 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem Design for Maintaining Internal State Consistency in Long-Horizon Robotic Tabletop Games
Mar 26, 2026Long-horizon tabletop games pose a distinct systems challenge for robotics: small perceptual or execution errors can invalidate accumulated task state, propagate across decision-making modules, and ultimately derail interaction. This paper studies how to maintain internal state consistency in turn-based, multi-human robotic tabletop games through deliberate system design rather than isolated component improvement. Using Mahjong as a representative long-horizon setting, we present an integrated architecture that explicitly maintains perceptual, execution, and interaction state, partitions high-level semantic reasoning from time-critical perception and control, and incorporates verified action primitives with tactile-triggered recovery to prevent premature state corruption. We further introduce interaction-level monitoring mechanisms to detect turn violations and hidden-information breaches that threaten execution assumptions. Beyond demonstrating complete-game operation, we provide an empirical characterization of failure modes, recovery effectiveness, cross-module error propagation, and hardware-algorithm trade-offs observed during deployment. Our results show that explicit partitioning, monitored state transitions, and recovery mechanisms are critical for sustaining executable consistency over extended play, whereas monolithic or unverified pipelines lead to measurable degradation in end-to-end reliability. The proposed system serves as an empirical platform for studying system-level design principles in long-horizon, turn-based interaction.
A Survey on Vision-Language-Action Models: An Action Tokenization Perspective
Jul 02, 2025The remarkable advancements of vision and language foundation models in multimodal understanding, reasoning, and generation has sparked growing efforts to extend such intelligence to the physical world, fueling the flourishing of vision-language-action (VLA) models. Despite seemingly diverse approaches, we observe that current VLA models can be unified under a single framework: vision and language inputs are processed by a series of VLA modules, producing a chain of \textit{action tokens} that progressively encode more grounded and actionable information, ultimately generating executable actions. We further determine that the primary design choice distinguishing VLA models lies in how action tokens are formulated, which can be categorized into language description, code, affordance, trajectory, goal state, latent representation, raw action, and reasoning. However, there remains a lack of comprehensive understanding regarding action tokens, significantly impeding effective VLA development and obscuring future directions. Therefore, this survey aims to categorize and interpret existing VLA research through the lens of action tokenization, distill the strengths and limitations of each token type, and identify areas for improvement. Through this systematic review and analysis, we offer a synthesized outlook on the broader evolution of VLA models, highlight underexplored yet promising directions, and contribute guidance for future research, hoping to bring the field closer to general-purpose intelligence.
DexGraspVLA: A Vision-Language-Action Framework Towards General Dexterous Grasping
Feb 28, 2025Dexterous grasping remains a fundamental yet challenging problem in robotics. A general-purpose robot must be capable of grasping diverse objects in arbitrary scenarios. However, existing research typically relies on specific assumptions, such as single-object settings or limited environments, leading to constrained generalization. Our solution is DexGraspVLA, a hierarchical framework that utilizes a pre-trained Vision-Language model as the high-level task planner and learns a diffusion-based policy as the low-level Action controller. The key insight lies in iteratively transforming diverse language and visual inputs into domain-invariant representations, where imitation learning can be effectively applied due to the alleviation of domain shift. Thus, it enables robust generalization across a wide range of real-world scenarios. Notably, our method achieves a 90+% success rate under thousands of unseen object, lighting, and background combinations in a ``zero-shot'' environment. Empirical analysis further confirms the consistency of internal model behavior across environmental variations, thereby validating our design and explaining its generalization performance. We hope our work can be a step forward in achieving general dexterous grasping. Our demo and code can be found at https://dexgraspvla.github.io/.
In-Context Editing: Learning Knowledge from Self-Induced Distributions
Jun 17, 2024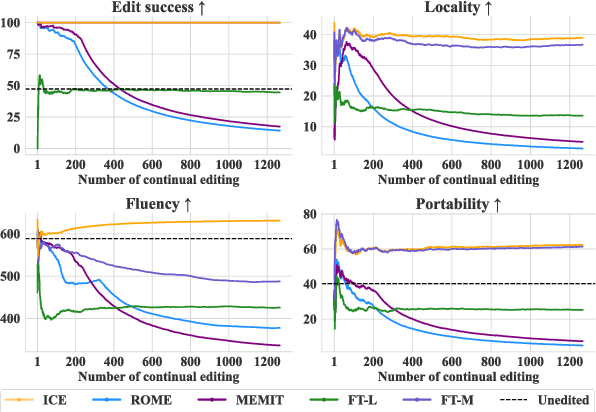
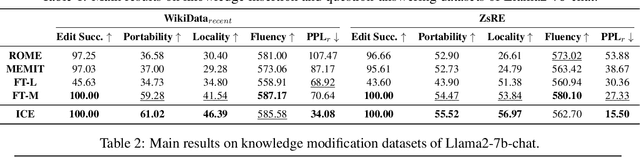
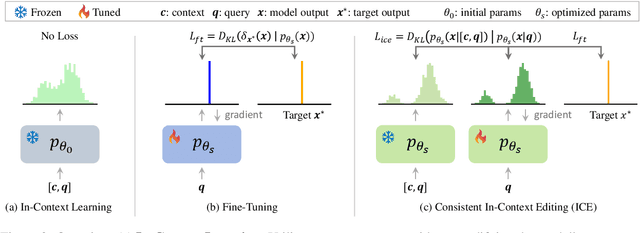
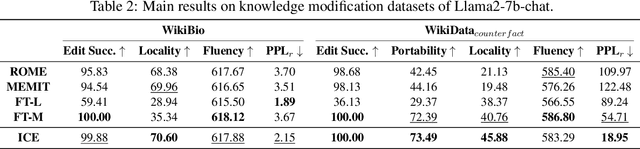
The existing fine-tuning paradigm for language models is brittle in knowledge editing scenarios, where the model must incorporate new information without extensive retraining. This brittleness often results in overfitting, reduced performance, and unnatural language generation. To address this, we propose Consistent In-Context Editing (ICE), a novel approach that leverages the model's in-context learning capability to tune toward a contextual distribution rather than a one-hot target. ICE introduces a straightforward optimization framework that includes both a target and a procedure, enhancing the robustness and effectiveness of gradient-based tuning methods. We provide analytical insights into ICE across four critical aspects of knowledge editing: accuracy, locality, generalization, and linguistic quality, showing its advantages. Experimental results across four datasets confirm the effectiveness of ICE and demonstrate its potential for continual editing, ensuring that updated information is incorporated while preserving the integrity of the model.
Panacea: Pareto Alignment via Preference Adaptation for LLMs
Feb 03, 2024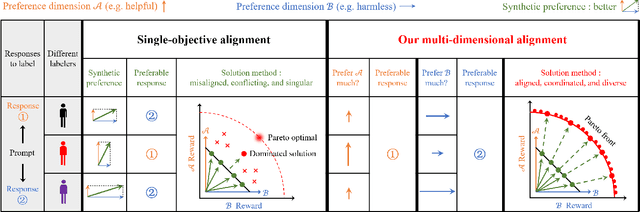



Current methods for large language model alignment typically use scalar human preference labels. However, this convention tends to oversimplify the multi-dimensional and heterogeneous nature of human preferences, leading to reduced expressivity and even misalignment. This paper presents Panacea, an innovative approach that reframes alignment as a multi-dimensional preference optimization problem. Panacea trains a single model capable of adapting online and Pareto-optimally to diverse sets of preferences without the need for further tuning. A major challenge here is using a low-dimensional preference vector to guide the model's behavior, despite it being governed by an overwhelmingly large number of parameters. To address this, Panacea is designed to use singular value decomposition (SVD)-based low-rank adaptation, which allows the preference vector to be simply injected online as singular values. Theoretically, we prove that Panacea recovers the entire Pareto front with common loss aggregation methods under mild conditions. Moreover, our experiments demonstrate, for the first time, the feasibility of aligning a single LLM to represent a spectrum of human preferences through various optimization methods. Our work marks a step forward in effectively and efficiently aligning models to diverse and intricate human preferences in a controllable and Pareto-optimal manner.
CivRealm: A Learning and Reasoning Odyssey in Civilization for Decision-Making Agents
Jan 19, 2024



The generalization of decision-making agents encompasses two fundamental elements: learning from past experiences and reasoning in novel contexts. However, the predominant emphasis in most interactive environments is on learning, often at the expense of complexity in reasoning. In this paper, we introduce CivRealm, an environment inspired by the Civilization game. Civilization's profound alignment with human history and society necessitates sophisticated learning, while its ever-changing situations demand strong reasoning to generalize. Particularly, CivRealm sets up an imperfect-information general-sum game with a changing number of players; it presents a plethora of complex features, challenging the agent to deal with open-ended stochastic environments that require diplomacy and negotiation skills. Within CivRealm, we provide interfaces for two typical agent types: tensor-based agents that focus on learning, and language-based agents that emphasize reasoning. To catalyze further research, we present initial results for both paradigms. The canonical RL-based agents exhibit reasonable performance in mini-games, whereas both RL- and LLM-based agents struggle to make substantial progress in the full game. Overall, CivRealm stands as a unique learning and reasoning challenge for decision-making agents. The code is available at https://github.com/bigai-ai/civrealm.
Safety-Gymnasium: A Unified Safe Reinforcement Learning Benchmark
Oct 19, 2023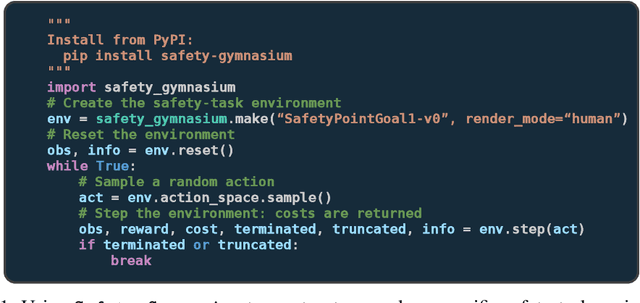
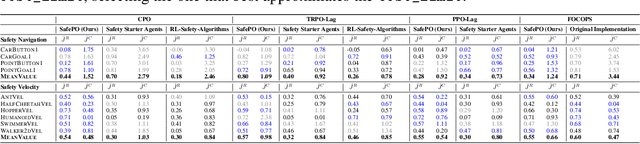

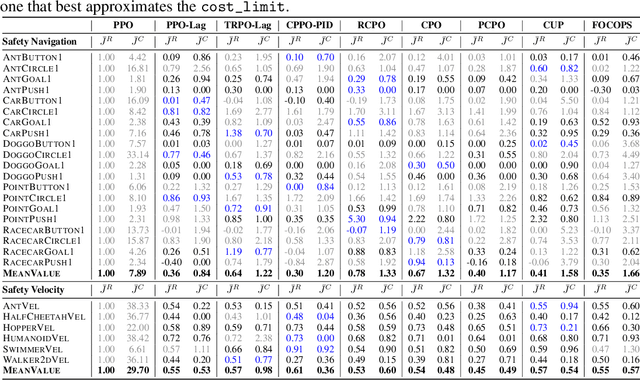
Artificial intelligence (AI) systems possess significant potential to drive societal progress. However, their deployment often faces obstacles due to substantial safety concerns. Safe reinforcement learning (SafeRL) emerges as a solution to optimize policies while simultaneously adhering to multiple constraints, thereby addressing the challenge of integrating reinforcement learning in safety-critical scenarios. In this paper, we present an environment suite called Safety-Gymnasium, which encompasses safety-critical tasks in both single and multi-agent scenarios, accepting vector and vision-only input. Additionally, we offer a library of algorithms named Safe Policy Optimization (SafePO), comprising 16 state-of-the-art SafeRL algorithms. This comprehensive library can serve as a validation tool for the research community. By introducing this benchmark, we aim to facilitate the evaluation and comparison of safety performance, thus fostering the development of reinforcement learning for safer, more reliable, and responsible real-world applications. The website of this project can be accessed at https://sites.google.com/view/safety-gymnasium.
Maximum Entropy Heterogeneous-Agent Mirror Learning
Jun 19, 2023Multi-agent reinforcement learning (MARL) has been shown effective for cooperative games in recent years. However, existing state-of-the-art methods face challenges related to sample inefficiency, brittleness regarding hyperparameters, and the risk of converging to a suboptimal Nash Equilibrium. To resolve these issues, in this paper, we propose a novel theoretical framework, named Maximum Entropy Heterogeneous-Agent Mirror Learning (MEHAML), that leverages the maximum entropy principle to design maximum entropy MARL actor-critic algorithms. We prove that algorithms derived from the MEHAML framework enjoy the desired properties of the monotonic improvement of the joint maximum entropy objective and the convergence to quantal response equilibrium (QRE). The practicality of MEHAML is demonstrated by developing a MEHAML extension of the widely used RL algorithm, HASAC (for soft actor-critic), which shows significant improvements in exploration and robustness on three challenging benchmarks: Multi-Agent MuJoCo, StarCraftII, and Google Research Football. Our results show that HASAC outperforms strong baseline methods such as HATD3, HAPPO, QMIX, and MAPPO, thereby establishing the new state of the art. See our project page at https://sites.google.com/view/mehaml.
Heterogeneous-Agent Reinforcement Learning
Apr 19, 2023



The necessity for cooperation among intelligent machines has popularised cooperative multi-agent reinforcement learning (MARL) in AI research. However, many research endeavours heavily rely on parameter sharing among agents, which confines them to only homogeneous-agent setting and leads to training instability and lack of convergence guarantees. To achieve effective cooperation in the general heterogeneous-agent setting, we propose Heterogeneous-Agent Reinforcement Learning (HARL) algorithms that resolve the aforementioned issues. Central to our findings are the multi-agent advantage decomposition lemma and the sequential update scheme. Based on these, we develop the provably correct Heterogeneous-Agent Trust Region Learning (HATRL) that is free of parameter-sharing constraint, and derive HATRPO and HAPPO by tractable approximations. Furthermore, we discover a novel framework named Heterogeneous-Agent Mirror Learning (HAML), which strengthens theoretical guarantees for HATRPO and HAPPO and provides a general template for cooperative MARL algorithmic designs. We prove that all algorithms derived from HAML inherently enjoy monotonic improvement of joint reward and convergence to Nash Equilibrium. As its natural outcome, HAML validates more novel algorithms in addition to HATRPO and HAPPO, including HAA2C, HADDPG, and HATD3, which consistently outperform their existing MA-counterparts. We comprehensively test HARL algorithms on six challenging benchmarks and demonstrate their superior effectiveness and stability for coordinating heterogeneous agents compared to strong baselines such as MAPPO and QMIX.
FormLM: Recommending Creation Ideas for Online Forms by Modelling Semantic and Structural Information
Nov 10, 2022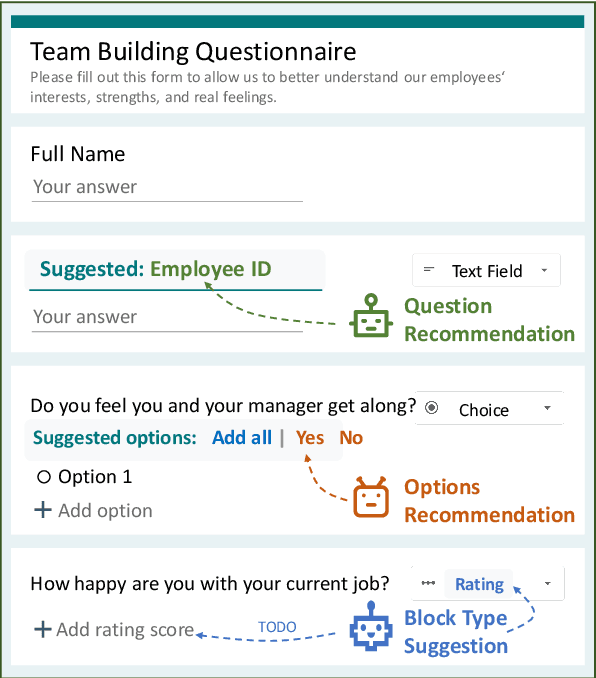
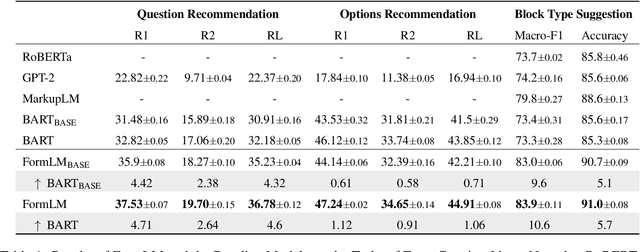
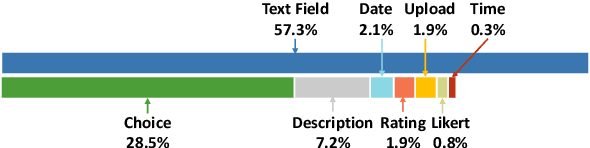
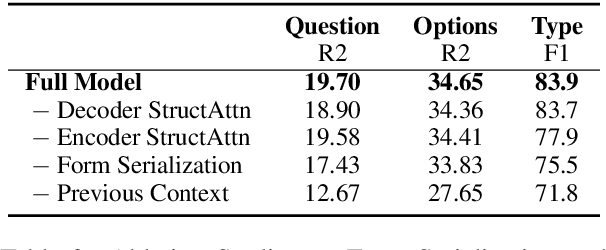
Online forms are widely used to collect data from human and have a multi-billion market. Many software products provide online services for creating semi-structured forms where questions and descriptions are organized by pre-defined structures. However, the design and creation process of forms is still tedious and requires expert knowledge. To assist form designers, in this work we present FormLM to model online forms (by enhancing pre-trained language model with form structural information) and recommend form creation ideas (including question / options recommendations and block type suggestion). For model training and evaluation, we collect the first public online form dataset with 62K online forms. Experiment results show that FormLM significantly outperforms general-purpose language models on all tasks, with an improvement by 4.71 on Question Recommendation and 10.6 on Block Type Suggestion in terms of ROUGE-1 and Macro-F1, respectively.