 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptFlow: Adaptive Workflow Optimization via Meta-Learning
Aug 11, 2025Recent advances in large language models (LLMs) have sparked growing interest in agentic workflows, which are structured sequences of LLM invocations intended to solve complex tasks. However, existing approaches often rely on static templates or manually designed workflows, which limit adaptability to diverse tasks and hinder scalability. We propose AdaptFlow, a natural language-based meta-learning framework inspired by model-agnostic meta-learning (MAML). AdaptFlow learns a generalizable workflow initialization that enables rapid subtask-level adaptation. It employs a bi-level optimization scheme: the inner loop refines the workflow for a specific subtask using LLM-generated feedback, while the outer loop updates the shared initialization to perform well across tasks. This setup allows AdaptFlow to generalize effectively to unseen tasks by adapting the initialized workflow through language-guided modifications. Evaluated across question answering, code generation, and mathematical reasoning benchmarks, AdaptFlow consistently outperforms both manually crafted and automatically searched baselines, achieving state-of-the-art results with strong generalization across tasks and models. The source code and data are available at https://github.com/microsoft/DKI_LLM/tree/AdaptFlow/AdaptFlow.
A Survey on Vision-Language-Action Models: An Action Tokenization Perspective
Jul 02, 2025The remarkable advancements of vision and language foundation models in multimodal understanding, reasoning, and generation has sparked growing efforts to extend such intelligence to the physical world, fueling the flourishing of vision-language-action (VLA) models. Despite seemingly diverse approaches, we observe that current VLA models can be unified under a single framework: vision and language inputs are processed by a series of VLA modules, producing a chain of \textit{action tokens} that progressively encode more grounded and actionable information, ultimately generating executable actions. We further determine that the primary design choice distinguishing VLA models lies in how action tokens are formulated, which can be categorized into language description, code, affordance, trajectory, goal state, latent representation, raw action, and reasoning. However, there remains a lack of comprehensive understanding regarding action tokens, significantly impeding effective VLA development and obscuring future directions. Therefore, this survey aims to categorize and interpret existing VLA research through the lens of action tokenization, distill the strengths and limitations of each token type, and identify areas for improvement. Through this systematic review and analysis, we offer a synthesized outlook on the broader evolution of VLA models, highlight underexplored yet promising directions, and contribute guidance for future research, hoping to bring the field closer to general-purpose intelligence.
EuroCon: Benchmarking Parliament Deliberation for Political Consensus Finding
May 26, 2025Achieving political consensus is crucial yet challenging for the effective functioning of social governance. However, although frontier AI systems represented by large language models (LLMs) have developed rapidly in recent years, their capabilities on this scope are still understudied. In this paper, we introduce EuroCon, a novel benchmark constructed from 2,225 high-quality deliberation records of the European Parliament over 13 years, ranging from 2009 to 2022, to evaluate the ability of LLMs to reach political consensus among divergent party positions across diverse parliament settings. Specifically, EuroCon incorporates four factors to build each simulated parliament setting: specific political issues, political goals, participating parties, and power structures based on seat distribution. We also develop an evaluation framework for EuroCon to simulate real voting outcomes in different parliament settings, assessing whether LLM-generated resolutions meet predefined political goals. Our experimental results demonstrate that even state-of-the-art models remain undersatisfied with complex tasks like passing resolutions by a two-thirds majority and addressing security issues, while revealing some common strategies LLMs use to find consensus under different power structures, such as prioritizing the stance of the dominant party, highlighting EuroCon's promise as an effective platform for studying LLMs' ability to find political consensus.
Retrieval Dexterity: Efficient Object Retrieval in Clutters with Dexterous Hand
Feb 26, 2025Retrieving objects buried beneath multiple objects is not only challenging but also time-consuming. Performing manipulation in such environments presents significant difficulty due to complex contact relationships. Existing methods typically address this task by sequentially grasping and removing each occluding object, resulting in lengthy execution times and requiring impractical grasping capabilities for every occluding object. In this paper, we present a dexterous arm-hand system for efficient object retrieval in multi-object stacked environments. Our approach leverages large-scale parallel reinforcement learning within diverse and carefully designed cluttered environments to train policies. These policies demonstrate emergent manipulation skills (e.g., pushing, stirring, and poking) that efficiently clear occluding objects to expose sufficient surface area of the target object. We conduct extensive evaluations across a set of over 10 household objects in diverse clutter configurations, demonstrating superior retrieval performance and efficiency for both trained and unseen objects. Furthermore, we successfully transfer the learned policies to a real-world dexterous multi-fingered robot system, validating their practical applicability in real-world scenarios. Videos can be found on our project website https://ChangWinde.github.io/RetrDex.
Amulet: ReAlignment During Test Time for Personalized Preference Adaptation of LLMs
Feb 26, 2025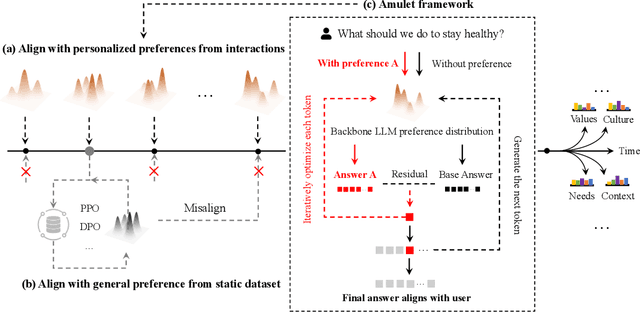
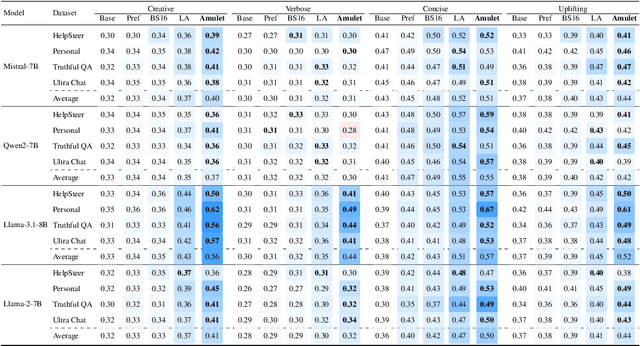
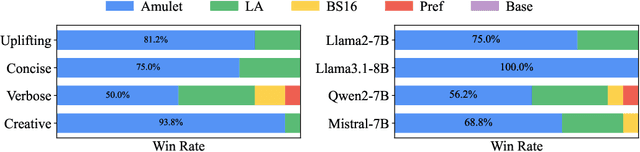

How to align large language models (LLMs) with user preferences from a static general dataset has been frequently studied. However, user preferences are usually personalized, changing, and diverse regarding culture, values, or time. This leads to the problem that the actual user preferences often do not coincide with those trained by the model developers in the practical use of LLMs. Since we cannot collect enough data and retrain for every demand, researching efficient real-time preference adaptation methods based on the backbone LLMs during test time is important. To this end, we introduce Amulet, a novel, training-free framework that formulates the decoding process of every token as a separate online learning problem with the guidance of simple user-provided prompts, thus enabling real-time optimization to satisfy users' personalized preferences. To reduce the computational cost brought by this optimization process for each token, we additionally provide a closed-form solution for each iteration step of the optimization process, thereby reducing the computational time cost to a negligible level. The detailed experimental results demonstrate that Amulet can achieve significant performance improvements in rich settings with combinations of different LLMs, datasets, and user preferences, while maintaining acceptable computational efficiency.
GRAIT: Gradient-Driven Refusal-Aware Instruction Tuning for Effective Hallucination Mitigation
Feb 09, 2025Refusal-Aware Instruction Tuning (RAIT) aims to enhance Large Language Models (LLMs) by improving their ability to refuse responses to questions beyond their knowledge, thereby reducing hallucinations and improving reliability. Effective RAIT must address two key challenges: firstly, effectively reject unknown questions to minimize hallucinations; secondly, avoid over-refusal to ensure questions that can be correctly answered are not rejected, thereby maintain the helpfulness of LLM outputs. In this paper, we address the two challenges by deriving insightful observations from the gradient-based perspective, and proposing the Gradient-driven Refusal Aware Instruction Tuning Framework GRAIT: (1) employs gradient-driven sample selection to effectively minimize hallucinations and (2) introduces an adaptive weighting mechanism during fine-tuning to reduce the risk of over-refusal, achieving the balance between accurate refusals and maintaining useful responses. Experimental evaluations on open-ended and multiple-choice question answering tasks demonstrate that GRAIT significantly outperforms existing RAIT methods in the overall performance. The source code and data will be available at https://github.com/opendatalab/GRAIT .
$β$-DQN: Improving Deep Q-Learning By Evolving the Behavior
Jan 01, 2025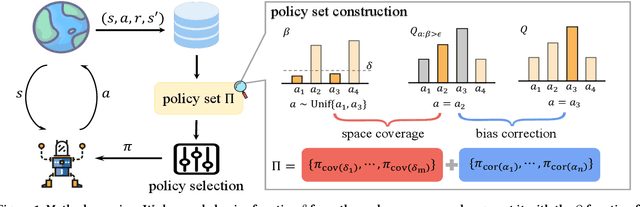
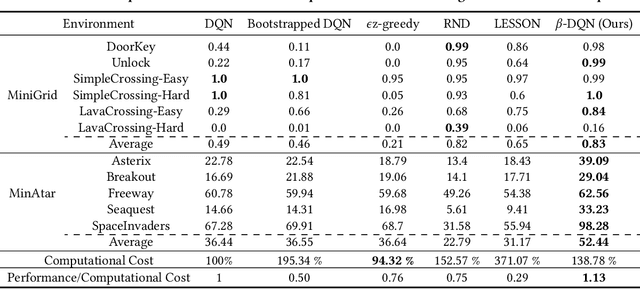
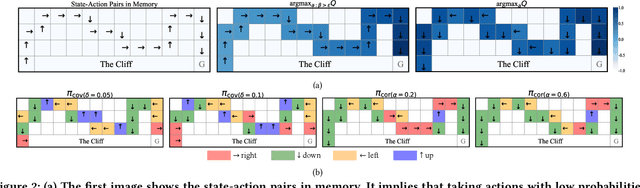

While many sophisticated exploration methods have been proposed, their lack of generality and high computational cost often lead researchers to favor simpler methods like $\epsilon$-greedy. Motivated by this, we introduce $\beta$-DQN, a simple and efficient exploration method that augments the standard DQN with a behavior function $\beta$. This function estimates the probability that each action has been taken at each state. By leveraging $\beta$, we generate a population of diverse policies that balance exploration between state-action coverage and overestimation bias correction. An adaptive meta-controller is designed to select an effective policy for each episode, enabling flexible and explainable exploration. $\beta$-DQN is straightforward to implement and adds minimal computational overhead to the standard DQN. Experiments on both simple and challenging exploration domains show that $\beta$-DQN outperforms existing baseline methods across a wide range of tasks, providing an effective solution for improving exploration in deep reinforcement learning.
RAT: Adversarial Attacks on Deep Reinforcement Agents for Targeted Behaviors
Dec 14, 2024Evaluating deep reinforcement learning (DRL) agents against targeted behavior attacks is critical for assessing their robustness. These attacks aim to manipulate the victim into specific behaviors that align with the attacker's objectives, often bypassing traditional reward-based defenses. Prior methods have primarily focused on reducing cumulative rewards; however, rewards are typically too generic to capture complex safety requirements effectively. As a result, focusing solely on reward reduction can lead to suboptimal attack strategies, particularly in safety-critical scenarios where more precise behavior manipulation is needed. To address these challenges, we propose RAT, a method designed for universal, targeted behavior attacks. RAT trains an intention policy that is explicitly aligned with human preferences, serving as a precise behavioral target for the adversary. Concurrently, an adversary manipulates the victim's policy to follow this target behavior. To enhance the effectiveness of these attacks, RAT dynamically adjusts the state occupancy measure within the replay buffer, allowing for more controlled and effective behavior manipulation. Our empirical results on robotic simulation tasks demonstrate that RAT outperforms existing adversarial attack algorithms in inducing specific behaviors. Additionally, RAT shows promise in improving agent robustness, leading to more resilient policies. We further validate RAT by guiding Decision Transformer agents to adopt behaviors aligned with human preferences in various MuJoCo tasks, demonstrating its effectiveness across diverse tasks.
Efficient Model-agnostic Alignment via Bayesian Persuasion
May 29, 2024



With recent advancements in large language models (LLMs), alignment has emerged as an effective technique for keeping LLMs consensus with human intent. Current methods primarily involve direct training through Supervised Fine-tuning (SFT) or Reinforcement Learning from Human Feedback (RLHF), both of which require substantial computational resources and extensive ground truth data. This paper explores an efficient method for aligning black-box large models using smaller models, introducing a model-agnostic and lightweight Bayesian Persuasion Alignment framework. We formalize this problem as an optimization of the signaling strategy from the small model's perspective. In the persuasion process, the small model (Advisor) observes the information item (i.e., state) and persuades large models (Receiver) to elicit improved responses. The Receiver then generates a response based on the input, the signal from the Advisor, and its updated belief about the information item. Through training using our framework, we demonstrate that the Advisor can significantly enhance the performance of various Receivers across a range of tasks. We theoretically analyze our persuasion framework and provide an upper bound on the Advisor's regret, confirming its effectiveness in learning the optimal signaling strategy. Our Empirical results demonstrates that GPT-2 can significantly improve the performance of various models, achieving an average enhancement of 16.1% in mathematical reasoning ability and 13.7% in code generation. We hope our work can provide an initial step toward rethinking the alignment framework from the Bayesian Persuasion perspective.
Incentive Compatibility for AI Alignment in Sociotechnical Systems: Positions and Prospects
Mar 01, 2024

The burgeoning integration of artificial intelligence (AI) into human society brings forth significant implications for societal governance and safety. While considerable strides have been made in addressing AI alignment challenges, existing methodologies primarily focus on technical facets, often neglecting the intricate sociotechnical nature of AI systems, which can lead to a misalignment between the development and deployment contexts. To this end, we posit a new problem worth exploring: Incentive Compatibility Sociotechnical Alignment Problem (ICSAP). We hope this can call for more researchers to explore how to leverage the principles of Incentive Compatibility (IC) from game theory to bridge the gap between technical and societal components to maintain AI consensus with human societies in different contexts. We further discuss three classical game problems for achieving IC: mechanism design, contract theory, and Bayesian persuasion, in addressing the perspectives, potentials, and challenges of solving ICSAP, and provide preliminary implementation conceptions.