 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-Gymnasium: A Unified Safe Reinforcement Learning Benchmark
Paper and Code
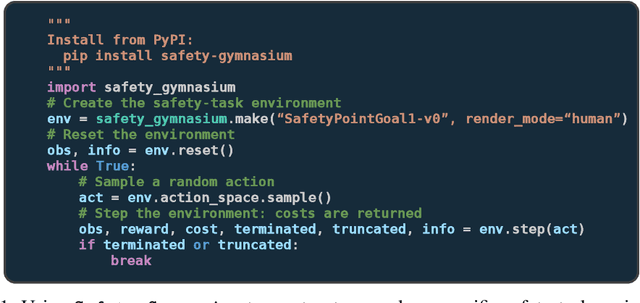
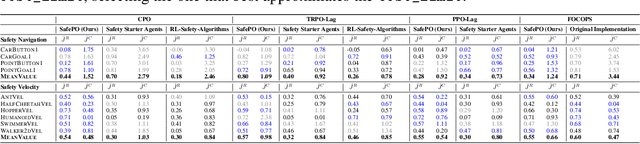

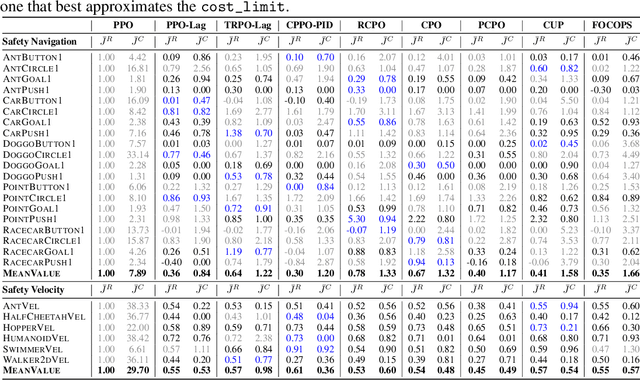
Artificial intelligence (AI) systems possess significant potential to drive societal progress. However, their deployment often faces obstacles due to substantial safety concerns. Safe reinforcement learning (SafeRL) emerges as a solution to optimize policies while simultaneously adhering to multiple constraints, thereby addressing the challenge of integrating reinforcement learning in safety-critical scenarios. In this paper, we present an environment suite called Safety-Gymnasium, which encompasses safety-critical tasks in both single and multi-agent scenarios, accepting vector and vision-only input. Additionally, we offer a library of algorithms named Safe Policy Optimization (SafePO), comprising 16 state-of-the-art SafeRL algorithms. This comprehensive library can serve as a validation tool for the research community. By introducing this benchmark, we aim to facilitate the evaluation and comparison of safety performance, thus fostering the development of reinforcement learning for safer, more reliable, and responsible real-world applications. The website of this project can be accessed at https://sites.google.com/view/safety-gymnasium.