 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluence Diagram Bandits: Variational Thompson Sampling for Structured Bandit Problems
Jul 09, 2020

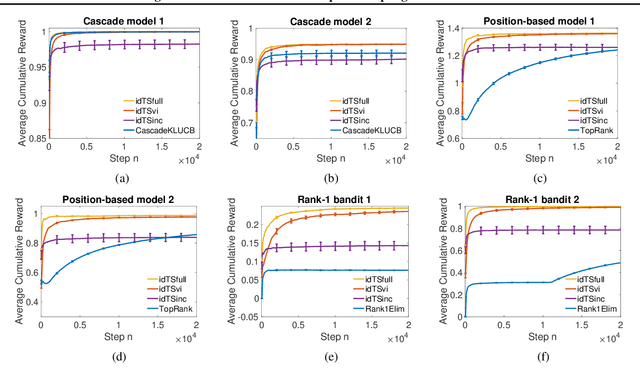
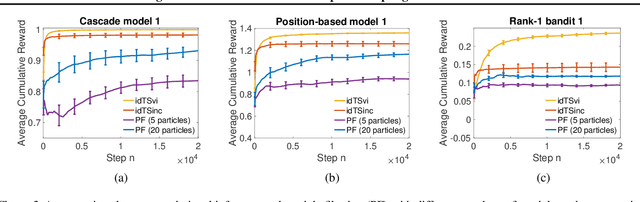
We propose a novel framework for structured bandits, which we call an influence diagram bandit. Our framework captures complex statistical dependencies between actions, latent variables, and observations; and thus unifies and extends many existing models, such as combinatorial semi-bandits, cascading bandits, and low-rank bandits. We develop novel online learning algorithms that learn to act efficiently in our models. The key idea is to track a structured posterior distribution of model parameters, either exactly or approximately. To act, we sample model parameters from their posterior and then use the structure of the influence diagram to find the most optimistic action under the sampled parameters. We empirically evaluate our algorithms in three structured bandit problems, and show that they perform as well as or better than problem-specific state-of-the-art baselines.
Customized Graph Embedding: Tailoring the Embedding Vector to a Specific Application
Nov 21, 2019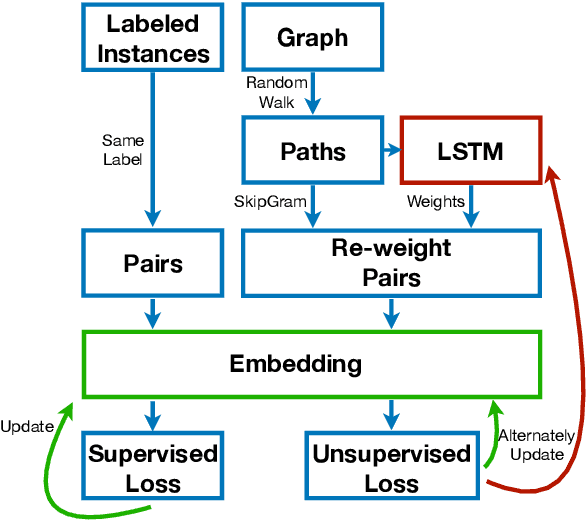
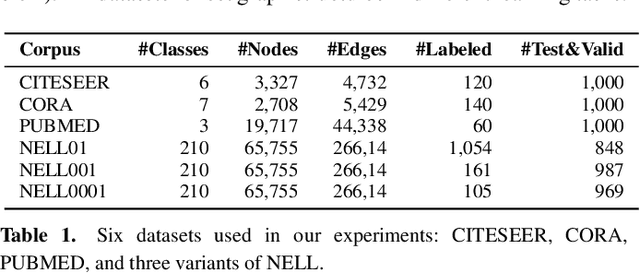
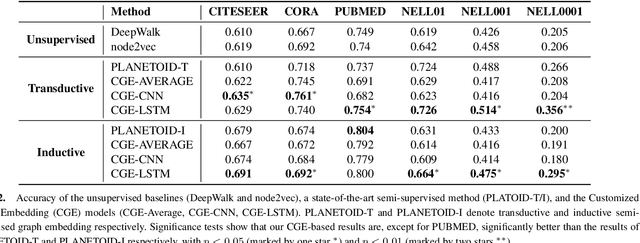
The graph is a natural representation of data in a variety of real-world applications, for example as a knowledge graph, a social network, or a biological network. To better leverage the information behind the data, the method of graph embedding is recently proposed and extensively studied. The traditional graph embedding method, while it provides an effective way to understand what is behind the graph data, is unfortunately sub-optimal in many cases. This is because its learning procedure is disconnected from the target application. In this paper, we propose a novel approach, Customized Graph Embedding (CGE), to tackle this problem. The CGE algorithm learns a customized vector representation of the graph by differentiating the varying importance of distinct graph paths. Experiments are carried out on a diverse set of node classification datasets and strong performance is demonstrated.
Adaptive Stress Testing: Finding Failure Events with Reinforcement Learning
Nov 06, 2018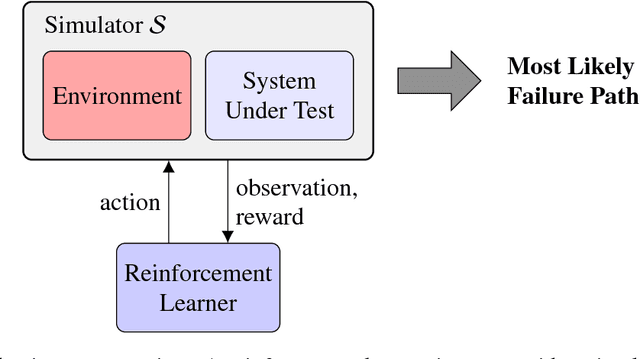
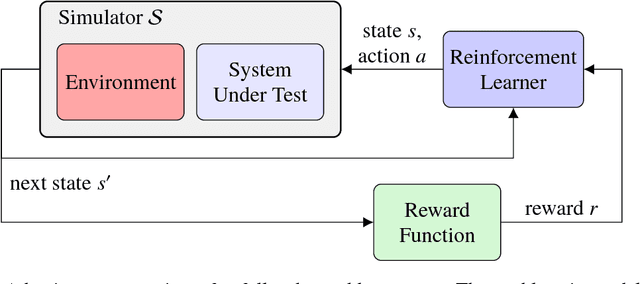
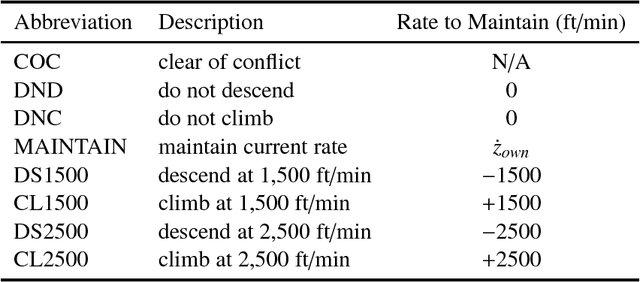
Finding the most likely path to a set of failure states is important to the analysis of safety-critical dynamic systems. While efficient solutions exist for certain classes of systems, a scalable general solution for stochastic, partially-observable, and continuous-valued systems remains challenging. Existing approaches in formal and simulation-based methods either cannot scale to large systems or are computationally inefficient. This paper presents adaptive stress testing (AST), a framework for searching a simulator for the most likely path to a failure event. We formulate the problem as a Markov decision process and use reinforcement learning to optimize it. The approach is simulation-based and does not require internal knowledge of the system. As a result, the approach is very suitable for black box testing of large systems. We present formulations for both systems where the state is fully-observable and partially-observable. In the latter case, we present a modified Monte Carlo tree search algorithm that only requires access to the pseudorandom number generator of the simulator to overcome partial observability. We also present an extension of the framework, called differential adaptive stress testing (DAST), that can be used to find failures that occur in one system but not in another. This type of differential analysis is useful in applications such as regression testing, where one is concerned with finding areas of relative weakness compared to a baseline. We demonstrate the effectiveness of the approach on an aircraft collision avoidance application, where we stress test a prototype aircraft collision avoidance system to find high-probability scenarios of near mid-air collisions.
Understanding and Improving Recurrent Networks for Human Activity Recognition by Continuous Attention
Oct 07, 2018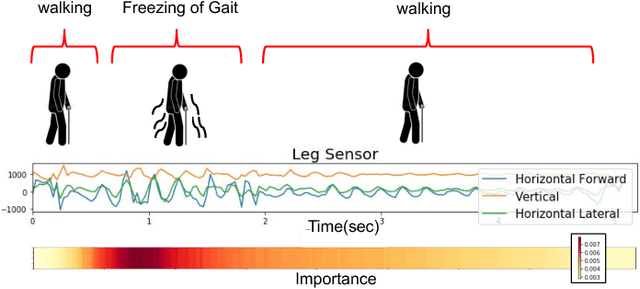
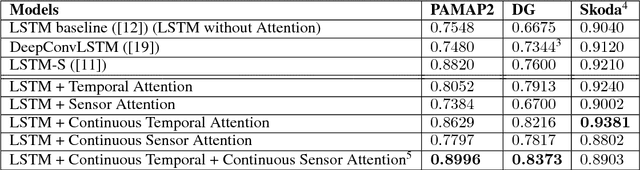
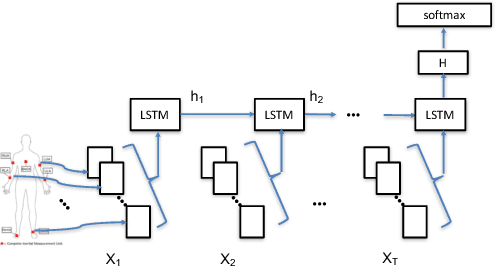
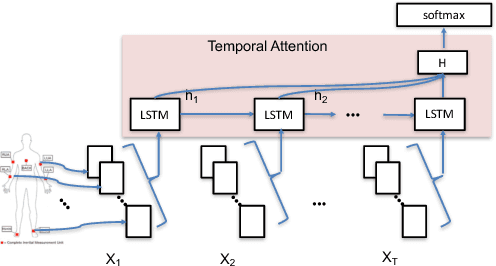
Deep neural networks, including recurrent networks, have been successfully applied to human activity recognition. Unfortunately, the final representation learned by recurrent networks might encode some noise (irrelevant signal components, unimportant sensor modalities, etc.). Besides, it is difficult to interpret the recurrent networks to gain insight into the models' behavior. To address these issues, we propose two attention models for human activity recognition: temporal attention and sensor attention. These two mechanisms adaptively focus on important signals and sensor modalities. To further improve the understandability and mean F1 score, we add continuity constraints, considering that continuous sensor signals are more robust than discrete ones. We evaluate the approaches on three datasets and obtain state-of-the-art results. Furthermore, qualitative analysis shows that the attention learned by the models agree well with human intuition.
* 8 pages. published in The International Symposium on Wearable Computers (ISWC) 2018
SpectralLeader: Online Spectral Learning for Single Topic Models
Apr 26, 2018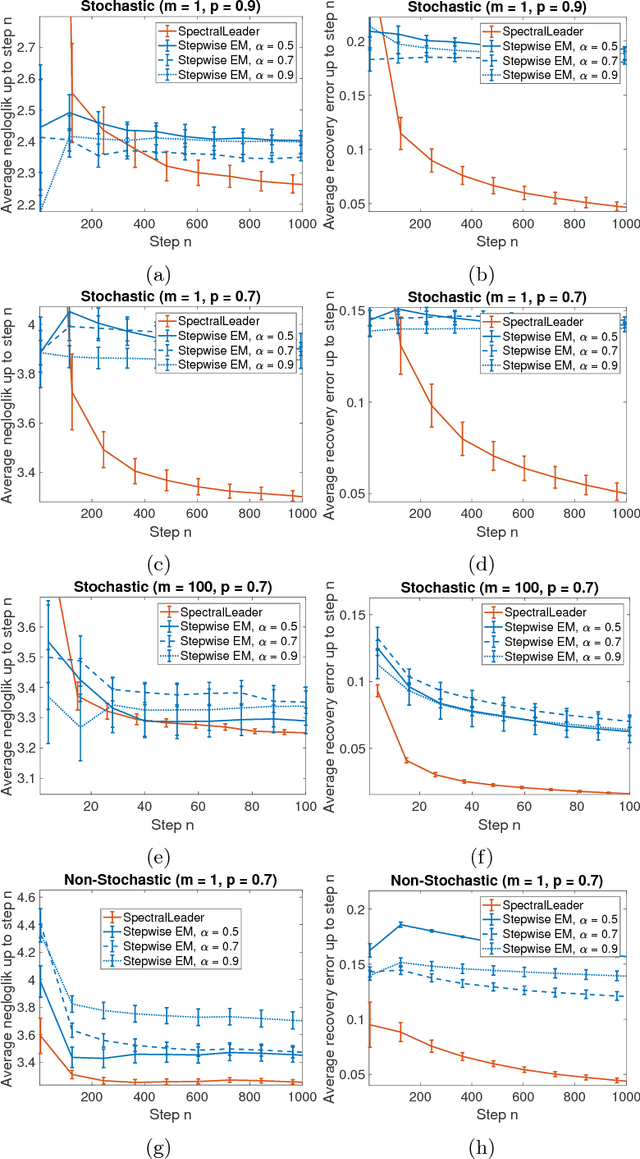

We study the problem of learning a latent variable model from a stream of data. Latent variable models are popular in practice because they can explain observed data in terms of unobserved concepts. These models have been traditionally studied in the offline setting. In the online setting, on the other hand, the online EM is arguably the most popular algorithm for learning latent variable models. Although the online EM is computationally efficient, it typically converges to a local optimum. In this work, we develop a new online learning algorithm for latent variable models, which we call SpectralLeader. SpectralLeader always converges to the global optimum, and we derive a sublinear upper bound on its $n$-step regret in the bag-of-words model. In both synthetic and real-world experiments, we show that SpectralLeader performs similarly to or better than the online EM with tuned hyper-parameters.
Interpretable Categorization of Heterogeneous Time Series Data
Jan 26, 2018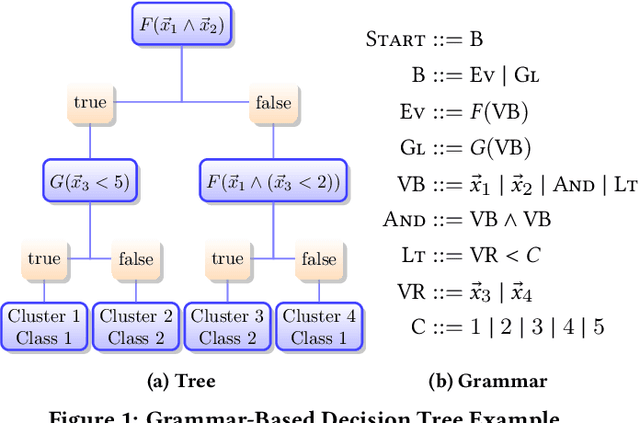
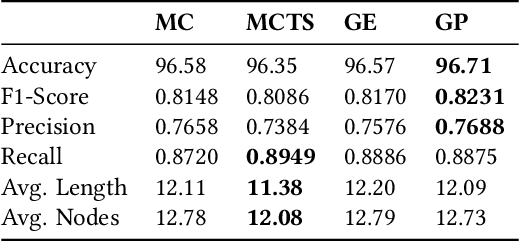
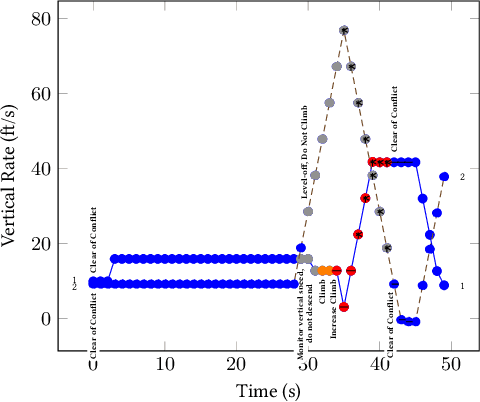
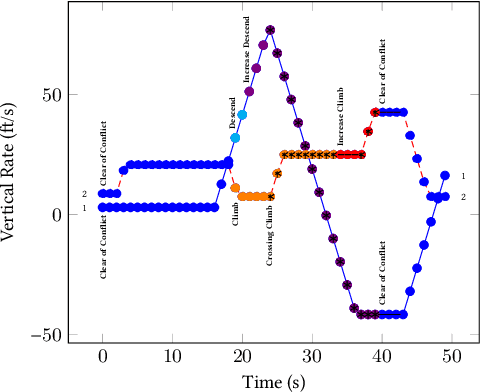
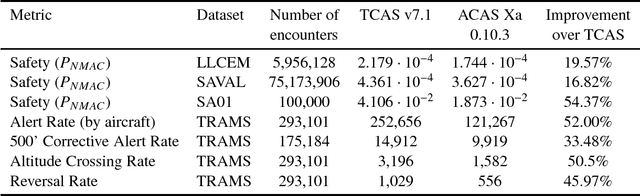
Understanding heterogeneous multivariate time series data is important in many applications ranging from smart homes to aviation. Learning models of heterogeneous multivariate time series that are also human-interpretable is challenging and not adequately addressed by the existing literature. We propose grammar-based decision trees (GBDTs) and an algorithm for learning them. GBDTs extend decision trees with a grammar framework. Logical expressions derived from a context-free grammar are used for branching in place of simple thresholds on attributes. The added expressivity enables support for a wide range of data types while retaining the interpretability of decision trees. In particular, when a grammar based on temporal logic is used, we show that GBDTs can be used for the interpretable classi cation of high-dimensional and heterogeneous time series data. Furthermore, we show how GBDTs can also be used for categorization, which is a combination of clustering and generating interpretable explanations for each cluster. We apply GBDTs to analyze the classic Australian Sign Language dataset as well as data on near mid-air collisions (NMACs). The NMAC data comes from aircraft simulations used in the development of the next-generation Airborne Collision Avoidance System (ACAS X).
Semi-Supervised Convolutional Neural Networks for Human Activity Recognition
Jan 22, 2018
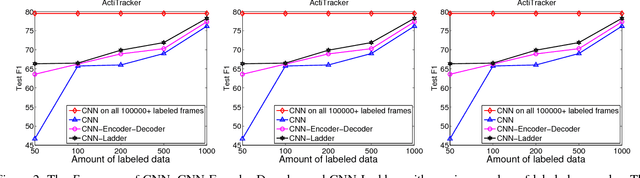
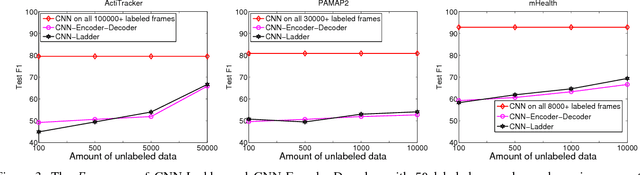
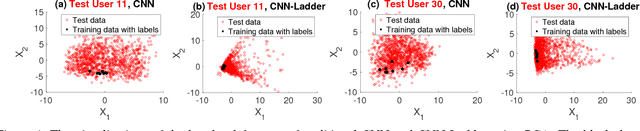
Labeled data used for training activity recognition classifiers are usually limited in terms of size and diversity. Thus, the learned model may not generalize well when used in real-world use cases. Semi-supervised learning augments labeled examples with unlabeled examples, often resulting in improved performance. However, the semi-supervised methods studied in the activity recognition literatures assume that feature engineering is already done. In this paper, we lift this assumption and present two semi-supervised methods based on convolutional neural networks (CNNs) to learn discriminative hidden features. Our semi-supervised CNNs learn from both labeled and unlabeled data while also performing feature learning on raw sensor data. In experiments on three real world datasets, we show that our CNNs outperform supervised methods and traditional semi-supervised learning methods by up to 18% in mean F1-score (Fm).
Customized Nonlinear Bandits for Online Response Selection in Neural Conversation Models
Nov 22, 2017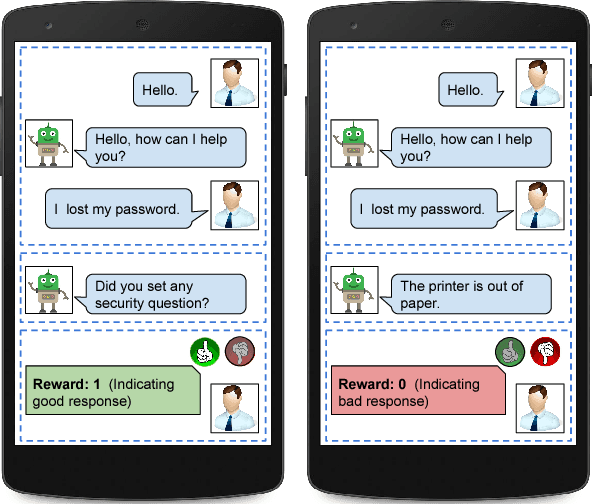

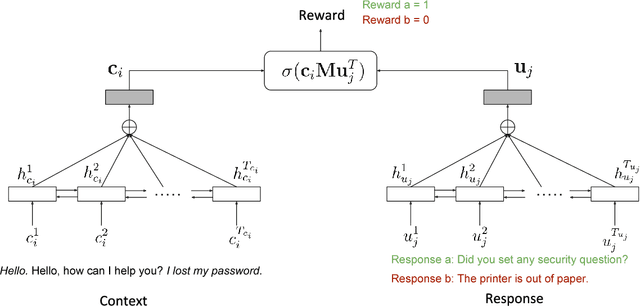

Dialog response selection is an important step towards natural response generation in conversational agents. Existing work on neural conversational models mainly focuses on offline supervised learning using a large set of context-response pairs. In this paper, we focus on online learning of response selection in retrieval-based dialog systems. We propose a contextual multi-armed bandit model with a nonlinear reward function that uses distributed representation of text for online response selection. A bidirectional LSTM is used to produce the distributed representations of dialog context and responses, which serve as the input to a contextual bandit. In learning the bandit, we propose a customized Thompson sampling method that is applied to a polynomial feature space in approximating the reward. Experimental results on the Ubuntu Dialogue Corpus demonstrate significant performance gains of the proposed method over conventional linear contextual bandits. Moreover, we report encouraging response selection performance of the proposed neural bandit model using the Recall@k metric for a small set of online training samples.