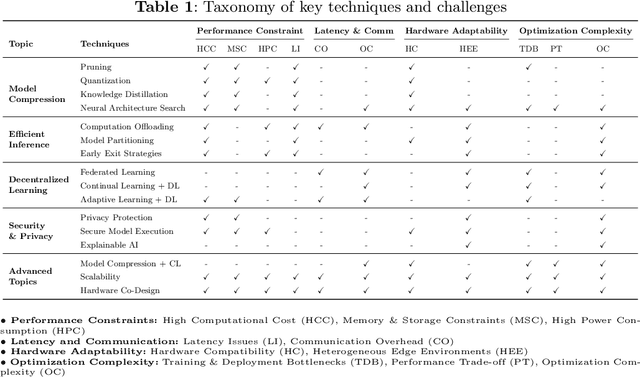
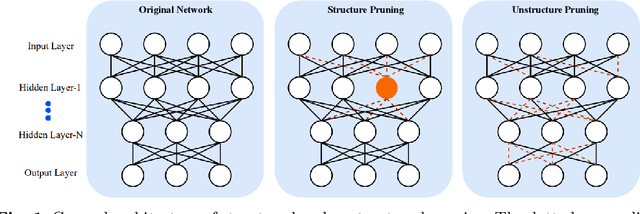
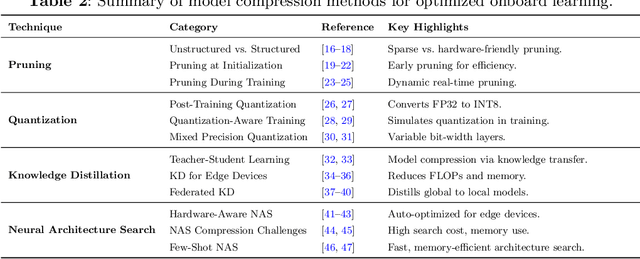
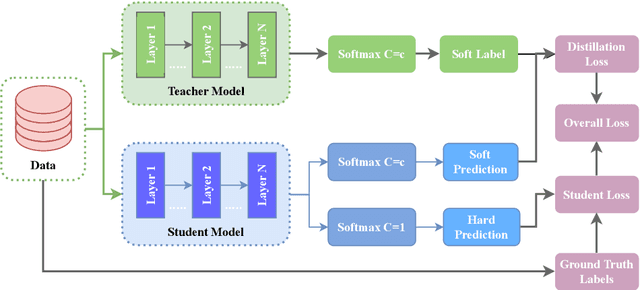
Onboard learning is a transformative approach in edge AI, enabling real-time data processing, decision-making, and adaptive model training directly on resource-constrained devices without relying on centralized servers. This paradigm is crucial for applications demanding low latency, enhanced privacy, and energy efficiency. However, onboard learning faces challenges such as limited computational resources, high inference costs, and security vulnerabilities. This survey explores a comprehensive range of methodologies that address these challenges, focusing on techniques that optimize model efficiency, accelerate inference, and support collaborative learning across distributed devices. Approaches for reducing model complexity, improving inference speed, and ensuring privacy-preserving computation are examined alongside emerging strategies that enhance scalability and adaptability in dynamic environments. By bridging advancements in hardware-software co-design, model compression, and decentralized learning, this survey provides insights into the current state of onboard learning to enable robust, efficient, and secure AI deployment at the edge.
Mixed Diffusion for 3D Indoor Scene Synthesis
May 31, 2024



Realistic conditional 3D scene synthesis significantly enhances and accelerates the creation of virtual environments, which can also provide extensive training data for computer vision and robotics research among other applications. Diffusion models have shown great performance in related applications, e.g., making precise arrangements of unordered sets. However, these models have not been fully explored in floor-conditioned scene synthesis problems. We present MiDiffusion, a novel mixed discrete-continuous diffusion model architecture, designed to synthesize plausible 3D indoor scenes from given room types, floor plans, and potentially pre-existing objects. We represent a scene layout by a 2D floor plan and a set of objects, each defined by its category, location, size, and orientation. Our approach uniquely implements structured corruption across the mixed discrete semantic and continuous geometric domains, resulting in a better conditioned problem for the reverse denoising step. We evaluate our approach on the 3D-FRONT dataset. Our experimental results demonstrate that MiDiffusion substantially outperforms state-of-the-art autoregressive and diffusion models in floor-conditioned 3D scene synthesis. In addition, our models can handle partial object constraints via a corruption-and-masking strategy without task specific training. We show MiDiffusion maintains clear advantages over existing approaches in scene completion and furniture arrangement experiments.
Debunking Disinformation: Revolutionizing Truth with NLP in Fake News Detection
Aug 30, 2023The Internet and social media have altered how individuals access news in the age of instantaneous information distribution. While this development has increased access to information, it has also created a significant problem: the spread of fake news and information. Fake news is rapidly spreading on digital platforms, which has a negative impact on the media ecosystem, public opinion, decision-making, and social cohesion. Natural Language Processing(NLP), which offers a variety of approaches to identify content as authentic, has emerged as a potent weapon in the growing war against disinformation. This paper takes an in-depth look at how NLP technology can be used to detect fake news and reveals the challenges and opportunities it presents.
ProAgent: Building Proactive Cooperative AI with Large Language Models
Aug 28, 2023


Building AIs with adaptive behaviors in human-AI cooperation stands as a pivotal focus in AGI research. Current methods for developing cooperative agents predominantly rely on learning-based methods, where policy generalization heavily hinges on past interactions with specific teammates. These approaches constrain the agent's capacity to recalibrate its strategy when confronted with novel teammates. We propose \textbf{ProAgent}, a novel framework that harnesses large language models (LLMs) to fashion a \textit{pro}active \textit{agent} empowered with the ability to anticipate teammates' forthcoming decisions and formulate enhanced plans for itself. ProAgent excels at cooperative reasoning with the capacity to dynamically adapt its behavior to enhance collaborative efforts with teammates. Moreover, the ProAgent framework exhibits a high degree of modularity and interpretability, facilitating seamless integration to address a wide array of coordination scenarios. Experimental evaluations conducted within the framework of \textit{Overcook-AI} unveil the remarkable performance superiority of ProAgent, outperforming five methods based on self-play and population-based training in cooperation with AI agents. Further, when cooperating with human proxy models, its performance exhibits an average improvement exceeding 10\% compared to the current state-of-the-art, COLE. The advancement was consistently observed across diverse scenarios involving interactions with both AI agents of varying characteristics and human counterparts. These findings inspire future research for human-robot collaborations. For a hands-on demonstration, please visit \url{https://pku-proagent.github.io}.
Maximum Entropy Heterogeneous-Agent Mirror Learning
Jun 19, 2023Multi-agent reinforcement learning (MARL) has been shown effective for cooperative games in recent years. However, existing state-of-the-art methods face challenges related to sample inefficiency, brittleness regarding hyperparameters, and the risk of converging to a suboptimal Nash Equilibrium. To resolve these issues, in this paper, we propose a novel theoretical framework, named Maximum Entropy Heterogeneous-Agent Mirror Learning (MEHAML), that leverages the maximum entropy principle to design maximum entropy MARL actor-critic algorithms. We prove that algorithms derived from the MEHAML framework enjoy the desired properties of the monotonic improvement of the joint maximum entropy objective and the convergence to quantal response equilibrium (QRE). The practicality of MEHAML is demonstrated by developing a MEHAML extension of the widely used RL algorithm, HASAC (for soft actor-critic), which shows significant improvements in exploration and robustness on three challenging benchmarks: Multi-Agent MuJoCo, StarCraftII, and Google Research Football. Our results show that HASAC outperforms strong baseline methods such as HATD3, HAPPO, QMIX, and MAPPO, thereby establishing the new state of the art. See our project page at https://sites.google.com/view/mehaml.
Foundations of Spatial Perception for Robotics: Hierarchical Representations and Real-time Systems
May 11, 20233D spatial perception is the problem of building and maintaining an actionable and persistent representation of the environment in real-time using sensor data and prior knowledge. Despite the fast-paced progress in robot perception, most existing methods either build purely geometric maps (as in traditional SLAM) or flat metric-semantic maps that do not scale to large environments or large dictionaries of semantic labels. The first part of this paper is concerned with representations: we show that scalable representations for spatial perception need to be hierarchical in nature. Hierarchical representations are efficient to store, and lead to layered graphs with small treewidth, which enable provably efficient inference. We then introduce an example of hierarchical representation for indoor environments, namely a 3D scene graph, and discuss its structure and properties. The second part of the paper focuses on algorithms to incrementally construct a 3D scene graph as the robot explores the environment. Our algorithms combine 3D geometry, topology (to cluster the places into rooms), and geometric deep learning (e.g., to classify the type of rooms the robot is moving across). The third part of the paper focuses on algorithms to maintain and correct 3D scene graphs during long-term operation. We propose hierarchical descriptors for loop closure detection and describe how to correct a scene graph in response to loop closures, by solving a 3D scene graph optimization problem. We conclude the paper by combining the proposed perception algorithms into Hydra, a real-time spatial perception system that builds a 3D scene graph from visual-inertial data in real-time. We showcase Hydra's performance in photo-realistic simulations and real data collected by a Clearpath Jackal robots and a Unitree A1 robot. We release an open-source implementation of Hydra at https://github.com/MIT-SPARK/Hydra.
Heterogeneous-Agent Reinforcement Learning
Apr 19, 2023



The necessity for cooperation among intelligent machines has popularised cooperative multi-agent reinforcement learning (MARL) in AI research. However, many research endeavours heavily rely on parameter sharing among agents, which confines them to only homogeneous-agent setting and leads to training instability and lack of convergence guarantees. To achieve effective cooperation in the general heterogeneous-agent setting, we propose Heterogeneous-Agent Reinforcement Learning (HARL) algorithms that resolve the aforementioned issues. Central to our findings are the multi-agent advantage decomposition lemma and the sequential update scheme. Based on these, we develop the provably correct Heterogeneous-Agent Trust Region Learning (HATRL) that is free of parameter-sharing constraint, and derive HATRPO and HAPPO by tractable approximations. Furthermore, we discover a novel framework named Heterogeneous-Agent Mirror Learning (HAML), which strengthens theoretical guarantees for HATRPO and HAPPO and provides a general template for cooperative MARL algorithmic designs. We prove that all algorithms derived from HAML inherently enjoy monotonic improvement of joint reward and convergence to Nash Equilibrium. As its natural outcome, HAML validates more novel algorithms in addition to HATRPO and HAPPO, including HAA2C, HADDPG, and HATD3, which consistently outperform their existing MA-counterparts. We comprehensively test HARL algorithms on six challenging benchmarks and demonstrate their superior effectiveness and stability for coordinating heterogeneous agents compared to strong baselines such as MAPPO and QMIX.
Leveraging Large Language Models for Robot 3D Scene Understanding
Sep 12, 2022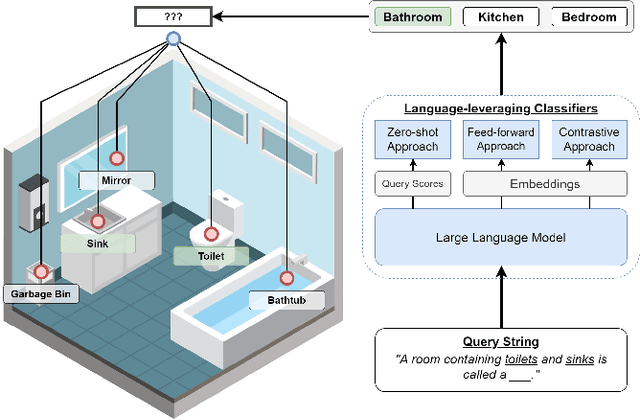

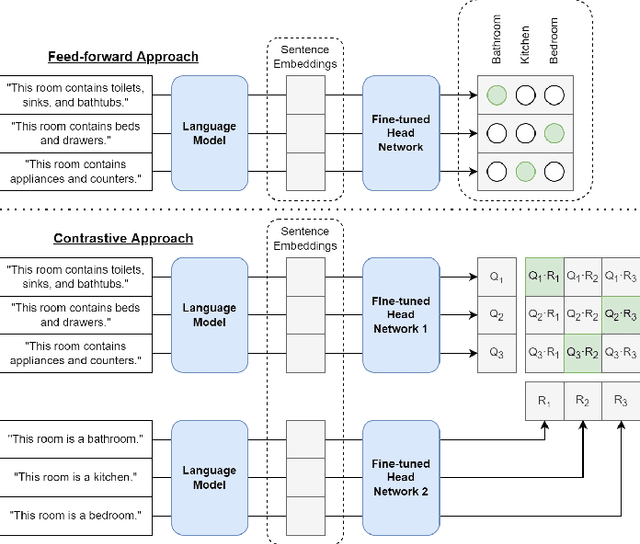
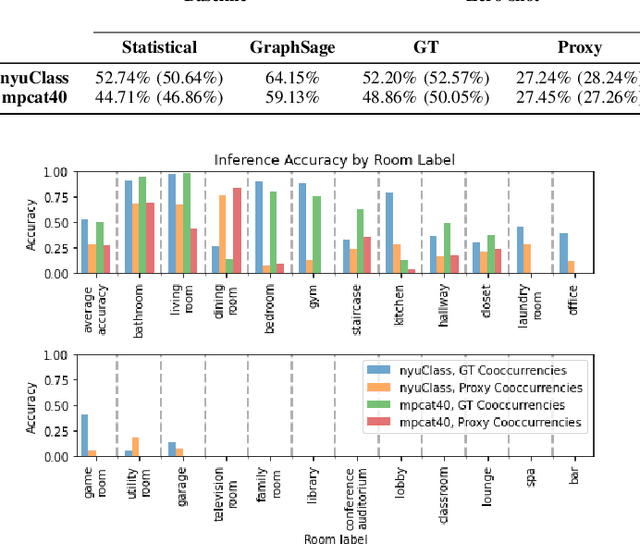
Semantic 3D scene understanding is a problem of critical importance in robotics. While significant advances have been made in spatial perception, robots are still far from having the common-sense knowledge about household objects and locations of an average human. We thus investigate the use of large language models to impart common sense for scene understanding. Specifically, we introduce three paradigms for leveraging language for classifying rooms in indoor environments based on their contained objects: (i) a zero-shot approach, (ii) a feed-forward classifier approach, and (iii) a contrastive classifier approach. These methods operate on 3D scene graphs produced by modern spatial perception systems. We then analyze each approach, demonstrating notable zero-shot generalization and transfer capabilities stemming from their use of language. Finally, we show these approaches also apply to inferring building labels from contained rooms and demonstrate our zero-shot approach on a real environment. All code can be found at https://github.com/MIT-SPARK/llm_scene_understanding.