 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptFlow: Adaptive Workflow Optimization via Meta-Learning
Aug 11, 2025Recent advances in large language models (LLMs) have sparked growing interest in agentic workflows, which are structured sequences of LLM invocations intended to solve complex tasks. However, existing approaches often rely on static templates or manually designed workflows, which limit adaptability to diverse tasks and hinder scalability. We propose AdaptFlow, a natural language-based meta-learning framework inspired by model-agnostic meta-learning (MAML). AdaptFlow learns a generalizable workflow initialization that enables rapid subtask-level adaptation. It employs a bi-level optimization scheme: the inner loop refines the workflow for a specific subtask using LLM-generated feedback, while the outer loop updates the shared initialization to perform well across tasks. This setup allows AdaptFlow to generalize effectively to unseen tasks by adapting the initialized workflow through language-guided modifications. Evaluated across question answering, code generation, and mathematical reasoning benchmarks, AdaptFlow consistently outperforms both manually crafted and automatically searched baselines, achieving state-of-the-art results with strong generalization across tasks and models. The source code and data are available at https://github.com/microsoft/DKI_LLM/tree/AdaptFlow/AdaptFlow.
Adaptive Multi-Objective Bayesian Optimization for Capacity Planning of Hybrid Heat Sources in Electric-Heat Coupling Systems of Cold Regions
Feb 13, 2025The traditional heat-load generation pattern of combined heat and power generators has become a problem leading to renewable energy source (RES) power curtailment in cold regions, motivating the proposal of a planning model for alternative heat sources. The model aims to identify non-dominant capacity allocation schemes for heat pumps, thermal energy storage, electric boilers, and combined storage heaters to construct a Pareto front, considering both economic and sustainable objectives. The integration of various heat sources from both generation and consumption sides enhances flexibility in utilization. The study introduces a novel optimization algorithm, the adaptive multi-objective Bayesian optimization (AMBO). Compared to other widely used multi-objective optimization algorithms, AMBO eliminates predefined parameters that may introduce subjectivity from planners. Beyond the algorithm, the proposed model incorporates a noise term to account for inevitable simulation deviations, enabling the identification of better-performing planning results that meet the unique requirements of cold regions. What's more, the characteristics of electric-thermal coupling scenarios are captured and reflected in the operation simulation model to make sure the simulation is close to reality. Numerical simulation verifies the superiority of the proposed approach in generating a more diverse and evenly distributed Pareto front in a sample-efficient manner, providing comprehensive and objective planning choices.
Application of Vision-Language Model to Pedestrians Behavior and Scene Understanding in Autonomous Driving
Jan 12, 2025



Autonomous driving (AD) has experienced significant improvements in recent years and achieved promising 3D detection, classification, and localization results. However, many challenges remain, e.g. semantic understanding of pedestrians' behaviors, and downstream handling for pedestrian interactions. Recent studies in applications of Large Language Models (LLM) and Vision-Language Models (VLM) have achieved promising results in scene understanding and high-level maneuver planning in diverse traffic scenarios. However, deploying the billion-parameter LLMs to vehicles requires significant computation and memory resources. In this paper, we analyzed effective knowledge distillation of semantic labels to smaller Vision networks, which can be used for the semantic representation of complex scenes for downstream decision-making for planning and control.
Utilizing Large Language Models for Information Extraction from Real Estate Transactions
Apr 28, 2024Real estate sales contracts contain crucial information for property transactions, but manual extraction of data can be time-consuming and error-prone. This paper explores the application of large language models, specifically transformer-based architectures, for automated information extraction from real estate contracts. We discuss challenges, techniques, and future directions in leveraging these models to improve efficiency and accuracy in real estate contract analysis.
A Survey for Foundation Models in Autonomous Driving
Feb 02, 2024The advent of foundation models has revolutionized the fields of natural language processing and computer vision, paving the way for their application in autonomous driving (AD). This survey presents a comprehensive review of more than 40 research papers, demonstrating the role of foundation models in enhancing AD. Large language models contribute to planning and simulation in AD, particularly through their proficiency in reasoning, code generation and translation. In parallel, vision foundation models are increasingly adapted for critical tasks such as 3D object detection and tracking, as well as creating realistic driving scenarios for simulation and testing. Multi-modal foundation models, integrating diverse inputs, exhibit exceptional visual understanding and spatial reasoning, crucial for end-to-end AD. This survey not only provides a structured taxonomy, categorizing foundation models based on their modalities and functionalities within the AD domain but also delves into the methods employed in current research. It identifies the gaps between existing foundation models and cutting-edge AD approaches, thereby charting future research directions and proposing a roadmap for bridging these gaps.
Understanding and Improving Recurrent Networks for Human Activity Recognition by Continuous Attention
Oct 07, 2018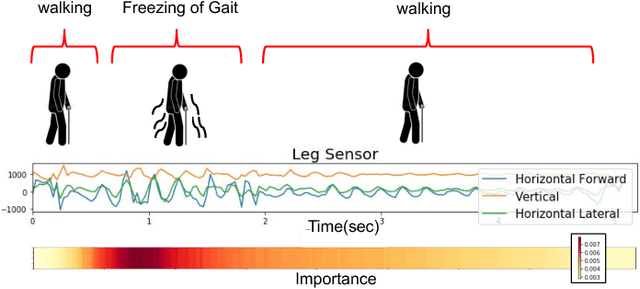
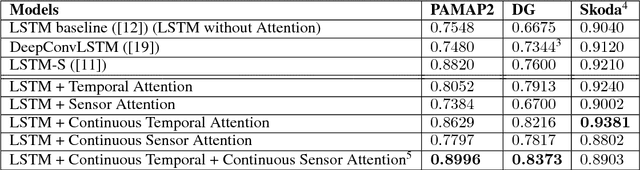
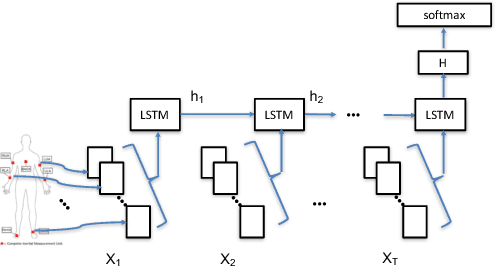
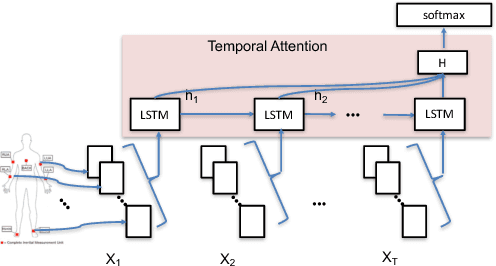
Deep neural networks, including recurrent networks, have been successfully applied to human activity recognition. Unfortunately, the final representation learned by recurrent networks might encode some noise (irrelevant signal components, unimportant sensor modalities, etc.). Besides, it is difficult to interpret the recurrent networks to gain insight into the models' behavior. To address these issues, we propose two attention models for human activity recognition: temporal attention and sensor attention. These two mechanisms adaptively focus on important signals and sensor modalities. To further improve the understandability and mean F1 score, we add continuity constraints, considering that continuous sensor signals are more robust than discrete ones. We evaluate the approaches on three datasets and obtain state-of-the-art results. Furthermore, qualitative analysis shows that the attention learned by the models agree well with human intuition.
* 8 pages. published in The International Symposium on Wearable Computers (ISWC) 2018